diff --git a/lab2/Part1_MNIST.ipynb b/lab2/Part1_MNIST.ipynb
index 68ea633f..0af58634 100644
--- a/lab2/Part1_MNIST.ipynb
+++ b/lab2/Part1_MNIST.ipynb
@@ -10,9 +10,9 @@
" \n",
"  \n",
" Visit MIT Deep Learning \n",
" Visit MIT Deep Learning | \n",
- " \n",
+ " | \n",
"  Run in Google Colab Run in Google Colab | \n",
- " \n",
+ " | \n",
"  View Source on GitHub View Source on GitHub | \n",
"\n",
"\n",
@@ -27,8 +27,8 @@
},
"outputs": [],
"source": [
- "# Copyright 2023 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "# \n",
+ "# Copyright 2024 MIT Introduction to Deep Learning. All Rights Reserved.\n",
+ "#\n",
"# Licensed under the MIT License. You may not use this file except in compliance\n",
"# with the License. Use and/or modification of this code outside of MIT Introduction\n",
"# to Deep Learning must reference:\n",
@@ -62,31 +62,67 @@
"outputs": [],
"source": [
"# Import Tensorflow 2.0\n",
- "%tensorflow_version 2.x\n",
- "import tensorflow as tf \n",
+ "import tensorflow as tf\n",
"\n",
- "!pip install mitdeeplearning\n",
+ "# MIT introduction to deep learning package\n",
+ "!pip install mitdeeplearning --quiet\n",
"import mitdeeplearning as mdl\n",
"\n",
- "#Import Comet\n",
- "!pip install comet_ml\n",
- "import comet_ml\n",
- "comet_ml.init(project_name=\"6.s191lab2_part1_NN\")\n",
- "comet_model_1 = comet_ml.Experiment()\n",
- "\n",
+ "# other packages\n",
"import matplotlib.pyplot as plt\n",
"import numpy as np\n",
"import random\n",
"from tqdm import tqdm"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nCpHDxX1bzyZ"
+ },
+ "source": [
+ "We'll also install Comet. If you followed the instructions from Lab 1, you should have your Comet account set up. Enter your API key below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GSR_PAqjbzyZ"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install comet_ml > /dev/null 2>&1\n",
+ "import comet_ml\n",
+ "# TODO: ENTER YOUR API KEY HERE!!\n",
+ "COMET_API_KEY = \"\"\n",
+ "\n",
+ "# Check that we are using a GPU, if not switch runtimes\n",
+ "# using Runtime > Change Runtime Type > GPU\n",
+ "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
+ "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# start a first comet experiment for the first part of the lab\n",
+ "comet_ml.init(project_name=\"6S191lab2_part1_NN\")\n",
+ "comet_model_1 = comet_ml.Experiment()"
+ ],
+ "metadata": {
+ "id": "wGPDtVxvTtPk"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
{
"cell_type": "markdown",
"metadata": {
"id": "HKjrdUtX_N8J"
},
"source": [
- "## 1.1 MNIST dataset \n",
+ "## 1.1 MNIST dataset\n",
"\n",
"Let's download and load the dataset and display a few random samples from it:"
]
@@ -113,7 +149,7 @@
"id": "5ZtUqOqePsRD"
},
"source": [
- "Our training set is made up of 28x28 grayscale images of handwritten digits. \n",
+ "Our training set is made up of 28x28 grayscale images of handwritten digits.\n",
"\n",
"Let's visualize what some of these images and their corresponding training labels look like."
]
@@ -136,7 +172,8 @@
" plt.grid(False)\n",
" image_ind = random_inds[i]\n",
" plt.imshow(np.squeeze(train_images[image_ind]), cmap=plt.cm.binary)\n",
- " plt.xlabel(train_labels[image_ind])"
+ " plt.xlabel(train_labels[image_ind])\n",
+ "comet_model_1.log_figure(figure=plt)"
]
},
{
@@ -159,7 +196,7 @@
},
"source": [
"### Fully connected neural network architecture\n",
- "To define the architecture of this first fully connected neural network, we'll once again use the Keras API and define the model using the [`Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential) class. Note how we first use a [`Flatten`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Flatten) layer, which flattens the input so that it can be fed into the model. \n",
+ "To define the architecture of this first fully connected neural network, we'll once again use the Keras API and define the model using the [`Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential) class. Note how we first use a [`Flatten`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Flatten) layer, which flattens the input so that it can be fed into the model.\n",
"\n",
"In this next block, you'll define the fully connected layers of this simple work."
]
@@ -181,8 +218,8 @@
" tf.keras.layers.Dense(128, activation= '''TODO'''),\n",
"\n",
" # '''TODO: Define the second Dense layer to output the classification probabilities'''\n",
- " '''TODO: Dense layer to output classification probabilities'''\n",
- " \n",
+ " [TODO Dense layer to output classification probabilities]\n",
+ "\n",
" ])\n",
" return fc_model\n",
"\n",
@@ -208,7 +245,7 @@
"\n",
"After the pixels are flattened, the network consists of a sequence of two `tf.keras.layers.Dense` layers. These are fully-connected neural layers. The first `Dense` layer has 128 nodes (or neurons). The second (and last) layer (which you've defined!) should return an array of probability scores that sum to 1. Each node contains a score that indicates the probability that the current image belongs to one of the handwritten digit classes.\n",
"\n",
- "That defines our fully connected model! "
+ "That defines our fully connected model!"
]
},
{
@@ -229,7 +266,7 @@
"\n",
"We'll start out by using a stochastic gradient descent (SGD) optimizer initialized with a learning rate of 0.1. Since we are performing a categorical classification task, we'll want to use the [cross entropy loss](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/sparse_categorical_crossentropy).\n",
"\n",
- "You'll want to experiment with both the choice of optimizer and learning rate and evaluate how these affect the accuracy of the trained model. "
+ "You'll want to experiment with both the choice of optimizer and learning rate and evaluate how these affect the accuracy of the trained model."
]
},
{
@@ -243,7 +280,7 @@
"'''TODO: Experiment with different optimizers and learning rates. How do these affect\n",
" the accuracy of the trained model? Which optimizers and/or learning rates yield\n",
" the best performance?'''\n",
- "model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=1e-1), \n",
+ "model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=1e-1),\n",
" loss='sparse_categorical_crossentropy',\n",
" metrics=['accuracy'])"
]
@@ -256,7 +293,7 @@
"source": [
"### Train the model\n",
"\n",
- "We're now ready to train our model, which will involve feeding the training data (`train_images` and `train_labels`) into the model, and then asking it to learn the associations between images and labels. We'll also need to define the batch size and the number of epochs, or iterations over the MNIST dataset, to use during training. \n",
+ "We're now ready to train our model, which will involve feeding the training data (`train_images` and `train_labels`) into the model, and then asking it to learn the associations between images and labels. We'll also need to define the batch size and the number of epochs, or iterations over the MNIST dataset, to use during training.\n",
"\n",
"In Lab 1, we saw how we can use `GradientTape` to optimize losses and train models with stochastic gradient descent. After defining the model settings in the `compile` step, we can also accomplish training by calling the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) method on an instance of the `Model` class. We will use this to train our fully connected model\n"
]
@@ -294,7 +331,7 @@
"source": [
"### Evaluate accuracy on the test dataset\n",
"\n",
- "Now that we've trained the model, we can ask it to make predictions about a test set that it hasn't seen before. In this example, the `test_images` array comprises our test dataset. To evaluate accuracy, we can check to see if the model's predictions match the labels from the `test_labels` array. \n",
+ "Now that we've trained the model, we can ask it to make predictions about a test set that it hasn't seen before. In this example, the `test_images` array comprises our test dataset. To evaluate accuracy, we can check to see if the model's predictions match the labels from the `test_labels` array.\n",
"\n",
"Use the [`evaluate`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#evaluate) method to evaluate the model on the test dataset!"
]
@@ -319,7 +356,7 @@
"id": "yWfgsmVXCaXG"
},
"source": [
- "You may observe that the accuracy on the test dataset is a little lower than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*, when a machine learning model performs worse on new data than on its training data. \n",
+ "You may observe that the accuracy on the test dataset is a little lower than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*, when a machine learning model performs worse on new data than on its training data.\n",
"\n",
"What is the highest accuracy you can achieve with this first fully connected model? Since the handwritten digit classification task is pretty straightforward, you may be wondering how we can do better...\n",
"\n",
@@ -369,28 +406,28 @@
" cnn_model = tf.keras.Sequential([\n",
"\n",
" # TODO: Define the first convolutional layer\n",
- " tf.keras.layers.Conv2D('''TODO'''), \n",
+ " tf.keras.layers.Conv2D('''TODO''')\n",
"\n",
" # TODO: Define the first max pooling layer\n",
- " tf.keras.layers.MaxPool2D('''TODO'''),\n",
+ " tf.keras.layers.MaxPool2D('''TODO''')\n",
"\n",
" # TODO: Define the second convolutional layer\n",
- " tf.keras.layers.Conv2D('''TODO'''),\n",
+ " tf.keras.layers.Conv2D('''TODO''')\n",
"\n",
" # TODO: Define the second max pooling layer\n",
- " tf.keras.layers.MaxPool2D('''TODO'''),\n",
+ " tf.keras.layers.MaxPool2D('''TODO''')\n",
"\n",
" tf.keras.layers.Flatten(),\n",
" tf.keras.layers.Dense(128, activation=tf.nn.relu),\n",
"\n",
- " # TODO: Define the last Dense layer to output the classification \n",
+ " # TODO: Define the last Dense layer to output the classification\n",
" # probabilities. Pay attention to the activation needed a probability\n",
" # output\n",
- " '''TODO: Dense layer to output classification probabilities'''\n",
+ " [TODO Dense layer to output classification probabilities]\n",
" ])\n",
- " \n",
+ "\n",
" return cnn_model\n",
- " \n",
+ "\n",
"cnn_model = build_cnn_model()\n",
"# Initialize the model by passing some data through\n",
"cnn_model.predict(train_images[[0]])\n",
@@ -443,7 +480,7 @@
"source": [
"'''TODO: Use model.fit to train the CNN model, with the same batch_size and number of epochs previously used.'''\n",
"cnn_model.fit('''TODO''')\n",
- "comet_model_2.end() "
+ "# comet_model_2.end() ## uncomment this line to end the comet experiment"
]
},
{
@@ -475,7 +512,9 @@
"id": "2rvEgK82Glv9"
},
"source": [
- "What is the highest accuracy you're able to achieve using the CNN model, and how does the accuracy of the CNN model compare to the accuracy of the simple fully connected network? What optimizers and learning rates seem to be optimal for training the CNN model? "
+ "What is the highest accuracy you're able to achieve using the CNN model, and how does the accuracy of the CNN model compare to the accuracy of the simple fully connected network? What optimizers and learning rates seem to be optimal for training the CNN model?\n",
+ "\n",
+ "Feel free to click the Comet links to investigate the training/accuracy curves for your model."
]
},
{
@@ -526,7 +565,7 @@
"id": "-hw1hgeSCaXN"
},
"source": [
- "As you can see, a prediction is an array of 10 numbers. Recall that the output of our model is a probability distribution over the 10 digit classes. Thus, these numbers describe the model's \"confidence\" that the image corresponds to each of the 10 different digits. \n",
+ "As you can see, a prediction is an array of 10 numbers. Recall that the output of our model is a probability distribution over the 10 digit classes. Thus, these numbers describe the model's \"confidence\" that the image corresponds to each of the 10 different digits.\n",
"\n",
"Let's look at the digit that has the highest confidence for the first image in the test dataset:"
]
@@ -624,7 +663,7 @@
" plt.subplot(num_rows, 2*num_cols, 2*i+2)\n",
" mdl.lab2.plot_value_prediction(i, predictions, test_labels)\n",
"comet_model_2.log_figure(figure=plt)\n",
- "comet_model_2.end()"
+ "comet_model_2.end()\n"
]
},
{
@@ -635,7 +674,7 @@
"source": [
"## 1.4 Training the model 2.0\n",
"\n",
- "Earlier in the lab, we used the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) function call to train the model. This function is quite high-level and intuitive, which is really useful for simpler models. As you may be able to tell, this function abstracts away many details in the training call, and we have less control over training model, which could be useful in other contexts. \n",
+ "Earlier in the lab, we used the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) function call to train the model. This function is quite high-level and intuitive, which is really useful for simpler models. As you may be able to tell, this function abstracts away many details in the training call, and we have less control over training model, which could be useful in other contexts.\n",
"\n",
"As an alternative to this, we can use the [`tf.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape) class to record differentiation operations during training, and then call the [`tf.GradientTape.gradient`](https://www.tensorflow.org/api_docs/python/tf/GradientTape#gradient) function to actually compute the gradients. You may recall seeing this in Lab 1 Part 1, but let's take another look at this here.\n",
"\n",
@@ -675,6 +714,8 @@
"\n",
" #'''TODO: compute the categorical cross entropy loss\n",
" loss_value = tf.keras.backend.sparse_categorical_crossentropy('''TODO''', '''TODO''') # TODO\n",
+ "\n",
+ " # log the loss to comet\n",
" comet_model_3.log_metric(\"loss\", loss_value.numpy().mean(), step=idx)\n",
"\n",
" loss_history.append(loss_value.numpy().mean()) # append the loss to the loss_history record\n",
@@ -682,7 +723,7 @@
"\n",
" # Backpropagation\n",
" '''TODO: Use the tape to compute the gradient against all parameters in the CNN model.\n",
- " Use cnn_model.trainable_variables to access these parameters.''' \n",
+ " Use cnn_model.trainable_variables to access these parameters.'''\n",
" grads = # TODO\n",
" optimizer.apply_gradients(zip(grads, cnn_model.trainable_variables))\n",
"\n",
@@ -697,7 +738,7 @@
},
"source": [
"## 1.5 Conclusion\n",
- "In this part of the lab, you had the chance to play with different MNIST classifiers with different architectures (fully-connected layers only, CNN), and experiment with how different hyperparameters affect accuracy (learning rate, etc.). The next part of the lab explores another application of CNNs, facial detection, and some drawbacks of AI systems in real world applications, like issues of bias. "
+ "In this part of the lab, you had the chance to play with different MNIST classifiers with different architectures (fully-connected layers only, CNN), and experiment with how different hyperparameters affect accuracy (learning rate, etc.). The next part of the lab explores another application of CNNs, facial detection, and some drawbacks of AI systems in real world applications, like issues of bias."
]
}
],
@@ -707,14 +748,26 @@
"collapsed_sections": [
"Xmf_JRJa_N8C"
],
- "name": "Part1_MNIST.ipynb",
+ "name": "Part1_MNIST_Solution.ipynb",
"provenance": []
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.6"
}
},
"nbformat": 4,
"nbformat_minor": 0
-}
+}
\ No newline at end of file
diff --git a/lab2/Part2_FaceDetection.ipynb b/lab2/Part2_Debiasing.ipynb
similarity index 50%
rename from lab2/Part2_FaceDetection.ipynb
rename to lab2/Part2_Debiasing.ipynb
index 62e1b490..5946daec 100644
--- a/lab2/Part2_FaceDetection.ipynb
+++ b/lab2/Part2_Debiasing.ipynb
@@ -1,7 +1,22 @@
{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "provenance": [],
+ "collapsed_sections": [
+ "Ag_e7xtTzT1W",
+ "NDj7KBaW8Asz"
+ ]
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ },
+ "accelerator": "GPU"
+ },
"cells": [
{
- "attachments": {},
"cell_type": "markdown",
"metadata": {
"id": "Ag_e7xtTzT1W"
@@ -11,9 +26,9 @@
" \n",
" \n",
" Visit MIT Deep Learning | \n",
- " \n",
+ " | \n",
" Run in Google Colab | \n",
- " \n",
+ " | \n",
" View Source on GitHub | \n",
"\n",
"\n",
@@ -22,22 +37,22 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "rNbf1pRlSDby"
},
- "outputs": [],
"source": [
- "# Copyright 2023 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "# \n",
+ "# Copyright 2024 MIT 6.S191 Introduction to Deep Learning. All Rights Reserved.\n",
+ "#\n",
"# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
+ "# with the License. Use and/or modification of this code outside of 6.S191 must\n",
+ "# reference:\n",
"#\n",
- "# © MIT Introduction to Deep Learning\n",
+ "# © MIT 6.S191: Introduction to Deep Learning\n",
"# http://introtodeeplearning.com\n",
"#"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -47,36 +62,57 @@
"source": [
"# Laboratory 2: Computer Vision\n",
"\n",
- "# Part 2: Diagnosing Bias in Facial Detection Systems\n",
+ "# Part 2: Debiasing Facial Detection Systems\n",
"\n",
- "In this lab, we'll explore a prominent aspect of applied deep learning for computer vision: facial detection. \n",
+ "In the second portion of the lab, we'll explore two prominent aspects of applied deep learning: facial detection and algorithmic bias.\n",
"\n",
- "Consider the task of facial detection: given an image, is it an image of a face? This seemingly simple -- but extremely important and pervasive -- task is subject to significant amounts of algorithmic bias among select demographics, as [seminal studies](https://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf) have shown.\n",
+ "Deploying fair, unbiased AI systems is critical to their long-term acceptance. Consider the task of facial detection: given an image, is it an image of a face? This seemingly simple, but extremely important, task is subject to significant amounts of algorithmic bias among select demographics.\n",
"\n",
- "Deploying fair, unbiased AI systems is critical to their long-term acceptance. In this lab, we will build computer vision models for facial detection. We will extend beyond that to build a model to **uncover and diagnose** the biases and issues that exist with standard facial detection models. To do this, we will build a semi-supervised variational autoencoder (SS-VAE) that learns the *latent distribution* of features underlying face image datasets in order to [uncover hidden biases](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf).\n",
+ "In this lab, we'll investigate [one recently published approach](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf) to addressing algorithmic bias. We'll build a facial detection model that learns the *latent variables* underlying face image datasets and uses this to adaptively re-sample the training data, thus mitigating any biases that may be present in order to train a *debiased* model.\n",
"\n",
- "Our work here will set the foundation for the next lab, where we'll build automated tools to mitigate the underlying issues of bias and uncertainty in facial detection."
+ "\n",
+ "Run the next code block for a short video from Google that explores how and why it's important to consider bias when thinking about machine learning:"
]
},
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "XQh5HZfbupFF"
+ },
+ "source": [
+ "import IPython\n",
+ "IPython.display.YouTubeVideo('59bMh59JQDo')"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
{
"cell_type": "markdown",
"metadata": {
"id": "3Ezfc6Yv6IhI"
},
"source": [
- "Let's get started by installing the relevant dependencies:"
+ "Let's get started by installing the relevant dependencies.\n",
+ "\n",
+ "We will be using Comet ML to track our model development and training runs.\n",
+ "\n",
+ "1. Sign up for a Comet account: [HERE](https://www.comet.com/signup?utm_source=mit_dl&utm_medium=partner&utm_content=github)\n",
+ "2. This will generate a personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable `COMET_API_KEY` below.\n",
+ "\n"
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "E46sWVKK6LP9"
},
- "outputs": [],
"source": [
+ "!pip install comet_ml --quiet\n",
+ "import comet_ml\n",
+ "# TODO: ENTER YOUR API KEY HERE!! instructions above\n",
+ "COMET_API_KEY = \"\"\n",
+ "\n",
"# Import Tensorflow 2.0\n",
- "%tensorflow_version 2.x\n",
"import tensorflow as tf\n",
"\n",
"import IPython\n",
@@ -85,16 +121,17 @@
"import numpy as np\n",
"from tqdm import tqdm\n",
"\n",
- "# Download and import the MIT Introduction to Deep Learning package\n",
- "!pip install mitdeeplearning\n",
+ "# Download and import the MIT 6.S191 package\n",
+ "!pip install mitdeeplearning --quiet\n",
"import mitdeeplearning as mdl\n",
"\n",
- "# Import Comet\n",
- "!pip install comet_ml\n",
- "import comet_ml\n",
- "comet_ml.init(project_name=\"6.s191lab2_part2_CNN\")\n",
- "comet_model_1 = comet_ml.Experiment()"
- ]
+ "# Check that we are using a GPU, if not switch runtimes\n",
+ "# using Runtime > Change Runtime Type > GPU\n",
+ "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
+ "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -104,29 +141,28 @@
"source": [
"## 2.1 Datasets\n",
"\n",
- "In order to train our facial detection models, we will need a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces). We will use these data to train our models to classify images as either faces or not faces.\n",
+ "We'll be using three datasets in this lab. In order to train our facial detection models, we'll need a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces). We'll use these data to train our models to classify images as either faces or not faces. Finally, we'll need a test dataset of face images. Since we're concerned about the potential *bias* of our learned models against certain demographics, it's important that the test dataset we use has equal representation across the demographics or features of interest. In this lab, we'll consider skin tone and gender.\n",
"\n",
- "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale dataset (over 200K images) of celebrity faces. \n",
- "2. **Negative training data**: [ImageNet](http://www.image-net.org/). A large-scale dataset with many images across many different categories. We will take negative examples from a variety of non-human categories.\n",
- "\n",
- "We will evaluate trained models on an independent test dataset of face images to diagnose potential issues with *bias, fairness, and confidence*.\n",
+ "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale (over 200K images) of celebrity faces. \n",
+ "2. **Negative training data**: [ImageNet](http://www.image-net.org/). Many images across many different categories. We'll take negative examples from a variety of non-human categories.\n",
+ "[Fitzpatrick Scale](https://en.wikipedia.org/wiki/Fitzpatrick_scale) skin type classification system, with each image labeled as \"Lighter'' or \"Darker''.\n",
"\n",
"Let's begin by importing these datasets. We've written a class that does a bit of data pre-processing to import the training data in a usable format."
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "RWXaaIWy6jVw"
},
- "outputs": [],
"source": [
"# Get the training data: both images from CelebA and ImageNet\n",
"path_to_training_data = tf.keras.utils.get_file('train_face.h5', 'https://www.dropbox.com/s/hlz8atheyozp1yx/train_face.h5?dl=1')\n",
"# Instantiate a TrainingDatasetLoader using the downloaded dataset\n",
"loader = mdl.lab2.TrainingDatasetLoader(path_to_training_data)"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -139,15 +175,15 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "DjPSjZZ_bGqe"
},
- "outputs": [],
"source": [
"number_of_training_examples = loader.get_train_size()\n",
"(images, labels) = loader.get_batch(100)"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -160,33 +196,31 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
- "cellView": "form",
"id": "Jg17jzwtbxDA"
},
- "outputs": [],
"source": [
- "#@title Change the sliders to look at positive and negative training examples! { run: \"auto\" }\n",
- "\n",
"### Examining the CelebA training dataset ###\n",
"\n",
+ "#@title Change the sliders to look at positive and negative training examples! { run: \"auto\" }\n",
+ "\n",
"face_images = images[np.where(labels==1)[0]]\n",
"not_face_images = images[np.where(labels==0)[0]]\n",
"\n",
- "idx_face = 19 #@param {type:\"slider\", min:0, max:50, step:1}\n",
- "idx_not_face = 8 #@param {type:\"slider\", min:0, max:50, step:1}\n",
+ "idx_face = 23 #@param {type:\"slider\", min:0, max:50, step:1}\n",
+ "idx_not_face = 9 #@param {type:\"slider\", min:0, max:50, step:1}\n",
"\n",
- "plt.figure(figsize=(8,4))\n",
+ "plt.figure(figsize=(5,5))\n",
"plt.subplot(1, 2, 1)\n",
"plt.imshow(face_images[idx_face])\n",
"plt.title(\"Face\"); plt.grid(False)\n",
"\n",
"plt.subplot(1, 2, 2)\n",
"plt.imshow(not_face_images[idx_not_face])\n",
- "plt.title(\"Not Face\"); plt.grid(False)\n",
- "comet_model_1.log_figure(figure=plt)"
- ]
+ "plt.title(\"Not Face\"); plt.grid(False)"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -196,9 +230,9 @@
"source": [
"### Thinking about bias\n",
"\n",
- "We will be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluate their accuracy as well as inspect and diagnose their hidden flaws. Our goal is to identify any potential issues and biases that may exist with the trained facial detection classifiers, and then diagnose what those issues and biases are.\n",
+ "Remember we'll be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluating their accuracy by testing them on an independent test dataset. Our goal is to build a model that trains on CelebA *and* achieves high classification accuracy on the the test dataset across all demographics, and to thus show that this model does not suffer from any hidden bias.\n",
"\n",
- "What exactly do we mean when we say a classifier is biased? In order to formalize this, we'll need to think about [*latent variables*](https://en.wikipedia.org/wiki/Latent_variable), variables that define a dataset but are not strictly observed. As defined in the generative modeling lecture, we use the term *latent space* to refer to the probability distributions of the aforementioned latent variables. Putting these ideas together, we consider a classifier *biased* if its classification decision changes after it sees some additional latent features or variables. This definition of bias will be helpful to keep in mind throughout the rest of the lab."
+ "What exactly do we mean when we say a classifier is biased? In order to formalize this, we'll need to think about [*latent variables*](https://en.wikipedia.org/wiki/Latent_variable), variables that define a dataset but are not strictly observed. As defined in the generative modeling lecture, we'll use the term *latent space* to refer to the probability distributions of the aforementioned latent variables. Putting these ideas together, we consider a classifier *biased* if its classification decision changes after it sees some additional latent features. This notion of bias may be helpful to keep in mind throughout the rest of the lab."
]
},
{
@@ -207,22 +241,20 @@
"id": "AIFDvU4w8OIH"
},
"source": [
- "## 2.2 CNN for facial detection \n",
+ "## 2.2 CNN for facial detection\n",
"\n",
- "First, we will define and train a baseline CNN on the facial detection task of classifying whether a given image is a face, or is not a face. We will then evaluate its accuracy. The CNN model has a relatively standard architecture consisting of a series of convolutional layers with batch normalization followed by two fully connected layers to flatten the convolution output and generate a class prediction. \n",
+ "First, we'll define and train a CNN on the facial classification task, and evaluate its accuracy. Later, we'll evaluate the performance of our debiased models against this baseline CNN. The CNN model has a relatively standard architecture consisting of a series of convolutional layers with batch normalization followed by two fully connected layers to flatten the convolution output and generate a class prediction.\n",
"\n",
"### Define and train the CNN model\n",
"\n",
- "Like we did in the first part of the lab, we will define our CNN model, and then train on the CelebA and ImageNet datasets using the `tf.GradientTape` class and the `tf.GradientTape.gradient` method."
+ "Like we did in the first part of the lab, we'll define our CNN model, and then train on the CelebA and ImageNet datasets using the `tf.GradientTape` class and the `tf.GradientTape.gradient` method."
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "82EVTAAW7B_X"
},
- "outputs": [],
"source": [
"### Define the CNN model ###\n",
"\n",
@@ -235,10 +267,10 @@
" Flatten = tf.keras.layers.Flatten\n",
" Dense = functools.partial(tf.keras.layers.Dense, activation='relu')\n",
"\n",
- " model = tf.keras.Sequential([ \n",
+ " model = tf.keras.Sequential([\n",
" Conv2D(filters=1*n_filters, kernel_size=5, strides=2),\n",
" BatchNormalization(),\n",
- " \n",
+ "\n",
" Conv2D(filters=2*n_filters, kernel_size=5, strides=2),\n",
" BatchNormalization(),\n",
"\n",
@@ -255,7 +287,9 @@
" return model\n",
"\n",
"standard_classifier = make_standard_classifier()"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -268,20 +302,48 @@
},
{
"cell_type": "code",
+ "source": [
+ "### Create a Comet experiment to track our training run ###\n",
+ "def create_experiment(project_name, params):\n",
+ " # end any prior experiments\n",
+ " if 'experiment' in locals():\n",
+ " experiment.end()\n",
+ "\n",
+ " # initiate the comet experiment for tracking\n",
+ " experiment = comet_ml.Experiment(\n",
+ " api_key=COMET_API_KEY,\n",
+ " project_name=project_name)\n",
+ " # log our hyperparameters, defined above, to the experiment\n",
+ " for param, value in params.items():\n",
+ " experiment.log_parameter(param, value)\n",
+ " experiment.flush()\n",
+ "\n",
+ " return experiment\n"
+ ],
+ "metadata": {
+ "id": "mi-04SAfK6lm"
+ },
"execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
"metadata": {
"id": "eJlDGh1o31G1"
},
- "outputs": [],
"source": [
"### Train the standard CNN ###\n",
"\n",
"# Training hyperparameters\n",
- "batch_size = 32\n",
- "num_epochs = 2 # keep small to run faster\n",
- "learning_rate = 5e-4\n",
+ "params = dict(\n",
+ " batch_size = 32,\n",
+ " num_epochs = 2, # keep small to run faster\n",
+ " learning_rate = 5e-4,\n",
+ ")\n",
+ "\n",
+ "experiment = create_experiment(\"6S191_Lab2_Part2_CNN\", params)\n",
"\n",
- "optimizer = tf.keras.optimizers.Adam(learning_rate) # define our optimizer\n",
+ "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"]) # define our optimizer\n",
"loss_history = mdl.util.LossHistory(smoothing_factor=0.99) # to record loss evolution\n",
"plotter = mdl.util.PeriodicPlotter(sec=2, scale='semilogy')\n",
"if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
@@ -290,7 +352,7 @@
"def standard_train_step(x, y):\n",
" with tf.GradientTape() as tape:\n",
" # feed the images into the model\n",
- " logits = standard_classifier(x) \n",
+ " logits = standard_classifier(x)\n",
" # Compute the loss\n",
" loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=logits)\n",
"\n",
@@ -300,20 +362,22 @@
" return loss\n",
"\n",
"# The training loop!\n",
- "for epoch in range(num_epochs):\n",
- " for idx in tqdm(range(loader.get_train_size()//batch_size)):\n",
+ "step = 0\n",
+ "for epoch in range(params[\"num_epochs\"]):\n",
+ " for idx in tqdm(range(loader.get_train_size()//params[\"batch_size\"])):\n",
" # Grab a batch of training data and propagate through the network\n",
- " x, y = loader.get_batch(batch_size)\n",
+ " x, y = loader.get_batch(params[\"batch_size\"])\n",
" loss = standard_train_step(x, y)\n",
"\n",
- " comet_model_1.log_metric(\"loss\", loss.numpy().mean(), idx)\n",
" # Record the loss and plot the evolution of the loss as a function of training\n",
" loss_history.append(loss.numpy().mean())\n",
" plotter.plot(loss_history.get())\n",
"\n",
- "comet_model_1.log_figure(figure=plt)\n",
- "comet_model_1.end()"
- ]
+ " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
+ " step += 1"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -328,11 +392,9 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "35-PDgjdWk6_"
},
- "outputs": [],
"source": [
"### Evaluation of standard CNN ###\n",
"\n",
@@ -343,7 +405,9 @@
"acc_standard = tf.reduce_mean(tf.cast(tf.equal(batch_y, y_pred_standard), tf.float32))\n",
"\n",
"print(\"Standard CNN accuracy on (potentially biased) training set: {:.4f}\".format(acc_standard.numpy()))"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -351,25 +415,84 @@
"id": "Qu7R14KaEEvU"
},
"source": [
- "## 2.3 Diagnosing algorithmic bias\n",
- "\n",
- "CNNs like the one we just built are pervasive as the standard solution for facial detection pipelines implemented throughout society. Despite their pervasiveness, these models -- including those implemented by top tech companies -- suffer from tremendous amounts of algorithmic bias. The seminal work of [Buolamwini and Gebru](https://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf) provided an approach and benchmark dataset to evaluate facial analysis algorithms, revealing startling accuracy discrepancies across skin tone and gender demographics.\n",
- "\n",
- "In order to solve this problem and build fair and robust models, the first step is to determine the source of the problem. How can we determine the ***source*** of these accuracy discrepancies to identify and diagnose biases?\n",
- "\n",
- "### Naive approach\n",
- "\n",
- "A naive approach -- and one that is being adopted by many companies and organizations -- would be to annotate different subclasses (i.e., light-skinned females, males with hats, etc.) within the training data, and then evaluate classifier performance with respect to these groups.\n",
+ "We will also evaluate our networks on an independent test dataset containing faces that were not seen during training. For the test data, we'll look at the classification accuracy across four different demographics, based on the Fitzpatrick skin scale and sex-based labels: dark-skinned male, dark-skinned female, light-skinned male, and light-skinned female.\n",
"\n",
- "But this approach has two major disadvantages. First, it requires annotating massive amounts of data, which is not scalable. Second, it requires that we know what potential biases (e.g., race, gender, pose, occlusion, hats, glasses, etc.) to look for in the data. As a result, manual annotation may not capture all the different sources of bias and uncertainty that may exist.\n",
- "\n",
- "### Automatically uncovering hidden biases\n",
+ "Let's take a look at some sample faces in the test set."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "vfDD8ztGWk6x"
+ },
+ "source": [
+ "### Load test dataset and plot examples ###\n",
+ "\n",
+ "test_faces = mdl.lab2.get_test_faces()\n",
+ "keys = [\"Light Female\", \"Light Male\", \"Dark Female\", \"Dark Male\"]\n",
+ "for group, key in zip(test_faces,keys):\n",
+ " plt.figure(figsize=(5,5))\n",
+ " plt.imshow(np.hstack(group))\n",
+ " plt.title(key, fontsize=15)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "uo1z3cdbEUMM"
+ },
+ "source": [
+ "Now, let's evaluate the probability of each of these face demographics being classified as a face using the standard CNN classifier we've just trained."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "GI4O0Y1GAot9"
+ },
+ "source": [
+ "### Evaluate the standard CNN on the test data ###\n",
+ "\n",
+ "standard_classifier_logits = [standard_classifier(np.array(x, dtype=np.float32)) for x in test_faces]\n",
+ "standard_classifier_probs = tf.squeeze(tf.sigmoid(standard_classifier_logits))\n",
+ "\n",
+ "# Plot the prediction accuracies per demographic\n",
+ "xx = range(len(keys))\n",
+ "yy = standard_classifier_probs.numpy().mean(1)\n",
+ "plt.bar(xx, yy)\n",
+ "plt.xticks(xx, keys)\n",
+ "plt.ylim(max(0,yy.min()-yy.ptp()/2.), yy.max()+yy.ptp()/2.)\n",
+ "plt.title(\"Standard classifier predictions\");"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "j0Cvvt90DoAm"
+ },
+ "source": [
+ "Take a look at the accuracies for this first model across these four groups. What do you observe? Would you consider this model biased or unbiased? What are some reasons why a trained model may have biased accuracies?"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0AKcHnXVtgqJ"
+ },
+ "source": [
+ "## 2.3 Mitigating algorithmic bias\n",
"\n",
"Imbalances in the training data can result in unwanted algorithmic bias. For example, the majority of faces in CelebA (our training set) are those of light-skinned females. As a result, a classifier trained on CelebA will be better suited at recognizing and classifying faces with features similar to these, and will thus be biased.\n",
"\n",
- "What if we actually ***learned*** the distribution of data features in an unbiased, unsupervised manner, without the need for any annotation? What could such an approach tell us about hidden biases that may exist in the data, or regions of the data in which the model is less confident in its predictions?\n",
+ "How could we overcome this? A naive solution -- and one that is being adopted by many companies and organizations -- would be to annotate different subclasses (i.e., light-skinned females, males with hats, etc.) within the training data, and then manually even out the data with respect to these groups.\n",
"\n",
- "In the rest of this lab, we will tackle exactly these questions."
+ "But this approach has two major disadvantages. First, it requires annotating massive amounts of data, which is not scalable. Second, it requires that we know what potential biases (e.g., race, gender, pose, occlusion, hats, glasses, etc.) to look for in the data. As a result, manual annotation may not capture all the different features that are imbalanced within the training data.\n",
+ "\n",
+ "Instead, let's actually **learn** these features in an unbiased, unsupervised manner, without the need for any annotation, and then train a classifier fairly with respect to these features. In the rest of this lab, we'll do exactly that."
]
},
{
@@ -380,15 +503,15 @@
"source": [
"## 2.4 Variational autoencoder (VAE) for learning latent structure\n",
"\n",
- "The accuracy of facial detection classifiers can vary significantly across different demographics. Consider the dataset the CNN model was trained on, CelebA. If certain features, such as dark skin or hats, are *rare* in CelebA, the model may end up biased against these as a result of training with a biased dataset. That is to say, its classification accuracy will be worse on faces that have under-represented features, such as dark-skinned faces or faces with hats, relevative to faces with features well-represented in the training data! This is a problem.\n",
+ "As you saw, the accuracy of the CNN varies across the four demographics we looked at. To think about why this may be, consider the dataset the model was trained on, CelebA. If certain features, such as dark skin or hats, are *rare* in CelebA, the model may end up biased against these as a result of training with a biased dataset. That is to say, its classification accuracy will be worse on faces that have under-represented features, such as dark-skinned faces or faces with hats, relevative to faces with features well-represented in the training data! This is a problem.\n",
"\n",
- "Our goal is to train a model that **learns a representation of the underlying latent space** to the face training data. Such a learned representation will provide information on what features are under-represented or over-represented in the data. The key design requirement for our model is that it can learn an *encoding* of the latent features in the face data in an entirely *unsupervised* way, without any supervised annotation by us humans. To achieve this, we turn to variational autoencoders (VAEs).\n",
+ "Our goal is to train a *debiased* version of this classifier -- one that accounts for potential disparities in feature representation within the training data. Specifically, to build a debiased facial classifier, we'll train a model that **learns a representation of the underlying latent space** to the face training data. The model then uses this information to mitigate unwanted biases by sampling faces with rare features, like dark skin or hats, *more frequently* during training. The key design requirement for our model is that it can learn an *encoding* of the latent features in the face data in an entirely *unsupervised* way. To achieve this, we'll turn to variational autoencoders (VAEs).\n",
"\n",
"\n",
"\n",
- "As shown in the schematic above and in Lecture 4, VAEs rely on an encoder-decoder structure to learn a latent representation of the input data. In the context of computer vision, the encoder network takes in input images, encodes them into a series of variables defined by a mean and standard deviation, and then draws from the distributions defined by these parameters to generate a set of sampled latent variables. The decoder network then \"decodes\" these variables to generate a reconstruction of the original image, which is used during training to help the model identify which latent variables are important to learn. \n",
+ "As shown in the schematic above and in Lecture 4, VAEs rely on an encoder-decoder structure to learn a latent representation of the input data. In the context of computer vision, the encoder network takes in input images, encodes them into a series of variables defined by a mean and standard deviation, and then draws from the distributions defined by these parameters to generate a set of sampled latent variables. The decoder network then \"decodes\" these variables to generate a reconstruction of the original image, which is used during training to help the model identify which latent variables are important to learn.\n",
"\n",
- "Let's formalize two key aspects of the VAE model and define relevant functions for each."
+ "Let's formalize two key aspects of the VAE model and define relevant functions for each.\n"
]
},
{
@@ -428,19 +551,17 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "S00ASo1ImSuh"
},
- "outputs": [],
"source": [
"### Defining the VAE loss function ###\n",
"\n",
"''' Function to calculate VAE loss given:\n",
- " an input x, \n",
- " reconstructed output x_recon, \n",
- " encoded means mu, \n",
- " encoded log of standard deviation logsigma, \n",
+ " an input x,\n",
+ " reconstructed output x_recon,\n",
+ " encoded means mu,\n",
+ " encoded log of standard deviation logsigma,\n",
" weight parameter for the latent loss kl_weight\n",
"'''\n",
"def vae_loss_function(x, x_recon, mu, logsigma, kl_weight=0.0005):\n",
@@ -448,10 +569,10 @@
" # in the text block directly above\n",
" latent_loss = # TODO\n",
"\n",
- " # TODO: Define the reconstruction loss as the mean absolute pixel-wise \n",
- " # difference between the input and reconstruction. Hint: you'll need to \n",
- " # use tf.reduce_mean, and supply an axis argument which specifies which \n",
- " # dimensions to reduce over. For example, reconstruction loss needs to average \n",
+ " # TODO: Define the reconstruction loss as the mean absolute pixel-wise\n",
+ " # difference between the input and reconstruction. Hint: you'll need to\n",
+ " # use tf.reduce_mean, and supply an axis argument which specifies which\n",
+ " # dimensions to reduce over. For example, reconstruction loss needs to average\n",
" # over the height, width, and channel image dimensions.\n",
" # https://www.tensorflow.org/api_docs/python/tf/math/reduce_mean\n",
" reconstruction_loss = # TODO\n",
@@ -459,8 +580,19 @@
" # TODO: Define the VAE loss. Note this is given in the equation for L_{VAE}\n",
" # in the text block directly above\n",
" vae_loss = # TODO\n",
- " \n",
+ "\n",
" return vae_loss"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "E8mpb3pJorpu"
+ },
+ "source": [
+ "Great! Now that we have a more concrete sense of how VAEs work, let's explore how we can leverage this network structure to train a *debiased* facial classifier."
]
},
{
@@ -469,9 +601,9 @@
"id": "DqtQH4S5fO8F"
},
"source": [
- "### Understanding VAEs: sampling and reparameterization \n",
+ "### Understanding VAEs: reparameterization\n",
"\n",
- "As you may recall from lecture, VAEs use a \"reparameterization trick\" for sampling learned latent variables. Instead of the VAE encoder generating a single vector of real numbers for each latent variable, it generates a vector of means and a vector of standard deviations that are constrained to roughly follow Gaussian distributions. We then sample a noise value $\\epsilon$ from a Gaussian distribution, and then scale it by the standard deviation and add back the mean to output the result as our sampled latent vector. Formalizing this for a latent variable $z$ where we sample $\\epsilon \\sim N(0,(I))$ we have:\n",
+ "As you may recall from lecture, VAEs use a \"reparameterization trick\" for sampling learned latent variables. Instead of the VAE encoder generating a single vector of real numbers for each latent variable, it generates a vector of means and a vector of standard deviations that are constrained to roughly follow Gaussian distributions. We then sample from the standard deviations and add back the mean to output this as our sampled latent vector. Formalizing this for a latent variable $z$ where we sample $\\epsilon \\sim N(0,(I))$ we have:\n",
"\n",
"$$z = \\mu + e^{\\left(\\frac{1}{2} \\cdot \\log{\\Sigma}\\right)}\\circ \\epsilon$$\n",
"\n",
@@ -482,15 +614,13 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "cT6PGdNajl3K"
},
- "outputs": [],
"source": [
- "### VAE Sampling ###\n",
+ "### VAE Reparameterization ###\n",
"\n",
- "\"\"\"Sample latent variables via reparameterization with an isotropic unit Gaussian.\n",
+ "\"\"\"Reparameterization trick by sampling from an isotropic unit Gaussian.\n",
"# Arguments\n",
" z_mean, z_logsigma (tensor): mean and log of standard deviation of latent distribution (Q(z|X))\n",
"# Returns\n",
@@ -504,18 +634,10 @@
" # TODO: Define the reparameterization computation!\n",
" # Note the equation is given in the text block immediately above.\n",
" z = # TODO\n",
- " \n",
" return z"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "bcpznUHHuR6I"
- },
- "source": [
- "Great! Now that we have a more concrete sense of how VAEs work, let's explore how we can leverage this network structure to diagnoses hidden biases in facial detection classifiers."
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -523,28 +645,28 @@
"id": "qtHEYI9KNn0A"
},
"source": [
- "## 2.5 Semi-supervised variational autoencoder (SS-VAE)\n",
+ "## 2.5 Debiasing variational autoencoder (DB-VAE)\n",
+ "\n",
+ "Now, we'll use the general idea behind the VAE architecture to build a model, termed a [*debiasing variational autoencoder*](https://lmrt.mit.edu/sites/default/files/AIES-19_paper_220.pdf) or DB-VAE, to mitigate (potentially) unknown biases present within the training idea. We'll train our DB-VAE model on the facial detection task, run the debiasing operation during training, evaluate on the PPB dataset, and compare its accuracy to our original, biased CNN model. \n",
+ "\n",
+ "### The DB-VAE model\n",
"\n",
- "Now, we will use the general idea behind the VAE architecture to build a model to automatically uncover (potentially) unknown biases present within the training data, while simultaneously learning the facial detection task. This draws direct inspiration from [a recent paper](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf) proposing this as a general approach for automatic bias detetion and mitigation.\n"
+ "The key idea behind this debiasing approach is to use the latent variables learned via a VAE to adaptively re-sample the CelebA data during training. Specifically, we will alter the probability that a given image is used during training based on how often its latent features appear in the dataset. So, faces with rarer features (like dark skin, sunglasses, or hats) should become more likely to be sampled during training, while the sampling probability for faces with features that are over-represented in the training dataset should decrease (relative to uniform random sampling across the training data).\n",
+ "\n",
+ "A general schematic of the DB-VAE approach is shown here:\n",
+ "\n",
+ "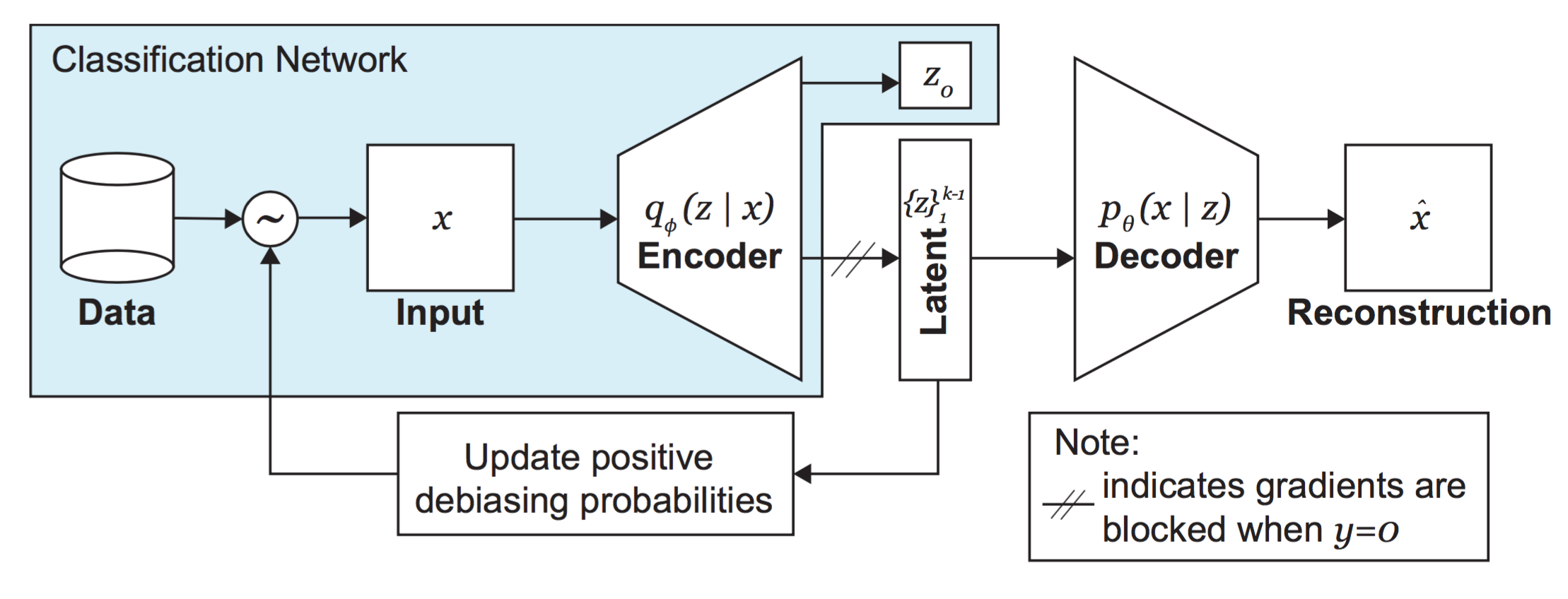"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "A3IOB3d61WSN"
+ "id": "ziA75SN-UxxO"
},
"source": [
- "### Semi-supervised VAE architecture\n",
- "\n",
- "We will develop a VAE that has a supervised component in order to both output a classification decision for the facial detection task and analyze where the biases in our model may be resulting from. While previous works like that of Buolamwini and Gebru have focused on skin tone and gender as two categories where facial detection models may be experiencing bias, there may be other unlabeled features that also are biased, resulting in poorer classification performance. We will build our semi-supervised VAE (SS-VAE) to learn these underlying latent features.\n",
- "\n",
- "A general schematic of the SS-VAE architecture is shown here.\n",
+ "Recall that we want to apply our DB-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the DB-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is another key distinction between the DB-VAE and a traditional VAE.\n",
"\n",
- "\n",
- "\n",
- "We will apply our SS-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the SS-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is the key distinction between the SS-VAE and a traditional VAE. \n",
- "\n",
- "Keep in mind that we only want to learn the latent representation of *faces*, as that is where we are interested in uncovering potential biases, even though we are training a model on a binary classification problem. So, we will need to ensure that, **for faces**, our SS-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, and outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$."
+ "Keep in mind that we only want to learn the latent representation of *faces*, as that's what we're ultimately debiasing against, even though we are training a model on a binary classification problem. We'll need to ensure that, **for faces**, our DB-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, **and** outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$."
]
},
{
@@ -553,35 +675,34 @@
"id": "XggIKYPRtOZR"
},
"source": [
- "### Defining the SS-VAE loss function\n",
+ "### Defining the DB-VAE loss function\n",
"\n",
- "This means we'll need to be a bit clever about the loss function for the SS-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered. \n",
+ "This means we'll need to be a bit clever about the loss function for the DB-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered.\n",
"\n",
"For **face images**, our loss function will have two components:\n",
"\n",
+ "\n",
"1. **VAE loss ($L_{VAE}$)**: consists of the latent loss and the reconstruction loss.\n",
- "2. **Classification loss ($L_y(y,\\hat{y})$)**: standard cross-entropy loss for a binary classification problem. \n",
+ "2. **Classification loss ($L_y(y,\\hat{y})$)**: standard cross-entropy loss for a binary classification problem.\n",
"\n",
- "In contrast, for images of **non-faces**, our loss function is solely the classification loss. \n",
+ "In contrast, for images of **non-faces**, our loss function is solely the classification loss.\n",
"\n",
"We can write a single expression for the loss by defining an indicator variable ${I}_f$which reflects which training data are images of faces (${I}_f(y) = 1$ ) and which are images of non-faces (${I}_f(y) = 0$). Using this, we obtain:\n",
"\n",
"$$L_{total} = L_y(y,\\hat{y}) + {I}_f(y)\\Big[L_{VAE}\\Big]$$\n",
"\n",
- "Let's write a function to define the SS-VAE loss function:\n"
+ "Let's write a function to define the DB-VAE loss function:\n"
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "VjieDs8Ovcqs"
},
- "outputs": [],
"source": [
- "### Loss function for SS-VAE ###\n",
+ "### Loss function for DB-VAE ###\n",
"\n",
- "\"\"\"Loss function for SS-VAE.\n",
+ "\"\"\"Loss function for DB-VAE.\n",
"# Arguments\n",
" x: true input x\n",
" x_pred: reconstructed x\n",
@@ -590,12 +711,12 @@
" mu: mean of latent distribution (Q(z|X))\n",
" logsigma: log of standard deviation of latent distribution (Q(z|X))\n",
"# Returns\n",
- " total_loss: SS-VAE total loss\n",
- " classification_loss: SS-VAE classification loss\n",
+ " total_loss: DB-VAE total loss\n",
+ " classification_loss = DB-VAE classification loss\n",
"\"\"\"\n",
- "def ss_vae_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n",
+ "def debiasing_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n",
"\n",
- " # TODO: call the relevant function to obtain VAE loss, defined earlier in the lab\n",
+ " # TODO: call the relevant function to obtain VAE loss\n",
" vae_loss = vae_loss_function('''TODO''') # TODO\n",
"\n",
" # TODO: define the classification loss using sigmoid_cross_entropy\n",
@@ -606,12 +727,14 @@
" # indicator that reflects which training data are images of faces\n",
" face_indicator = tf.cast(tf.equal(y, 1), tf.float32)\n",
"\n",
- " # TODO: define the SS-VAE total loss! Use tf.reduce_mean to average over all\n",
+ " # TODO: define the DB-VAE total loss! Use tf.reduce_mean to average over all\n",
" # samples\n",
" total_loss = # TODO\n",
"\n",
- " return total_loss, classification_loss, vae_loss"
- ]
+ " return total_loss, classification_loss"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -619,25 +742,25 @@
"id": "YIu_2LzNWwWY"
},
"source": [
- "### Defining the SS-VAE architecture\n",
+ "### DB-VAE architecture\n",
"\n",
- "Now we're ready to define the SS-VAE architecture. To build the SS-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the encoder and decoder networks, and then construct the end-to-end VAE. We will use a latent space with 32 latent variables.\n",
+ "Now we're ready to define the DB-VAE architecture. To build the DB-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the two models, and then construct the end-to-end VAE. We will use a latent space with 100 latent variables.\n",
"\n",
"The decoder network will take as input the sampled latent variables, run them through a series of deconvolutional layers, and output a reconstruction of the original input image."
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "JfWPHGrmyE7R"
},
- "outputs": [],
"source": [
- "### Define the decoder portion of the SS-VAE ###\n",
+ "### Define the decoder portion of the DB-VAE ###\n",
"\n",
- "def make_face_decoder_network(n_filters=12):\n",
+ "n_filters = 12 # base number of convolutional filters, same as standard CNN\n",
+ "latent_dim = 100 # number of latent variables\n",
"\n",
+ "def make_face_decoder_network():\n",
" # Functionally define the different layer types we will use\n",
" Conv2DTranspose = functools.partial(tf.keras.layers.Conv2DTranspose, padding='same', activation='relu')\n",
" BatchNormalization = tf.keras.layers.BatchNormalization\n",
@@ -659,7 +782,9 @@
" ])\n",
"\n",
" return decoder"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -667,26 +792,24 @@
"id": "yWCMu12w1BuD"
},
"source": [
- "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the SS-VAE. Here, we will define the core VAE architecture by sublassing the `Model` class; defining encoding, sampling, and decoding operations; and calling the network end-to-end."
+ "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the DB-VAE. Note that at this point, there is nothing special about how we put the model together that makes it a \"debiasing\" model -- that will come when we define the training operation. Here, we will define the core VAE architecture by sublassing the `Model` class; defining encoding, reparameterization, and decoding operations; and calling the network end-to-end."
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "dSFDcFBL13c3"
},
- "outputs": [],
"source": [
- "### Defining and creating the SS-VAE ###\n",
+ "### Defining and creating the DB-VAE ###\n",
"\n",
- "class SS_VAE(tf.keras.Model):\n",
+ "class DB_VAE(tf.keras.Model):\n",
" def __init__(self, latent_dim):\n",
- " super(SS_VAE, self).__init__()\n",
+ " super(DB_VAE, self).__init__()\n",
" self.latent_dim = latent_dim\n",
"\n",
- " # Define the number of outputs for the encoder. Recall that we have \n",
- " # `latent_dim` latent variables, as well as a supervised output for the \n",
+ " # Define the number of outputs for the encoder. Recall that we have\n",
+ " # `latent_dim` latent variables, as well as a supervised output for the\n",
" # classification.\n",
" num_encoder_dims = 2*self.latent_dim + 1\n",
"\n",
@@ -694,7 +817,7 @@
" self.decoder = make_face_decoder_network()\n",
"\n",
" # function to feed images into encoder, encode the latent space, and output\n",
- " # classification probability \n",
+ " # classification probability\n",
" def encode(self, x):\n",
" # encoder output\n",
" encoder_output = self.encoder(x)\n",
@@ -702,29 +825,33 @@
" # classification prediction\n",
" y_logit = tf.expand_dims(encoder_output[:, 0], -1)\n",
" # latent variable distribution parameters\n",
- " z_mean = encoder_output[:, 1:self.latent_dim+1] \n",
+ " z_mean = encoder_output[:, 1:self.latent_dim+1]\n",
" z_logsigma = encoder_output[:, self.latent_dim+1:]\n",
"\n",
" return y_logit, z_mean, z_logsigma\n",
"\n",
+ " # VAE reparameterization: given a mean and logsigma, sample latent variables\n",
+ " def reparameterize(self, z_mean, z_logsigma):\n",
+ " # TODO: call the sampling function defined above\n",
+ " z = # TODO\n",
+ " return z\n",
+ "\n",
" # Decode the latent space and output reconstruction\n",
" def decode(self, z):\n",
- " # TODO: use the decoder (self.decoder) to output the reconstruction\n",
+ " # TODO: use the decoder to output the reconstruction\n",
" reconstruction = # TODO\n",
" return reconstruction\n",
"\n",
" # The call function will be used to pass inputs x through the core VAE\n",
- " def call(self, x): \n",
+ " def call(self, x):\n",
" # Encode input to a prediction and latent space\n",
" y_logit, z_mean, z_logsigma = self.encode(x)\n",
"\n",
- " # TODO: call the sampling function that you created above using \n",
- " # z_mean and z_logsigma\n",
+ " # TODO: reparameterization\n",
" z = # TODO\n",
"\n",
" # TODO: reconstruction\n",
" recon = # TODO\n",
- " \n",
" return y_logit, z_mean, z_logsigma, recon\n",
"\n",
" # Predict face or not face logit for given input x\n",
@@ -732,8 +859,10 @@
" y_logit, z_mean, z_logsigma = self.encode(x)\n",
" return y_logit\n",
"\n",
- "ss_vae = SS_VAE(latent_dim=32)"
- ]
+ "dbvae = DB_VAE(latent_dim)"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -741,7 +870,7 @@
"id": "M-clbYAj2waY"
},
"source": [
- "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed SS-VAE model in the `call` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n",
+ "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed DB_VAE model in the `call` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n",
"\n"
]
},
@@ -751,277 +880,235 @@
"id": "nbDNlslgQc5A"
},
"source": [
- "### Training the SS-VAE\n",
+ "### Adaptive resampling for automated debiasing with DB-VAE\n",
+ "\n",
+ "So, how can we actually use DB-VAE to train a debiased facial detection classifier?\n",
"\n",
- "We are ready to train our SS-VAE model! Complete the `TODO`s in the following training loop to train the SS-VAE with face classification output."
+ "Recall the DB-VAE architecture: as input images are fed through the network, the encoder learns an estimate ${Q}(z|X)$ of the latent space. We want to increase the relative frequency of rare data by increased sampling of under-represented regions of the latent space. We can approximate ${Q}(z|X)$ using the frequency distributions of each of the learned latent variables, and then define the probability distribution of selecting a given datapoint $x$ based on this approximation. These probability distributions will be used during training to re-sample the data.\n",
+ "\n",
+ "You'll write a function to execute this update of the sampling probabilities, and then call this function within the DB-VAE training loop to actually debias the model."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Fej5FDu37cf7"
+ },
+ "source": [
+ "First, we've defined a short helper function `get_latent_mu` that returns the latent variable means returned by the encoder after a batch of images is inputted to the network:"
]
},
{
"cell_type": "code",
+ "metadata": {
+ "id": "ewWbf7TE7wVc"
+ },
+ "source": [
+ "# Function to return the means for an input image batch\n",
+ "def get_latent_mu(images, dbvae, batch_size=1024):\n",
+ " N = images.shape[0]\n",
+ " mu = np.zeros((N, latent_dim))\n",
+ " for start_ind in range(0, N, batch_size):\n",
+ " end_ind = min(start_ind+batch_size, N+1)\n",
+ " batch = (images[start_ind:end_ind]).astype(np.float32)/255.\n",
+ " _, batch_mu, _ = dbvae.encode(batch)\n",
+ " mu[start_ind:end_ind] = batch_mu\n",
+ " return mu"
+ ],
"execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
"metadata": {
- "id": "xwQs-Gu5bKEK"
+ "id": "wn4yK3SC72bo"
+ },
+ "source": [
+ "Now, let's define the actual resampling algorithm `get_training_sample_probabilities`. Importantly note the argument `smoothing_fac`. This parameter tunes the degree of debiasing: for `smoothing_fac=0`, the re-sampled training set will tend towards falling uniformly over the latent space, i.e., the most extreme debiasing."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "HiX9pmmC7_wn"
},
- "outputs": [],
"source": [
- "### Training the SS-VAE ###\n",
+ "### Resampling algorithm for DB-VAE ###\n",
"\n",
- "comet_ml.init(project_name=\"6.s191lab2_part2_VAE\")\n",
- "comet_model_2 = comet_ml.Experiment()\n",
+ "'''Function that recomputes the sampling probabilities for images within a batch\n",
+ " based on how they distribute across the training data'''\n",
+ "def get_training_sample_probabilities(images, dbvae, bins=10, smoothing_fac=0.001):\n",
+ " print(\"Recomputing the sampling probabilities\")\n",
"\n",
- "# Hyperparameters\n",
- "batch_size = 32\n",
- "learning_rate = 5e-4\n",
- "latent_dim = 32\n",
+ " # TODO: run the input batch and get the latent variable means\n",
+ " mu = get_latent_mu('''TODO''') # TODO\n",
"\n",
- "# SS-VAE needs slightly more epochs to train since its more complex than \n",
- "# the standard classifier so we use 6 instead of 2\n",
- "num_epochs = 6\n",
+ " # sampling probabilities for the images\n",
+ " training_sample_p = np.zeros(mu.shape[0])\n",
"\n",
- "# instantiate a new SS-VAE model and optimizer\n",
- "ss_vae = SS_VAE(latent_dim)\n",
- "optimizer = tf.keras.optimizers.Adam(learning_rate)\n",
+ " # consider the distribution for each latent variable\n",
+ " for i in range(latent_dim):\n",
"\n",
- "# To define the training operation, we will use tf.function which is a powerful tool \n",
- "# that lets us turn a Python function into a TensorFlow computation graph.\n",
- "@tf.function\n",
- "def ss_vae_train_step(x, y):\n",
+ " latent_distribution = mu[:,i]\n",
+ " # generate a histogram of the latent distribution\n",
+ " hist_density, bin_edges = np.histogram(latent_distribution, density=True, bins=bins)\n",
"\n",
- " with tf.GradientTape() as tape:\n",
- " # Feed input x into ss_vae. Note that this is using the SS_VAE call function!\n",
- " y_logit, z_mean, z_logsigma, x_recon = ss_vae(x)\n",
+ " # find which latent bin every data sample falls in\n",
+ " bin_edges[0] = -float('inf')\n",
+ " bin_edges[-1] = float('inf')\n",
"\n",
- " '''TODO: call the SS_VAE loss function to compute the loss'''\n",
- " loss, class_loss = ss_vae_loss_function('''TODO arguments''') # TODO\n",
- " \n",
- " '''TODO: use the GradientTape.gradient method to compute the gradients.\n",
- " Hint: this is with respect to the trainable_variables of the SS_VAE.'''\n",
- " grads = tape.gradient('''TODO''', '''TODO''') # TODO\n",
+ " # TODO: call the digitize function to find which bins in the latent distribution\n",
+ " # every data sample falls in to\n",
+ " # https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.digitize.html\n",
+ " bin_idx = np.digitize('''TODO''', '''TODO''') # TODO\n",
"\n",
- " # apply gradients to variables\n",
- " optimizer.apply_gradients(zip(grads, ss_vae.trainable_variables))\n",
- " return loss\n",
+ " # smooth the density function\n",
+ " hist_smoothed_density = hist_density + smoothing_fac\n",
+ " hist_smoothed_density = hist_smoothed_density / np.sum(hist_smoothed_density)\n",
"\n",
- "# get training faces from data loader\n",
- "all_faces = loader.get_all_train_faces()\n",
+ " # invert the density function\n",
+ " p = 1.0/(hist_smoothed_density[bin_idx-1])\n",
"\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
+ " # TODO: normalize all probabilities\n",
+ " p = # TODO\n",
"\n",
- "# The training loop -- outer loop iterates over the number of epochs\n",
- "for i in range(num_epochs):\n",
+ " # TODO: update sampling probabilities by considering whether the newly\n",
+ " # computed p is greater than the existing sampling probabilities.\n",
+ " training_sample_p = # TODO\n",
"\n",
- " IPython.display.clear_output(wait=True)\n",
- " print(\"Starting epoch {}/{}\".format(i+1, num_epochs))\n",
- " \n",
- " # get a batch of training data and compute the training step\n",
- " for j in tqdm(range(loader.get_train_size() // batch_size)):\n",
- " # load a batch of data\n",
- " (x, y) = loader.get_batch(batch_size)\n",
- " # loss optimization\n",
- " loss = ss_vae_train_step(x, y)\n",
- " comet_model_2.log_metric(\"loss\", loss, step=j)\n",
- " \n",
- " # plot the progress every 200 steps\n",
- " if j % 500 == 0: \n",
- " mdl.util.plot_sample(x, y, ss_vae)"
- ]
+ " # final normalization\n",
+ " training_sample_p /= np.sum(training_sample_p)\n",
+ "\n",
+ " return training_sample_p"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
"metadata": {
- "id": "uZBlWDPOVcHg"
+ "id": "pF14fQkVUs-a"
},
"source": [
- "Wonderful! Now we should have a trained SS-VAE facial classification model, ready for evaluation!"
+ "Now that we've defined the resampling update, we can train our DB-VAE model on the CelebA/ImageNet training data, and run the above operation to re-weight the importance of particular data points as we train the model. Remember again that we only want to debias for features relevant to *faces*, not the set of negative examples. Complete the code block below to execute the training loop!"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
"metadata": {
- "id": "Eo34xC7MbaiQ"
+ "id": "xwQs-Gu5bKEK"
},
"source": [
- "## 2.6 Using the SS-VAE to uncover and diagnose biases\n",
+ "### Training the DB-VAE ###\n",
"\n",
- "With the SS-VAE model trained, we are ready to use it to uncover and diagnose hidden biases that exist within the dataset.\n",
+ "# Hyperparameters\n",
+ "params = dict(\n",
+ " batch_size = 32,\n",
+ " learning_rate = 5e-4,\n",
+ " latent_dim = 100,\n",
+ " num_epochs = 1, #DB-VAE needs slightly more epochs to train\n",
+ ")\n",
"\n",
- "Recall that our goal with the SS-VAE was to learn the underlying ***latent distribution*** of features in the training dataset, in order to uncover potential feature representation disparities that exist within the data.\n",
+ "experiment = create_experiment(\"6S191_Lab2_Part2_DBVAE\", params)\n",
"\n",
- "Additionally, training the SS-VAE required both a VAE reconstruction loss as well as a supervised classification loss. The VAE reconstruction loss direclty reflects how well the model is able to handle particular input data -- the higher the reconstruction loss, the harder that particular example is for the model to learn.\n",
+ "# instantiate a new DB-VAE model and optimizer\n",
+ "dbvae = DB_VAE(params[\"latent_dim\"])\n",
+ "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"])\n",
"\n",
- "We consider both these aspects to understand sources of uncertainty and bias within the model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "QfVngr5J6sj3"
- },
- "source": [
- "### Linking model performance to uncertainty and bias\n",
- "\n",
- "We begin by considering the examples in the dataset with the highest loss. What can you tell about which features seemed harder to learn for the VAE? What might this tell us about where the model struggles, and what predictions it may be more biased or uncertain about?\n",
+ "# To define the training operation, we will use tf.function which is a powerful tool\n",
+ "# that lets us turn a Python function into a TensorFlow computation graph.\n",
+ "@tf.function\n",
+ "def debiasing_train_step(x, y):\n",
"\n",
- "#### **TODO: Analysis and reflection**\n",
+ " with tf.GradientTape() as tape:\n",
+ " # Feed input x into dbvae. Note that this is using the DB_VAE call function!\n",
+ " y_logit, z_mean, z_logsigma, x_recon = dbvae(x)\n",
"\n",
- "Complete the analysis in the code block below. Write short (~1 sentence) answers to the following questions and include them in your Debiasing Faces Lab submission to complete the `TODO`s!\n",
+ " '''TODO: call the DB_VAE loss function to compute the loss'''\n",
+ " loss, class_loss = debiasing_loss_function('''TODO arguments''') # TODO\n",
"\n",
- "1. What, if any, trends do you observe comparing the samples with the highest and lowest reconstruction loss?\n",
- "2. Based on these observations, which features seemed harder to learn for the VAE?\n",
- "3. How does reconstruction loss relate to uncertainty? Think back to our lecture on Robust & Trustworthy Deep Learning! What can you say about examples on which the model may be more or less uncertain?"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "BRAwm0Jlrktc"
- },
- "outputs": [],
- "source": [
- "### Linking model performance to uncertainty and bias\n",
+ " '''TODO: use the GradientTape.gradient method to compute the gradients.\n",
+ " Hint: this is with respect to the trainable_variables of the dbvae.'''\n",
+ " grads = tape.gradient('''TODO''', '''TODO''') # TODO\n",
"\n",
- "# Load a random sample of 5000 faces from our dataset and compute the model performance on them\n",
- "(x, y) = loader.get_batch(5000, only_faces=True)\n",
- "y_logit, z_mean, z_logsigma, x_recon = ss_vae(x)\n",
- "loss, class_loss, vae_loss = ss_vae_loss_function(x, x_recon, y, y_logit, z_mean, z_logsigma)\n",
+ " # apply gradients to variables\n",
+ " optimizer.apply_gradients(zip(grads, dbvae.trainable_variables))\n",
+ " return loss\n",
"\n",
- "# Sort the results by the vae loss scores\n",
- "vae_loss = vae_loss.numpy()\n",
- "ind = np.argsort(vae_loss, axis=None)\n",
+ "# get training faces from data loader\n",
+ "all_faces = loader.get_all_train_faces()\n",
"\n",
- "# Plot the 25 samples with the highest and lowest reconstruction losses\n",
- "fig, ax = plt.subplots(1, 2, figsize=(16, 8))\n",
- "ax[0].imshow(mdl.util.create_grid_of_images(x[ind[:25]]))\n",
- "ax[0].set_title(\"Samples with the lowest reconstruction loss \\n\" + \n",
- " f\"Average recon loss: {np.mean(vae_loss[ind[:25]]):.2f}\")\n",
+ "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
"\n",
- "ax[1].imshow(mdl.util.create_grid_of_images(x[ind[-25:]]))\n",
- "ax[1].set_title(\"Samples with the highest reconstruction loss \\n\" + \n",
- " f\"Average recon loss: {np.mean(vae_loss[ind[-25:]]):.2f}\");\n",
+ "# The training loop -- outer loop iterates over the number of epochs\n",
+ "step = 0\n",
+ "for i in range(params[\"num_epochs\"]):\n",
"\n",
- "comet_model_2.log_figure()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "8SQSszTFjstZ"
- },
- "source": [
- "### Uncovering hidden biases through learned latent features \n",
+ " IPython.display.clear_output(wait=True)\n",
+ " print(\"Starting epoch {}/{}\".format(i+1, params[\"num_epochs\"]))\n",
"\n",
- "As we've seen above, loss is a powerful way to visualize which samples in our dataset the model has had trouble learning -- these examples are those that have high *model uncertainty*. However, this is not necessarily the same as bias!\n",
+ " # Recompute data sampling proabilities\n",
+ " '''TODO: recompute the sampling probabilities for debiasing'''\n",
+ " p_faces = get_training_sample_probabilities('''TODO''', '''TODO''') # TODO\n",
"\n",
- "How can we determine the relative frequencies and distributions of different latent features learned by the model? How may these metrics reveal underlying biases?\n",
+ " # get a batch of training data and compute the training step\n",
+ " for j in tqdm(range(loader.get_train_size() // params[\"batch_size\"])):\n",
+ " # load a batch of data\n",
+ " (x, y) = loader.get_batch(params[\"batch_size\"], p_pos=p_faces)\n",
"\n",
- "Let's investigate how well the SS-VAE actually learned the latent features of the faces. To do this, we will inspect individual latent features -- holding all others constant -- and look at the distribution of these features in the data and their corresponding examples. We can examine the shape and probability density of the learned latent features. Further we directly compare different values of individual latent variables to corresponding relative classification accuracies (marginalizing out the effects of the other latent variables).\n",
+ " # loss optimization\n",
+ " loss = debiasing_train_step(x, y)\n",
+ " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
"\n",
- "#### **TODO: Analysis and reflection**\n",
+ " # plot the progress every 200 steps\n",
+ " if j % 500 == 0:\n",
+ " mdl.util.plot_sample(x, y, dbvae)\n",
"\n",
- "Complete the analysis in the code blocks below. Carefully inspect the different latent variables and their corresponding frequency distributions. Write short (~1 sentence) answers to the following questions and include them in your Debiasing Faces Lab submission to complete the `TODO`s!\n",
+ " step += 1\n",
"\n",
- "1. Pick two latent variables and describe what semantic meaning they reflect. Include screenshots of the realizations and probability distribution for the latent variables you select.\n",
- "2. For the latent variables selected, what can you tell about which features are under- or over-represented in the data? What might this tell us about how the model is biased?\n",
- "3. For the latent variables selected, how do these feature distribution differences affect classification performance? What, if any, general trends do you observe across the latent variables?\n",
- "4. Based on these observations, please describe your understanding of the bias of the facial detection classifier."
- ]
+ "experiment.end()"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "cellView": "form",
- "id": "8qcR9uvfCJku"
+ "id": "uZBlWDPOVcHg"
},
- "outputs": [],
"source": [
- "### Inspect different latent features\n",
- "\n",
- "#@title Change the sliders to inspect different latent features! { run: \"auto\" }\n",
- "idx_latent = 8 #@param {type:\"slider\", min:0, max:31, step:1}\n",
- "num_steps = 15\n",
- "\n",
- "# Extract all latent samples from the desired dimension\n",
- "latent_samples = z_mean[:, idx_latent]\n",
- "\n",
- "# Compute their density and plot\n",
- "density, latent_bins = np.histogram(latent_samples, num_steps, density=True)\n",
- "fig, ax = plt.subplots(2, 1, figsize=(15, 4))\n",
- "ax[0].bar(latent_bins[1:], density)\n",
- "ax[0].set_ylabel(\"Data density\")\n",
- "\n",
- "# Visualize reconstructions as we walk across the latent space\n",
- "latent_steps = np.linspace(np.min(latent_samples), np.max(latent_samples), num_steps)\n",
- "baseline_latent = tf.reduce_mean(z_mean, 0, keepdims=True)\n",
- "\n",
- "recons = []\n",
- "for step in latent_steps: \n",
- " # Adjust the latent vector according to our step\n",
- " latent = baseline_latent.numpy()\n",
- " latent[0, idx_latent] = step\n",
- " # Decode the reconstruction and store\n",
- " recons.append(ss_vae.decode(latent)[0])\n",
- "\n",
- "# Visualize all of the reconstructions!\n",
- "ax[1].imshow(mdl.util.create_grid_of_images(recons, (1, num_steps)))\n",
- "ax[1].set_xlabel(\"Latent step\")\n",
- "ax[1].set_ylabel(\"Visualization\");\n",
- "\n",
- "comet_model_2.log_figure()"
+ "Wonderful! Now we should have a trained and (hopefully!) debiased facial classification model, ready for evaluation!"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "3ExRRPO2z27z"
+ "id": "Eo34xC7MbaiQ"
},
"source": [
+ "## 2.6 Evaluation of DB-VAE on Test Dataset\n",
"\n",
- "### Inspect how the accuracy changes as a function of density in the latent space\n"
+ "Finally let's test our DB-VAE model on the test dataset, looking specifically at its accuracy on each the \"Dark Male\", \"Dark Female\", \"Light Male\", and \"Light Female\" demographics. We will compare the performance of this debiased model against the (potentially biased) standard CNN from earlier in the lab."
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
- "id": "PnmPXmkGLBVU"
+ "id": "bgK77aB9oDtX"
},
- "outputs": [],
"source": [
- "### Accuracy vs. density in latent space\n",
- "\n",
- "# Loop through every latent dimension\n",
- "avg_logit_per_bin = []\n",
- "for idx_latent in range(latent_dim): \n",
- " latent_samples = z_mean[:, idx_latent]\n",
- " start = np.percentile(latent_samples, 5)\n",
- " end = np.percentile(latent_samples, 95)\n",
- " latent_steps = np.linspace(start, end, num_steps)\n",
- "\n",
- " # Find which samples fall in which bin of the latent dimension\n",
- " which_latent_bin = np.digitize(latent_samples, latent_steps)\n",
- " \n",
- " # For each latent bin, compute the accuracy (average logit score)\n",
- " avg_logit = []\n",
- " for j in range(0, num_steps+1): \n",
- " inds_in_bin = np.where(which_latent_bin == j)\n",
- " avg_logit.append(y_logit.numpy()[inds_in_bin].mean())\n",
- "\n",
- " avg_logit_per_bin.append(avg_logit)\n",
- " \n",
- "# Average the results across all latent dimensions and all samples\n",
- "accuracy_per_latent = np.mean(avg_logit_per_bin, 0)\n",
- "accuracy_per_latent = (accuracy_per_latent - accuracy_per_latent.min()) / np.ptp(accuracy_per_latent)\n",
- "\n",
- "# Plot the results\n",
- "plt.plot(np.linspace(np.min(z_mean), np.max(z_mean), num_steps+1), accuracy_per_latent,'-o')\n",
- "plt.xlabel(\"Latent step\")\n",
- "plt.ylabel(\"Relative accuracy\")\n",
- "\n",
- "comet_model_2.log_figure()\n",
- "comet_model_2.end()"
- ]
+ "dbvae_logits = [dbvae.predict(np.array(x, dtype=np.float32)) for x in test_faces]\n",
+ "dbvae_probs = tf.squeeze(tf.sigmoid(dbvae_logits))\n",
+ "\n",
+ "xx = np.arange(len(keys))\n",
+ "plt.bar(xx, standard_classifier_probs.numpy().mean(1), width=0.2, label=\"Standard CNN\")\n",
+ "plt.bar(xx+0.2, dbvae_probs.numpy().mean(1), width=0.2, label=\"DB-VAE\")\n",
+ "plt.xticks(xx, keys);\n",
+ "plt.title(\"Network predictions on test dataset\")\n",
+ "plt.ylabel(\"Probability\"); plt.legend(bbox_to_anchor=(1.04,1), loc=\"upper left\");\n"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -1029,71 +1116,29 @@
"id": "rESoXRPQo_mq"
},
"source": [
- "## 2.8 Conclusion and submission information\n",
+ "## 2.7 Conclusion and submission information\n",
"\n",
- "**To be eligible for the Debiasing Faces Lab prize, you must submit a document of your answers to the short-answer `TODO`s with your complete lab submission.** Please see the short-answer `TODO`s replicated again here:\n",
+ "We encourage you to think about and maybe even address some questions raised by the approach and results outlined here:\n",
"\n",
- "#### **TODO: Linking model performance to uncertainty and bias**\n",
+ "* How does the accuracy of the DB-VAE across the four demographics compare to that of the standard CNN? Do you find this result surprising in any way?\n",
+ "* How can the performance of the DB-VAE classifier be improved even further? We purposely did not optimize hyperparameters to leave this up to you!\n",
+ "* In which applications (either related to facial detection or not!) would debiasing in this way be desired? Are there applications where you may not want to debias your model?\n",
+ "* Do you think it should be necessary for companies to demonstrate that their models, particularly in the context of tasks like facial detection, are not biased? If so, do you have thoughts on how this could be standardized and implemented?\n",
+ "* Do you have ideas for other ways to address issues of bias, particularly in terms of the training data?\n",
"\n",
- "1. What, if any, trends do you observe comparing the samples with the highest and lowest reconstruction loss?\n",
- "2. Based on these observations, which features seemed harder to learn for the VAE?\n",
- "3. How does reconstruction loss relate to uncertainty? Think back to our lecture on Robust & Trustworthy Deep Learning! What can you say about examples on which the model may be more or less uncertain?\n",
+ "**Try to optimize your model to achieve improved performance. To enter the competition, please upload the following to the lab submission site for the Debiasing Faces Lab ([submission upload link](https://www.dropbox.com/request/KGct8m2IyOBVvIoQdef3)).**\n",
"\n",
- "#### **TODO: Uncovering hidden biases through learned latent features**\n",
+ "* Jupyter notebook with the code you used to generate your results;\n",
+ "* copy of the bar plot from section 2.6 showing the performance of your model;\n",
+ "* a written description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description;\n",
+ "* a written discussion of why these modifications helped improve performance.\n",
"\n",
- "1. Pick two latent variables and describe what semantic meaning they reflect. Include screenshots of the realizations and probability distribution for the latent variables you select.\n",
- "2. For the latent variables selected, what can you tell about which features are under- or over-represented in the data? What might this tell us about how the model is biased?\n",
- "3. For the latent variables selected, how do these feature distribution differences affect classification performance? What, if any, general trends do you observe across the latent variables?\n",
- "4. Based on these observations, please describe your understanding of the bias of the facial detection classifier.\n",
- "\n",
- "**To enter the competition, you must upload a document write-up as part of your complete lab submission for the Debiasing Faces Lab ([submission upload link](https://www.dropbox.com/request/TTYz3Ikx5wIgOITmm5i2)).** Complete details on submission are included in the next lab!\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mPRZReq4p68k"
- },
- "source": [
- "## 2.9 Thinking ahead\n",
- "\n",
- "Beyond this, we encourage you to think about the following questions as you prepare for the next lab, which will focus on mitigating the issues of bias and uncertainty that you just uncovered. Consider:\n",
- "* How do the samples with highest reconstruction loss and samples with highest bias compare? Which features is each one highlighting? Why do you think this is?\n",
- "* In what ways is the dataset biased so far? Can you imagine other features that the dataset is biased against that we have not uncovered yet?\n",
- "* How can the performance of the supervised VAE classifier be improved?\n",
- "* Do you have ideas for other ways to address issues of bias, particularly in terms of the training data?\n",
+ "**Name your file in the following format: `[FirstName]_[LastName]_Face`, followed by the file format (.zip, .ipynb, .pdf, etc).** ZIP files are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature (e.g., `[FirstName]_[LastName]_Face_TODO.pdf`, `[FirstName]_[LastName]_Face_Report.pdf`, etc.).\n",
"\n",
"Hopefully this lab has shed some light on a few concepts, from vision based tasks, to VAEs, to algorithmic bias. We like to think it has, but we're biased ;).\n",
"\n",
" "
]
}
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "Ag_e7xtTzT1W",
- "NDj7KBaW8Asz"
- ],
- "provenance": []
- },
- "gpuClass": "standard",
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "name": "python",
- "version": "3.9.0 (v3.9.0:9cf6752276, Oct 5 2020, 11:29:23) \n[Clang 6.0 (clang-600.0.57)]"
- },
- "vscode": {
- "interpreter": {
- "hash": "7812ea015bdcee6f23a998adcdd2ef97c151c0c241b7b7070987d9313e41299d"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
+ ]
+}
\ No newline at end of file
diff --git a/lab2/solutions/Part1_MNIST_Solution.ipynb b/lab2/solutions/Part1_MNIST_Solution.ipynb
index 8eb5c7b1..e52ef942 100644
--- a/lab2/solutions/Part1_MNIST_Solution.ipynb
+++ b/lab2/solutions/Part1_MNIST_Solution.ipynb
@@ -10,9 +10,9 @@
"
"
]
}
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "Ag_e7xtTzT1W",
- "NDj7KBaW8Asz"
- ],
- "provenance": []
- },
- "gpuClass": "standard",
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "name": "python",
- "version": "3.9.0 (v3.9.0:9cf6752276, Oct 5 2020, 11:29:23) \n[Clang 6.0 (clang-600.0.57)]"
- },
- "vscode": {
- "interpreter": {
- "hash": "7812ea015bdcee6f23a998adcdd2ef97c151c0c241b7b7070987d9313e41299d"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
+ ]
+}
\ No newline at end of file
diff --git a/lab2/solutions/Part1_MNIST_Solution.ipynb b/lab2/solutions/Part1_MNIST_Solution.ipynb
index 8eb5c7b1..e52ef942 100644
--- a/lab2/solutions/Part1_MNIST_Solution.ipynb
+++ b/lab2/solutions/Part1_MNIST_Solution.ipynb
@@ -10,9 +10,9 @@
" \n",
" \n",
" Visit MIT Deep Learning | \n",
- " \n",
+ " | \n",
" Run in Google Colab | \n",
- " \n",
+ " | \n",
" View Source on GitHub | \n",
"\n",
"\n",
@@ -27,8 +27,8 @@
},
"outputs": [],
"source": [
- "# Copyright 2023 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "# \n",
+ "# Copyright 2024 MIT Introduction to Deep Learning. All Rights Reserved.\n",
+ "#\n",
"# Licensed under the MIT License. You may not use this file except in compliance\n",
"# with the License. Use and/or modification of this code outside of MIT Introduction\n",
"# to Deep Learning must reference:\n",
@@ -62,50 +62,68 @@
"outputs": [],
"source": [
"# Import Tensorflow 2.0\n",
- "# %tensorflow_version 2.x\n",
- "!pip install tensorflow\n",
- "import tensorflow as tf \n",
+ "# !pip install tensorflow\n",
+ "import tensorflow as tf\n",
"\n",
- "!pip install mitdeeplearning\n",
+ "# MIT introduction to deep learning package\n",
+ "!pip install mitdeeplearning --quiet\n",
"import mitdeeplearning as mdl\n",
"\n",
+ "# other packages\n",
"import matplotlib.pyplot as plt\n",
"import numpy as np\n",
"import random\n",
- "from tqdm import tqdm\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "\n",
- "# assert len(tf.config.list_physical_devices('GPU')) > 0"
+ "from tqdm import tqdm"
]
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "id": "nCpHDxX1bzyZ"
+ },
"source": [
- "We'll also install Comet. f you followed the instructions from Lab 1, you should have you comet account set up. Otherwise, you'll need to sign up for an account and enter your API key. Click on the final link in the output to see your experiment."
+ "We'll also install Comet. If you followed the instructions from Lab 1, you should have your Comet account set up. Enter your API key below."
]
},
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "id": "GSR_PAqjbzyZ"
+ },
"outputs": [],
"source": [
- "!pip install comet_ml\n",
+ "!pip install comet_ml > /dev/null 2>&1\n",
"import comet_ml\n",
- "comet_ml.init(project_name=\"6.s191lab2_part1_NN\")\n",
- "comet_model_1 = comet_ml.Experiment()"
+ "# TODO: ENTER YOUR API KEY HERE!!\n",
+ "COMET_API_KEY = \"\"\n",
+ "\n",
+ "# Check that we are using a GPU, if not switch runtimes\n",
+ "# using Runtime > Change Runtime Type > GPU\n",
+ "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
+ "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
]
},
+ {
+ "cell_type": "code",
+ "source": [
+ "# start a first comet experiment for the first part of the lab\n",
+ "comet_ml.init(project_name=\"6S191_lab2_part1_NN\")\n",
+ "comet_model_1 = comet_ml.Experiment()"
+ ],
+ "metadata": {
+ "id": "wGPDtVxvTtPk"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
{
"cell_type": "markdown",
"metadata": {
"id": "HKjrdUtX_N8J"
},
"source": [
- "## 1.1 MNIST dataset \n",
+ "## 1.1 MNIST dataset\n",
"\n",
"Let's download and load the dataset and display a few random samples from it:"
]
@@ -132,7 +150,7 @@
"id": "5ZtUqOqePsRD"
},
"source": [
- "Our training set is made up of 28x28 grayscale images of handwritten digits. \n",
+ "Our training set is made up of 28x28 grayscale images of handwritten digits.\n",
"\n",
"Let's visualize what some of these images and their corresponding training labels look like."
]
@@ -179,7 +197,7 @@
},
"source": [
"### Fully connected neural network architecture\n",
- "To define the architecture of this first fully connected neural network, we'll once again use the Keras API and define the model using the [`Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential) class. Note how we first use a [`Flatten`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Flatten) layer, which flattens the input so that it can be fed into the model. \n",
+ "To define the architecture of this first fully connected neural network, we'll once again use the Keras API and define the model using the [`Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential) class. Note how we first use a [`Flatten`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Flatten) layer, which flattens the input so that it can be fed into the model.\n",
"\n",
"In this next block, you'll define the fully connected layers of this simple work."
]
@@ -202,9 +220,9 @@
" # tf.keras.layers.Dense(128, activation= '''TODO'''),\n",
"\n",
" # '''TODO: Define the second Dense layer to output the classification probabilities'''\n",
- " tf.keras.layers.Dense(10, activation=tf.nn.softmax) \n",
+ " tf.keras.layers.Dense(10, activation=tf.nn.softmax)\n",
" # [TODO Dense layer to output classification probabilities]\n",
- " \n",
+ "\n",
" ])\n",
" return fc_model\n",
"\n",
@@ -230,7 +248,7 @@
"\n",
"After the pixels are flattened, the network consists of a sequence of two `tf.keras.layers.Dense` layers. These are fully-connected neural layers. The first `Dense` layer has 128 nodes (or neurons). The second (and last) layer (which you've defined!) should return an array of probability scores that sum to 1. Each node contains a score that indicates the probability that the current image belongs to one of the handwritten digit classes.\n",
"\n",
- "That defines our fully connected model! "
+ "That defines our fully connected model!"
]
},
{
@@ -251,7 +269,7 @@
"\n",
"We'll start out by using a stochastic gradient descent (SGD) optimizer initialized with a learning rate of 0.1. Since we are performing a categorical classification task, we'll want to use the [cross entropy loss](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/sparse_categorical_crossentropy).\n",
"\n",
- "You'll want to experiment with both the choice of optimizer and learning rate and evaluate how these affect the accuracy of the trained model. "
+ "You'll want to experiment with both the choice of optimizer and learning rate and evaluate how these affect the accuracy of the trained model."
]
},
{
@@ -265,7 +283,7 @@
"'''TODO: Experiment with different optimizers and learning rates. How do these affect\n",
" the accuracy of the trained model? Which optimizers and/or learning rates yield\n",
" the best performance?'''\n",
- "model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=1e-1), \n",
+ "model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=1e-1),\n",
" loss='sparse_categorical_crossentropy',\n",
" metrics=['accuracy'])"
]
@@ -278,7 +296,7 @@
"source": [
"### Train the model\n",
"\n",
- "We're now ready to train our model, which will involve feeding the training data (`train_images` and `train_labels`) into the model, and then asking it to learn the associations between images and labels. We'll also need to define the batch size and the number of epochs, or iterations over the MNIST dataset, to use during training. \n",
+ "We're now ready to train our model, which will involve feeding the training data (`train_images` and `train_labels`) into the model, and then asking it to learn the associations between images and labels. We'll also need to define the batch size and the number of epochs, or iterations over the MNIST dataset, to use during training.\n",
"\n",
"In Lab 1, we saw how we can use `GradientTape` to optimize losses and train models with stochastic gradient descent. After defining the model settings in the `compile` step, we can also accomplish training by calling the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) method on an instance of the `Model` class. We will use this to train our fully connected model\n"
]
@@ -316,7 +334,7 @@
"source": [
"### Evaluate accuracy on the test dataset\n",
"\n",
- "Now that we've trained the model, we can ask it to make predictions about a test set that it hasn't seen before. In this example, the `test_images` array comprises our test dataset. To evaluate accuracy, we can check to see if the model's predictions match the labels from the `test_labels` array. \n",
+ "Now that we've trained the model, we can ask it to make predictions about a test set that it hasn't seen before. In this example, the `test_images` array comprises our test dataset. To evaluate accuracy, we can check to see if the model's predictions match the labels from the `test_labels` array.\n",
"\n",
"Use the [`evaluate`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#evaluate) method to evaluate the model on the test dataset!"
]
@@ -342,7 +360,7 @@
"id": "yWfgsmVXCaXG"
},
"source": [
- "You may observe that the accuracy on the test dataset is a little lower than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*, when a machine learning model performs worse on new data than on its training data. \n",
+ "You may observe that the accuracy on the test dataset is a little lower than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*, when a machine learning model performs worse on new data than on its training data.\n",
"\n",
"What is the highest accuracy you can achieve with this first fully connected model? Since the handwritten digit classification task is pretty straightforward, you may be wondering how we can do better...\n",
"\n",
@@ -393,7 +411,7 @@
"\n",
" # TODO: Define the first convolutional layer\n",
" tf.keras.layers.Conv2D(filters=24, kernel_size=(3,3), activation=tf.nn.relu),\n",
- " # tf.keras.layers.Conv2D('''TODO''') \n",
+ " # tf.keras.layers.Conv2D('''TODO''')\n",
"\n",
" # TODO: Define the first max pooling layer\n",
" tf.keras.layers.MaxPool2D(pool_size=(2,2)),\n",
@@ -410,15 +428,15 @@
" tf.keras.layers.Flatten(),\n",
" tf.keras.layers.Dense(128, activation=tf.nn.relu),\n",
"\n",
- " # TODO: Define the last Dense layer to output the classification \n",
+ " # TODO: Define the last Dense layer to output the classification\n",
" # probabilities. Pay attention to the activation needed a probability\n",
" # output\n",
" tf.keras.layers.Dense(10, activation=tf.nn.softmax)\n",
" # [TODO Dense layer to output classification probabilities]\n",
" ])\n",
- " \n",
+ "\n",
" return cnn_model\n",
- " \n",
+ "\n",
"cnn_model = build_cnn_model()\n",
"# Initialize the model by passing some data through\n",
"cnn_model.predict(train_images[[0]])\n",
@@ -475,7 +493,7 @@
"'''TODO: Use model.fit to train the CNN model, with the same batch_size and number of epochs previously used.'''\n",
"cnn_model.fit(train_images, train_labels, batch_size=BATCH_SIZE, epochs=EPOCHS)\n",
"# cnn_model.fit('''TODO''')\n",
- "# comet_model_2.end() "
+ "# comet_model_2.end()"
]
},
{
@@ -508,7 +526,7 @@
"id": "2rvEgK82Glv9"
},
"source": [
- "What is the highest accuracy you're able to achieve using the CNN model, and how does the accuracy of the CNN model compare to the accuracy of the simple fully connected network? What optimizers and learning rates seem to be optimal for training the CNN model? \n",
+ "What is the highest accuracy you're able to achieve using the CNN model, and how does the accuracy of the CNN model compare to the accuracy of the simple fully connected network? What optimizers and learning rates seem to be optimal for training the CNN model?\n",
"\n",
"Feel free to click the Comet links to investigate the training/accuracy curves for your model."
]
@@ -561,7 +579,7 @@
"id": "-hw1hgeSCaXN"
},
"source": [
- "As you can see, a prediction is an array of 10 numbers. Recall that the output of our model is a probability distribution over the 10 digit classes. Thus, these numbers describe the model's \"confidence\" that the image corresponds to each of the 10 different digits. \n",
+ "As you can see, a prediction is an array of 10 numbers. Recall that the output of our model is a probability distribution over the 10 digit classes. Thus, these numbers describe the model's \"confidence\" that the image corresponds to each of the 10 different digits.\n",
"\n",
"Let's look at the digit that has the highest confidence for the first image in the test dataset:"
]
@@ -576,7 +594,7 @@
"source": [
"'''TODO: identify the digit with the highest confidence prediction for the first\n",
" image in the test dataset. '''\n",
- "prediction = np.argmax(predictions[0]) \n",
+ "prediction = np.argmax(predictions[0])\n",
"# prediction = # TODO\n",
"\n",
"print(prediction)"
@@ -671,7 +689,7 @@
"source": [
"## 1.4 Training the model 2.0\n",
"\n",
- "Earlier in the lab, we used the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) function call to train the model. This function is quite high-level and intuitive, which is really useful for simpler models. As you may be able to tell, this function abstracts away many details in the training call, and we have less control over training model, which could be useful in other contexts. \n",
+ "Earlier in the lab, we used the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) function call to train the model. This function is quite high-level and intuitive, which is really useful for simpler models. As you may be able to tell, this function abstracts away many details in the training call, and we have less control over training model, which could be useful in other contexts.\n",
"\n",
"As an alternative to this, we can use the [`tf.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape) class to record differentiation operations during training, and then call the [`tf.GradientTape.gradient`](https://www.tensorflow.org/api_docs/python/tf/GradientTape#gradient) function to actually compute the gradients. You may recall seeing this in Lab 1 Part 1, but let's take another look at this here.\n",
"\n",
@@ -720,7 +738,7 @@
"\n",
" # Backpropagation\n",
" '''TODO: Use the tape to compute the gradient against all parameters in the CNN model.\n",
- " Use cnn_model.trainable_variables to access these parameters.''' \n",
+ " Use cnn_model.trainable_variables to access these parameters.'''\n",
" grads = tape.gradient(loss_value, cnn_model.trainable_variables)\n",
" # grads = # TODO\n",
" optimizer.apply_gradients(zip(grads, cnn_model.trainable_variables))\n",
@@ -736,7 +754,7 @@
},
"source": [
"## 1.5 Conclusion\n",
- "In this part of the lab, you had the chance to play with different MNIST classifiers with different architectures (fully-connected layers only, CNN), and experiment with how different hyperparameters affect accuracy (learning rate, etc.). The next part of the lab explores another application of CNNs, facial detection, and some drawbacks of AI systems in real world applications, like issues of bias. "
+ "In this part of the lab, you had the chance to play with different MNIST classifiers with different architectures (fully-connected layers only, CNN), and experiment with how different hyperparameters affect accuracy (learning rate, etc.). The next part of the lab explores another application of CNNs, facial detection, and some drawbacks of AI systems in real world applications, like issues of bias."
]
}
],
@@ -768,4 +786,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
+}
\ No newline at end of file
diff --git a/lab2/solutions/Part2_FaceDetection_Solution.ipynb b/lab2/solutions/Part2_Debiasing_Solution.ipynb
similarity index 50%
rename from lab2/solutions/Part2_FaceDetection_Solution.ipynb
rename to lab2/solutions/Part2_Debiasing_Solution.ipynb
index f963d1cd..fcdc8a79 100644
--- a/lab2/solutions/Part2_FaceDetection_Solution.ipynb
+++ b/lab2/solutions/Part2_Debiasing_Solution.ipynb
@@ -1,4 +1,21 @@
{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "name": "Part2_Debiasing_Solution.ipynb",
+ "provenance": [],
+ "collapsed_sections": [
+ "Ag_e7xtTzT1W",
+ "NDj7KBaW8Asz"
+ ]
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ },
+ "accelerator": "GPU"
+ },
"cells": [
{
"cell_type": "markdown",
@@ -10,9 +27,9 @@
" \n",
" \n",
" Visit MIT Deep Learning | \n",
- " \n",
+ " | \n",
" Run in Google Colab | \n",
- " \n",
+ " | \n",
" View Source on GitHub | \n",
"\n",
"\n",
@@ -21,22 +38,22 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "rNbf1pRlSDby"
},
- "outputs": [],
"source": [
- "# Copyright 2023 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "# \n",
+ "# Copyright 2024 MIT 6.S191 Introduction to Deep Learning. All Rights Reserved.\n",
+ "#\n",
"# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
+ "# with the License. Use and/or modification of this code outside of 6.S191 must\n",
+ "# reference:\n",
"#\n",
- "# © MIT Introduction to Deep Learning\n",
+ "# © MIT 6.S191: Introduction to Deep Learning\n",
"# http://introtodeeplearning.com\n",
"#"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -46,37 +63,57 @@
"source": [
"# Laboratory 2: Computer Vision\n",
"\n",
- "# Part 2: Diagnosing Bias in Facial Detection Systems\n",
+ "# Part 2: Debiasing Facial Detection Systems\n",
"\n",
- "In this lab, we'll explore a prominent aspect of applied deep learning for computer vision: facial detection. \n",
+ "In the second portion of the lab, we'll explore two prominent aspects of applied deep learning: facial detection and algorithmic bias.\n",
"\n",
- "Consider the task of facial detection: given an image, is it an image of a face? This seemingly simple -- but extremely important and pervasive -- task is subject to significant amounts of algorithmic bias among select demographics, as [seminal studies](https://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf) have shown.\n",
+ "Deploying fair, unbiased AI systems is critical to their long-term acceptance. Consider the task of facial detection: given an image, is it an image of a face? This seemingly simple, but extremely important, task is subject to significant amounts of algorithmic bias among select demographics.\n",
"\n",
- "Deploying fair, unbiased AI systems is critical to their long-term acceptance. In this lab, we will build computer vision models for facial detection. We will extend beyond that to build a model to **uncover and diagnose** the biases and issues that exist with standard facial detection models. To do this, we will build a semi-supervised variational autoencoder (SS-VAE) that learns the *latent distribution* of features underlying face image datasets in order to [uncover hidden biases](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf).\n",
+ "In this lab, we'll investigate [one recently published approach](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf) to addressing algorithmic bias. We'll build a facial detection model that learns the *latent variables* underlying face image datasets and uses this to adaptively re-sample the training data, thus mitigating any biases that may be present in order to train a *debiased* model.\n",
"\n",
- "Our work here will set the foundation for the next lab, where we'll build automated tools to mitigate the underlying issues of bias and uncertainty in facial detection."
+ "\n",
+ "Run the next code block for a short video from Google that explores how and why it's important to consider bias when thinking about machine learning:"
]
},
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "XQh5HZfbupFF"
+ },
+ "source": [
+ "import IPython\n",
+ "IPython.display.YouTubeVideo('59bMh59JQDo')"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
{
"cell_type": "markdown",
"metadata": {
"id": "3Ezfc6Yv6IhI"
},
"source": [
- "Let's get started by installing the relevant dependencies:"
+ "Let's get started by installing the relevant dependencies.\n",
+ "\n",
+ "We will be using Comet ML to track our model development and training runs.\n",
+ "\n",
+ "1. Sign up for a Comet account: [HERE](https://www.comet.com/signup?utm_source=mit_dl&utm_medium=partner&utm_content=github)\n",
+ "2. This will generate a personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable `COMET_API_KEY` below.\n",
+ "\n"
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "E46sWVKK6LP9"
},
- "outputs": [],
"source": [
+ "!pip install comet_ml --quiet\n",
+ "import comet_ml\n",
+ "# TODO: ENTER YOUR API KEY HERE!! instructions above\n",
+ "COMET_API_KEY = \"\"\n",
+ "\n",
"# Import Tensorflow 2.0\n",
- "# %tensorflow_version 2.x\n",
- "!pip install tensorflow\n",
"import tensorflow as tf\n",
"\n",
"import IPython\n",
@@ -85,15 +122,17 @@
"import numpy as np\n",
"from tqdm import tqdm\n",
"\n",
- "# Download and import the MIT Introduction to Deep Learning package\n",
- "!pip install mitdeeplearning\n",
+ "# Download and import the MIT 6.S191 package\n",
+ "!pip install mitdeeplearning --quiet\n",
"import mitdeeplearning as mdl\n",
"\n",
- "!pip install comet_ml\n",
- "import comet_ml\n",
- "comet_ml.init(project_name=\"6.s191lab2_part2_CNN\")\n",
- "comet_model_1 = comet_ml.Experiment()"
- ]
+ "# Check that we are using a GPU, if not switch runtimes\n",
+ "# using Runtime > Change Runtime Type > GPU\n",
+ "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
+ "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -103,29 +142,28 @@
"source": [
"## 2.1 Datasets\n",
"\n",
- "In order to train our facial detection models, we will need a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces). We will use these data to train our models to classify images as either faces or not faces.\n",
+ "We'll be using three datasets in this lab. In order to train our facial detection models, we'll need a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces). We'll use these data to train our models to classify images as either faces or not faces. Finally, we'll need a test dataset of face images. Since we're concerned about the potential *bias* of our learned models against certain demographics, it's important that the test dataset we use has equal representation across the demographics or features of interest. In this lab, we'll consider skin tone and gender.\n",
"\n",
- "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale dataset (over 200K images) of celebrity faces. \n",
- "2. **Negative training data**: [ImageNet](http://www.image-net.org/). A large-scale dataset with many images across many different categories. We will take negative examples from a variety of non-human categories.\n",
- "\n",
- "We will evaluate trained models on an independent test dataset of face images to diagnose potential issues with *bias, fairness, and confidence*.\n",
+ "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale (over 200K images) of celebrity faces. \n",
+ "2. **Negative training data**: [ImageNet](http://www.image-net.org/). Many images across many different categories. We'll take negative examples from a variety of non-human categories.\n",
+ "[Fitzpatrick Scale](https://en.wikipedia.org/wiki/Fitzpatrick_scale) skin type classification system, with each image labeled as \"Lighter'' or \"Darker''.\n",
"\n",
"Let's begin by importing these datasets. We've written a class that does a bit of data pre-processing to import the training data in a usable format."
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "RWXaaIWy6jVw"
},
- "outputs": [],
"source": [
"# Get the training data: both images from CelebA and ImageNet\n",
"path_to_training_data = tf.keras.utils.get_file('train_face.h5', 'https://www.dropbox.com/s/hlz8atheyozp1yx/train_face.h5?dl=1')\n",
"# Instantiate a TrainingDatasetLoader using the downloaded dataset\n",
"loader = mdl.lab2.TrainingDatasetLoader(path_to_training_data)"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -138,15 +176,15 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "DjPSjZZ_bGqe"
},
- "outputs": [],
"source": [
"number_of_training_examples = loader.get_train_size()\n",
"(images, labels) = loader.get_batch(100)"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -159,33 +197,31 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
- "cellView": "form",
"id": "Jg17jzwtbxDA"
},
- "outputs": [],
"source": [
- "#@title Change the sliders to look at positive and negative training examples! { run: \"auto\" }\n",
- "\n",
"### Examining the CelebA training dataset ###\n",
"\n",
+ "#@title Change the sliders to look at positive and negative training examples! { run: \"auto\" }\n",
+ "\n",
"face_images = images[np.where(labels==1)[0]]\n",
"not_face_images = images[np.where(labels==0)[0]]\n",
"\n",
- "idx_face = 19 #@param {type:\"slider\", min:0, max:50, step:1}\n",
- "idx_not_face = 8 #@param {type:\"slider\", min:0, max:50, step:1}\n",
+ "idx_face = 23 #@param {type:\"slider\", min:0, max:50, step:1}\n",
+ "idx_not_face = 9 #@param {type:\"slider\", min:0, max:50, step:1}\n",
"\n",
- "plt.figure(figsize=(8,4))\n",
+ "plt.figure(figsize=(5,5))\n",
"plt.subplot(1, 2, 1)\n",
"plt.imshow(face_images[idx_face])\n",
"plt.title(\"Face\"); plt.grid(False)\n",
"\n",
"plt.subplot(1, 2, 2)\n",
"plt.imshow(not_face_images[idx_not_face])\n",
- "plt.title(\"Not Face\"); plt.grid(False)\n",
- "comet_model_1.log_figure(figure=plt)"
- ]
+ "plt.title(\"Not Face\"); plt.grid(False)"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -195,9 +231,9 @@
"source": [
"### Thinking about bias\n",
"\n",
- "We will be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluate their accuracy as well as inspect and diagnose their hidden flaws. Our goal is to identify any potential issues and biases that may exist with the trained facial detection classifiers, and then diagnose what those issues and biases are.\n",
+ "Remember we'll be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluating their accuracy by testing them on an independent test dataset. Our goal is to build a model that trains on CelebA *and* achieves high classification accuracy on the the test dataset across all demographics, and to thus show that this model does not suffer from any hidden bias.\n",
"\n",
- "What exactly do we mean when we say a classifier is biased? In order to formalize this, we'll need to think about [*latent variables*](https://en.wikipedia.org/wiki/Latent_variable), variables that define a dataset but are not strictly observed. As defined in the generative modeling lecture, we use the term *latent space* to refer to the probability distributions of the aforementioned latent variables. Putting these ideas together, we consider a classifier *biased* if its classification decision changes after it sees some additional latent features or variables. This definition of bias will be helpful to keep in mind throughout the rest of the lab."
+ "What exactly do we mean when we say a classifier is biased? In order to formalize this, we'll need to think about [*latent variables*](https://en.wikipedia.org/wiki/Latent_variable), variables that define a dataset but are not strictly observed. As defined in the generative modeling lecture, we'll use the term *latent space* to refer to the probability distributions of the aforementioned latent variables. Putting these ideas together, we consider a classifier *biased* if its classification decision changes after it sees some additional latent features. This notion of bias may be helpful to keep in mind throughout the rest of the lab."
]
},
{
@@ -206,22 +242,20 @@
"id": "AIFDvU4w8OIH"
},
"source": [
- "## 2.2 CNN for facial detection \n",
+ "## 2.2 CNN for facial detection\n",
"\n",
- "First, we will define and train a baseline CNN on the facial detection task of classifying whether a given image is a face, or is not a face. We will then evaluate its accuracy. The CNN model has a relatively standard architecture consisting of a series of convolutional layers with batch normalization followed by two fully connected layers to flatten the convolution output and generate a class prediction. \n",
+ "First, we'll define and train a CNN on the facial classification task, and evaluate its accuracy. Later, we'll evaluate the performance of our debiased models against this baseline CNN. The CNN model has a relatively standard architecture consisting of a series of convolutional layers with batch normalization followed by two fully connected layers to flatten the convolution output and generate a class prediction.\n",
"\n",
"### Define and train the CNN model\n",
"\n",
- "Like we did in the first part of the lab, we will define our CNN model, and then train on the CelebA and ImageNet datasets using the `tf.GradientTape` class and the `tf.GradientTape.gradient` method."
+ "Like we did in the first part of the lab, we'll define our CNN model, and then train on the CelebA and ImageNet datasets using the `tf.GradientTape` class and the `tf.GradientTape.gradient` method."
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "82EVTAAW7B_X"
},
- "outputs": [],
"source": [
"### Define the CNN model ###\n",
"\n",
@@ -234,10 +268,10 @@
" Flatten = tf.keras.layers.Flatten\n",
" Dense = functools.partial(tf.keras.layers.Dense, activation='relu')\n",
"\n",
- " model = tf.keras.Sequential([ \n",
+ " model = tf.keras.Sequential([\n",
" Conv2D(filters=1*n_filters, kernel_size=5, strides=2),\n",
" BatchNormalization(),\n",
- " \n",
+ "\n",
" Conv2D(filters=2*n_filters, kernel_size=5, strides=2),\n",
" BatchNormalization(),\n",
"\n",
@@ -254,7 +288,9 @@
" return model\n",
"\n",
"standard_classifier = make_standard_classifier()"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -267,20 +303,48 @@
},
{
"cell_type": "code",
+ "source": [
+ "### Create a Comet experiment to track our training run ###\n",
+ "def create_experiment(project_name, params):\n",
+ " # end any prior experiments\n",
+ " if 'experiment' in locals():\n",
+ " experiment.end()\n",
+ "\n",
+ " # initiate the comet experiment for tracking\n",
+ " experiment = comet_ml.Experiment(\n",
+ " api_key=COMET_API_KEY,\n",
+ " project_name=project_name)\n",
+ " # log our hyperparameters, defined above, to the experiment\n",
+ " for param, value in params.items():\n",
+ " experiment.log_parameter(param, value)\n",
+ " experiment.flush()\n",
+ "\n",
+ " return experiment\n"
+ ],
+ "metadata": {
+ "id": "mi-04SAfK6lm"
+ },
"execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
"metadata": {
"id": "eJlDGh1o31G1"
},
- "outputs": [],
"source": [
"### Train the standard CNN ###\n",
"\n",
"# Training hyperparameters\n",
- "batch_size = 32\n",
- "num_epochs = 2 # keep small to run faster\n",
- "learning_rate = 5e-4\n",
+ "params = dict(\n",
+ " batch_size = 32,\n",
+ " num_epochs = 2, # keep small to run faster\n",
+ " learning_rate = 5e-4,\n",
+ ")\n",
+ "\n",
+ "experiment = create_experiment(\"6S191_Lab2_Part2_CNN\", params)\n",
"\n",
- "optimizer = tf.keras.optimizers.Adam(learning_rate) # define our optimizer\n",
+ "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"]) # define our optimizer\n",
"loss_history = mdl.util.LossHistory(smoothing_factor=0.99) # to record loss evolution\n",
"plotter = mdl.util.PeriodicPlotter(sec=2, scale='semilogy')\n",
"if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
@@ -289,31 +353,32 @@
"def standard_train_step(x, y):\n",
" with tf.GradientTape() as tape:\n",
" # feed the images into the model\n",
- " logits = standard_classifier(x) \n",
+ " logits = standard_classifier(x)\n",
" # Compute the loss\n",
" loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=logits)\n",
"\n",
- "\n",
" # Backpropagation\n",
" grads = tape.gradient(loss, standard_classifier.trainable_variables)\n",
" optimizer.apply_gradients(zip(grads, standard_classifier.trainable_variables))\n",
" return loss\n",
"\n",
"# The training loop!\n",
- "for epoch in range(num_epochs):\n",
- " for idx in tqdm(range(loader.get_train_size()//batch_size)):\n",
+ "step = 0\n",
+ "for epoch in range(params[\"num_epochs\"]):\n",
+ " for idx in tqdm(range(loader.get_train_size()//params[\"batch_size\"])):\n",
" # Grab a batch of training data and propagate through the network\n",
- " x, y = loader.get_batch(batch_size)\n",
+ " x, y = loader.get_batch(params[\"batch_size\"])\n",
" loss = standard_train_step(x, y)\n",
"\n",
" # Record the loss and plot the evolution of the loss as a function of training\n",
" loss_history.append(loss.numpy().mean())\n",
- " comet_model_1.log_metric(\"loss\", loss.numpy().mean(), idx)\n",
" plotter.plot(loss_history.get())\n",
"\n",
- "comet_model_1.log_figure(figure=plt)\n",
- "comet_model_1.end()"
- ]
+ " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
+ " step += 1"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -328,11 +393,9 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "35-PDgjdWk6_"
},
- "outputs": [],
"source": [
"### Evaluation of standard CNN ###\n",
"\n",
@@ -343,7 +406,9 @@
"acc_standard = tf.reduce_mean(tf.cast(tf.equal(batch_y, y_pred_standard), tf.float32))\n",
"\n",
"print(\"Standard CNN accuracy on (potentially biased) training set: {:.4f}\".format(acc_standard.numpy()))"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -351,25 +416,84 @@
"id": "Qu7R14KaEEvU"
},
"source": [
- "## 2.3 Diagnosing algorithmic bias\n",
- "\n",
- "CNNs like the one we just built are pervasive as the standard solution for facial detection pipelines implemented throughout society. Despite their pervasiveness, these models -- including those implemented by top tech companies -- suffer from tremendous amounts of algorithmic bias. The seminal work of [Buolamwini and Gebru](https://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf) provided an approach and benchmark dataset to evaluate facial analysis algorithms, revealing startling accuracy discrepancies across skin tone and gender demographics.\n",
- "\n",
- "In order to solve this problem and build fair and robust models, the first step is to determine the source of the problem. How can we determine the ***source*** of these accuracy discrepancies to identify and diagnose biases?\n",
- "\n",
- "### Naive approach\n",
+ "We will also evaluate our networks on an independent test dataset containing faces that were not seen during training. For the test data, we'll look at the classification accuracy across four different demographics, based on the Fitzpatrick skin scale and sex-based labels: dark-skinned male, dark-skinned female, light-skinned male, and light-skinned female.\n",
"\n",
- "A naive approach -- and one that is being adopted by many companies and organizations -- would be to annotate different subclasses (i.e., light-skinned females, males with hats, etc.) within the training data, and then evaluate classifier performance with respect to these groups.\n",
- "\n",
- "But this approach has two major disadvantages. First, it requires annotating massive amounts of data, which is not scalable. Second, it requires that we know what potential biases (e.g., race, gender, pose, occlusion, hats, glasses, etc.) to look for in the data. As a result, manual annotation may not capture all the different sources of bias and uncertainty that may exist.\n",
- "\n",
- "### Automatically uncovering hidden biases\n",
+ "Let's take a look at some sample faces in the test set."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "vfDD8ztGWk6x"
+ },
+ "source": [
+ "### Load test dataset and plot examples ###\n",
+ "\n",
+ "test_faces = mdl.lab2.get_test_faces()\n",
+ "keys = [\"Light Female\", \"Light Male\", \"Dark Female\", \"Dark Male\"]\n",
+ "for group, key in zip(test_faces,keys):\n",
+ " plt.figure(figsize=(5,5))\n",
+ " plt.imshow(np.hstack(group))\n",
+ " plt.title(key, fontsize=15)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "uo1z3cdbEUMM"
+ },
+ "source": [
+ "Now, let's evaluate the probability of each of these face demographics being classified as a face using the standard CNN classifier we've just trained."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "GI4O0Y1GAot9"
+ },
+ "source": [
+ "### Evaluate the standard CNN on the test data ###\n",
+ "\n",
+ "standard_classifier_logits = [standard_classifier(np.array(x, dtype=np.float32)) for x in test_faces]\n",
+ "standard_classifier_probs = tf.squeeze(tf.sigmoid(standard_classifier_logits))\n",
+ "\n",
+ "# Plot the prediction accuracies per demographic\n",
+ "xx = range(len(keys))\n",
+ "yy = standard_classifier_probs.numpy().mean(1)\n",
+ "plt.bar(xx, yy)\n",
+ "plt.xticks(xx, keys)\n",
+ "plt.ylim(max(0,yy.min()-yy.ptp()/2.), yy.max()+yy.ptp()/2.)\n",
+ "plt.title(\"Standard classifier predictions\");"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "j0Cvvt90DoAm"
+ },
+ "source": [
+ "Take a look at the accuracies for this first model across these four groups. What do you observe? Would you consider this model biased or unbiased? What are some reasons why a trained model may have biased accuracies?"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0AKcHnXVtgqJ"
+ },
+ "source": [
+ "## 2.3 Mitigating algorithmic bias\n",
"\n",
"Imbalances in the training data can result in unwanted algorithmic bias. For example, the majority of faces in CelebA (our training set) are those of light-skinned females. As a result, a classifier trained on CelebA will be better suited at recognizing and classifying faces with features similar to these, and will thus be biased.\n",
"\n",
- "What if we actually ***learned*** the distribution of data features in an unbiased, unsupervised manner, without the need for any annotation? What could such an approach tell us about hidden biases that may exist in the data, or regions of the data in which the model is less confident in its predictions?\n",
+ "How could we overcome this? A naive solution -- and one that is being adopted by many companies and organizations -- would be to annotate different subclasses (i.e., light-skinned females, males with hats, etc.) within the training data, and then manually even out the data with respect to these groups.\n",
+ "\n",
+ "But this approach has two major disadvantages. First, it requires annotating massive amounts of data, which is not scalable. Second, it requires that we know what potential biases (e.g., race, gender, pose, occlusion, hats, glasses, etc.) to look for in the data. As a result, manual annotation may not capture all the different features that are imbalanced within the training data.\n",
"\n",
- "In the rest of this lab, we will tackle exactly these questions."
+ "Instead, let's actually **learn** these features in an unbiased, unsupervised manner, without the need for any annotation, and then train a classifier fairly with respect to these features. In the rest of this lab, we'll do exactly that."
]
},
{
@@ -380,15 +504,15 @@
"source": [
"## 2.4 Variational autoencoder (VAE) for learning latent structure\n",
"\n",
- "The accuracy of facial detection classifiers can vary significantly across different demographics. Consider the dataset the CNN model was trained on, CelebA. If certain features, such as dark skin or hats, are *rare* in CelebA, the model may end up biased against these as a result of training with a biased dataset. That is to say, its classification accuracy will be worse on faces that have under-represented features, such as dark-skinned faces or faces with hats, relevative to faces with features well-represented in the training data! This is a problem.\n",
+ "As you saw, the accuracy of the CNN varies across the four demographics we looked at. To think about why this may be, consider the dataset the model was trained on, CelebA. If certain features, such as dark skin or hats, are *rare* in CelebA, the model may end up biased against these as a result of training with a biased dataset. That is to say, its classification accuracy will be worse on faces that have under-represented features, such as dark-skinned faces or faces with hats, relevative to faces with features well-represented in the training data! This is a problem.\n",
"\n",
- "Our goal is to train a model that **learns a representation of the underlying latent space** to the face training data. Such a learned representation will provide information on what features are under-represented or over-represented in the data. The key design requirement for our model is that it can learn an *encoding* of the latent features in the face data in an entirely *unsupervised* way, without any supervised annotation by us humans. To achieve this, we turn to variational autoencoders (VAEs).\n",
+ "Our goal is to train a *debiased* version of this classifier -- one that accounts for potential disparities in feature representation within the training data. Specifically, to build a debiased facial classifier, we'll train a model that **learns a representation of the underlying latent space** to the face training data. The model then uses this information to mitigate unwanted biases by sampling faces with rare features, like dark skin or hats, *more frequently* during training. The key design requirement for our model is that it can learn an *encoding* of the latent features in the face data in an entirely *unsupervised* way. To achieve this, we'll turn to variational autoencoders (VAEs).\n",
"\n",
"\n",
"\n",
- "As shown in the schematic above and in Lecture 4, VAEs rely on an encoder-decoder structure to learn a latent representation of the input data. In the context of computer vision, the encoder network takes in input images, encodes them into a series of variables defined by a mean and standard deviation, and then draws from the distributions defined by these parameters to generate a set of sampled latent variables. The decoder network then \"decodes\" these variables to generate a reconstruction of the original image, which is used during training to help the model identify which latent variables are important to learn. \n",
+ "As shown in the schematic above and in Lecture 4, VAEs rely on an encoder-decoder structure to learn a latent representation of the input data. In the context of computer vision, the encoder network takes in input images, encodes them into a series of variables defined by a mean and standard deviation, and then draws from the distributions defined by these parameters to generate a set of sampled latent variables. The decoder network then \"decodes\" these variables to generate a reconstruction of the original image, which is used during training to help the model identify which latent variables are important to learn.\n",
"\n",
- "Let's formalize two key aspects of the VAE model and define relevant functions for each."
+ "Let's formalize two key aspects of the VAE model and define relevant functions for each.\n"
]
},
{
@@ -428,19 +552,17 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "S00ASo1ImSuh"
},
- "outputs": [],
"source": [
"### Defining the VAE loss function ###\n",
"\n",
"''' Function to calculate VAE loss given:\n",
- " an input x, \n",
- " reconstructed output x_recon, \n",
- " encoded means mu, \n",
- " encoded log of standard deviation logsigma, \n",
+ " an input x,\n",
+ " reconstructed output x_recon,\n",
+ " encoded means mu,\n",
+ " encoded log of standard deviation logsigma,\n",
" weight parameter for the latent loss kl_weight\n",
"'''\n",
"def vae_loss_function(x, x_recon, mu, logsigma, kl_weight=0.0005):\n",
@@ -449,10 +571,10 @@
" latent_loss = 0.5 * tf.reduce_sum(tf.exp(logsigma) + tf.square(mu) - 1.0 - logsigma, axis=1)\n",
" # latent_loss = # TODO\n",
"\n",
- " # TODO: Define the reconstruction loss as the mean absolute pixel-wise \n",
- " # difference between the input and reconstruction. Hint: you'll need to \n",
- " # use tf.reduce_mean, and supply an axis argument which specifies which \n",
- " # dimensions to reduce over. For example, reconstruction loss needs to average \n",
+ " # TODO: Define the reconstruction loss as the mean absolute pixel-wise\n",
+ " # difference between the input and reconstruction. Hint: you'll need to\n",
+ " # use tf.reduce_mean, and supply an axis argument which specifies which\n",
+ " # dimensions to reduce over. For example, reconstruction loss needs to average\n",
" # over the height, width, and channel image dimensions.\n",
" # https://www.tensorflow.org/api_docs/python/tf/math/reduce_mean\n",
" reconstruction_loss = tf.reduce_mean(tf.abs(x-x_recon), axis=(1,2,3))\n",
@@ -462,8 +584,19 @@
" # in the text block directly above\n",
" vae_loss = kl_weight * latent_loss + reconstruction_loss\n",
" # vae_loss = # TODO\n",
- " \n",
+ "\n",
" return vae_loss"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "E8mpb3pJorpu"
+ },
+ "source": [
+ "Great! Now that we have a more concrete sense of how VAEs work, let's explore how we can leverage this network structure to train a *debiased* facial classifier."
]
},
{
@@ -472,9 +605,9 @@
"id": "DqtQH4S5fO8F"
},
"source": [
- "### Understanding VAEs: sampling and reparameterization \n",
+ "### Understanding VAEs: reparameterization\n",
"\n",
- "As you may recall from lecture, VAEs use a \"reparameterization trick\" for sampling learned latent variables. Instead of the VAE encoder generating a single vector of real numbers for each latent variable, it generates a vector of means and a vector of standard deviations that are constrained to roughly follow Gaussian distributions. We then sample a noise value $\\epsilon$ from a Gaussian distribution, and then scale it by the standard deviation and add back the mean to output the result as our sampled latent vector. Formalizing this for a latent variable $z$ where we sample $\\epsilon \\sim N(0,(I))$ we have:\n",
+ "As you may recall from lecture, VAEs use a \"reparameterization trick\" for sampling learned latent variables. Instead of the VAE encoder generating a single vector of real numbers for each latent variable, it generates a vector of means and a vector of standard deviations that are constrained to roughly follow Gaussian distributions. We then sample from the standard deviations and add back the mean to output this as our sampled latent vector. Formalizing this for a latent variable $z$ where we sample $\\epsilon \\sim N(0,(I))$ we have:\n",
"\n",
"$$z = \\mu + e^{\\left(\\frac{1}{2} \\cdot \\log{\\Sigma}\\right)}\\circ \\epsilon$$\n",
"\n",
@@ -485,15 +618,13 @@
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "cT6PGdNajl3K"
},
- "outputs": [],
"source": [
- "### VAE Sampling ###\n",
+ "### VAE Reparameterization ###\n",
"\n",
- "\"\"\"Sample latent variables via reparameterization with an isotropic unit Gaussian.\n",
+ "\"\"\"Reparameterization trick by sampling from an isotropic unit Gaussian.\n",
"# Arguments\n",
" z_mean, z_logsigma (tensor): mean and log of standard deviation of latent distribution (Q(z|X))\n",
"# Returns\n",
@@ -509,16 +640,9 @@
" z = z_mean + tf.math.exp(0.5 * z_logsigma) * epsilon\n",
" # z = # TODO\n",
" return z"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "bcpznUHHuR6I"
- },
- "source": [
- "Great! Now that we have a more concrete sense of how VAEs work, let's explore how we can leverage this network structure to diagnoses hidden biases in facial detection classifiers."
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -526,28 +650,28 @@
"id": "qtHEYI9KNn0A"
},
"source": [
- "## 2.5 Semi-supervised variational autoencoder (SS-VAE)\n",
+ "## 2.5 Debiasing variational autoencoder (DB-VAE)\n",
+ "\n",
+ "Now, we'll use the general idea behind the VAE architecture to build a model, termed a [*debiasing variational autoencoder*](https://lmrt.mit.edu/sites/default/files/AIES-19_paper_220.pdf) or DB-VAE, to mitigate (potentially) unknown biases present within the training idea. We'll train our DB-VAE model on the facial detection task, run the debiasing operation during training, evaluate on the PPB dataset, and compare its accuracy to our original, biased CNN model. \n",
+ "\n",
+ "### The DB-VAE model\n",
"\n",
- "Now, we will use the general idea behind the VAE architecture to build a model to automatically uncover (potentially) unknown biases present within the training data, while simultaneously learning the facial detection task. This draws direct inspiration from [a recent paper](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf) proposing this as a general approach for automatic bias detetion and mitigation.\n"
+ "The key idea behind this debiasing approach is to use the latent variables learned via a VAE to adaptively re-sample the CelebA data during training. Specifically, we will alter the probability that a given image is used during training based on how often its latent features appear in the dataset. So, faces with rarer features (like dark skin, sunglasses, or hats) should become more likely to be sampled during training, while the sampling probability for faces with features that are over-represented in the training dataset should decrease (relative to uniform random sampling across the training data).\n",
+ "\n",
+ "A general schematic of the DB-VAE approach is shown here:\n",
+ "\n",
+ ""
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "A3IOB3d61WSN"
+ "id": "ziA75SN-UxxO"
},
"source": [
- "### Semi-supervised VAE architecture\n",
- "\n",
- "We will develop a VAE that has a supervised component in order to both output a classification decision for the facial detection task and analyze where the biases in our model may be resulting from. While previous works like that of Buolamwini and Gebru have focused on skin tone and gender as two categories where facial detection models may be experiencing bias, there may be other unlabeled features that also are biased, resulting in poorer classification performance. We will build our semi-supervised VAE (SS-VAE) to learn these underlying latent features.\n",
- "\n",
- "A general schematic of the SS-VAE architecture is shown here.\n",
+ "Recall that we want to apply our DB-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the DB-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is another key distinction between the DB-VAE and a traditional VAE.\n",
"\n",
- "\n",
- "\n",
- "We will apply our SS-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the SS-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is the key distinction between the SS-VAE and a traditional VAE. \n",
- "\n",
- "Keep in mind that we only want to learn the latent representation of *faces*, as that is where we are interested in uncovering potential biases, even though we are training a model on a binary classification problem. So, we will need to ensure that, **for faces**, our SS-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, and outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$."
+ "Keep in mind that we only want to learn the latent representation of *faces*, as that's what we're ultimately debiasing against, even though we are training a model on a binary classification problem. We'll need to ensure that, **for faces**, our DB-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, **and** outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$."
]
},
{
@@ -556,35 +680,34 @@
"id": "XggIKYPRtOZR"
},
"source": [
- "### Defining the SS-VAE loss function\n",
+ "### Defining the DB-VAE loss function\n",
"\n",
- "This means we'll need to be a bit clever about the loss function for the SS-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered. \n",
+ "This means we'll need to be a bit clever about the loss function for the DB-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered.\n",
"\n",
"For **face images**, our loss function will have two components:\n",
"\n",
+ "\n",
"1. **VAE loss ($L_{VAE}$)**: consists of the latent loss and the reconstruction loss.\n",
- "2. **Classification loss ($L_y(y,\\hat{y})$)**: standard cross-entropy loss for a binary classification problem. \n",
+ "2. **Classification loss ($L_y(y,\\hat{y})$)**: standard cross-entropy loss for a binary classification problem.\n",
"\n",
- "In contrast, for images of **non-faces**, our loss function is solely the classification loss. \n",
+ "In contrast, for images of **non-faces**, our loss function is solely the classification loss.\n",
"\n",
"We can write a single expression for the loss by defining an indicator variable ${I}_f$which reflects which training data are images of faces (${I}_f(y) = 1$ ) and which are images of non-faces (${I}_f(y) = 0$). Using this, we obtain:\n",
"\n",
"$$L_{total} = L_y(y,\\hat{y}) + {I}_f(y)\\Big[L_{VAE}\\Big]$$\n",
"\n",
- "Let's write a function to define the SS-VAE loss function:\n"
+ "Let's write a function to define the DB-VAE loss function:\n"
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "VjieDs8Ovcqs"
},
- "outputs": [],
"source": [
- "### Loss function for SS-VAE ###\n",
+ "### Loss function for DB-VAE ###\n",
"\n",
- "\"\"\"Loss function for SS-VAE.\n",
+ "\"\"\"Loss function for DB-VAE.\n",
"# Arguments\n",
" x: true input x\n",
" x_pred: reconstructed x\n",
@@ -593,12 +716,12 @@
" mu: mean of latent distribution (Q(z|X))\n",
" logsigma: log of standard deviation of latent distribution (Q(z|X))\n",
"# Returns\n",
- " total_loss: SS-VAE total loss\n",
- " classification_loss: SS-VAE classification loss\n",
+ " total_loss: DB-VAE total loss\n",
+ " classification_loss = DB-VAE classification loss\n",
"\"\"\"\n",
- "def ss_vae_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n",
+ "def debiasing_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n",
"\n",
- " # TODO: call the relevant function to obtain VAE loss, defined earlier in the lab\n",
+ " # TODO: call the relevant function to obtain VAE loss\n",
" vae_loss = vae_loss_function(x, x_pred, mu, logsigma)\n",
" # vae_loss = vae_loss_function('''TODO''') # TODO\n",
"\n",
@@ -611,16 +734,18 @@
" # indicator that reflects which training data are images of faces\n",
" face_indicator = tf.cast(tf.equal(y, 1), tf.float32)\n",
"\n",
- " # TODO: define the SS-VAE total loss! Use tf.reduce_mean to average over all\n",
+ " # TODO: define the DB-VAE total loss! Use tf.reduce_mean to average over all\n",
" # samples\n",
" total_loss = tf.reduce_mean(\n",
- " classification_loss + \n",
+ " classification_loss +\n",
" face_indicator * vae_loss\n",
" )\n",
" # total_loss = # TODO\n",
"\n",
- " return total_loss, classification_loss, vae_loss"
- ]
+ " return total_loss, classification_loss"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -628,25 +753,25 @@
"id": "YIu_2LzNWwWY"
},
"source": [
- "### Defining the SS-VAE architecture\n",
+ "### DB-VAE architecture\n",
"\n",
- "Now we're ready to define the SS-VAE architecture. To build the SS-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the encoder and decoder networks, and then construct the end-to-end VAE. We will use a latent space with 32 latent variables.\n",
+ "Now we're ready to define the DB-VAE architecture. To build the DB-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the two models, and then construct the end-to-end VAE. We will use a latent space with 100 latent variables.\n",
"\n",
"The decoder network will take as input the sampled latent variables, run them through a series of deconvolutional layers, and output a reconstruction of the original input image."
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "JfWPHGrmyE7R"
},
- "outputs": [],
"source": [
- "### Define the decoder portion of the SS-VAE ###\n",
+ "### Define the decoder portion of the DB-VAE ###\n",
"\n",
- "def make_face_decoder_network(n_filters=12):\n",
+ "n_filters = 12 # base number of convolutional filters, same as standard CNN\n",
+ "latent_dim = 100 # number of latent variables\n",
"\n",
+ "def make_face_decoder_network():\n",
" # Functionally define the different layer types we will use\n",
" Conv2DTranspose = functools.partial(tf.keras.layers.Conv2DTranspose, padding='same', activation='relu')\n",
" BatchNormalization = tf.keras.layers.BatchNormalization\n",
@@ -668,7 +793,9 @@
" ])\n",
"\n",
" return decoder"
- ]
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -676,26 +803,24 @@
"id": "yWCMu12w1BuD"
},
"source": [
- "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the SS-VAE. Here, we will define the core VAE architecture by sublassing the `Model` class; defining encoding, sampling, and decoding operations; and calling the network end-to-end."
+ "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the DB-VAE. Note that at this point, there is nothing special about how we put the model together that makes it a \"debiasing\" model -- that will come when we define the training operation. Here, we will define the core VAE architecture by sublassing the `Model` class; defining encoding, reparameterization, and decoding operations; and calling the network end-to-end."
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
"id": "dSFDcFBL13c3"
},
- "outputs": [],
"source": [
- "### Defining and creating the SS-VAE ###\n",
+ "### Defining and creating the DB-VAE ###\n",
"\n",
- "class SS_VAE(tf.keras.Model):\n",
+ "class DB_VAE(tf.keras.Model):\n",
" def __init__(self, latent_dim):\n",
- " super(SS_VAE, self).__init__()\n",
+ " super(DB_VAE, self).__init__()\n",
" self.latent_dim = latent_dim\n",
"\n",
- " # Define the number of outputs for the encoder. Recall that we have \n",
- " # `latent_dim` latent variables, as well as a supervised output for the \n",
+ " # Define the number of outputs for the encoder. Recall that we have\n",
+ " # `latent_dim` latent variables, as well as a supervised output for the\n",
" # classification.\n",
" num_encoder_dims = 2*self.latent_dim + 1\n",
"\n",
@@ -703,7 +828,7 @@
" self.decoder = make_face_decoder_network()\n",
"\n",
" # function to feed images into encoder, encode the latent space, and output\n",
- " # classification probability \n",
+ " # classification probability\n",
" def encode(self, x):\n",
" # encoder output\n",
" encoder_output = self.encoder(x)\n",
@@ -711,26 +836,32 @@
" # classification prediction\n",
" y_logit = tf.expand_dims(encoder_output[:, 0], -1)\n",
" # latent variable distribution parameters\n",
- " z_mean = encoder_output[:, 1:self.latent_dim+1] \n",
+ " z_mean = encoder_output[:, 1:self.latent_dim+1]\n",
" z_logsigma = encoder_output[:, self.latent_dim+1:]\n",
"\n",
" return y_logit, z_mean, z_logsigma\n",
"\n",
+ " # VAE reparameterization: given a mean and logsigma, sample latent variables\n",
+ " def reparameterize(self, z_mean, z_logsigma):\n",
+ " # TODO: call the sampling function defined above\n",
+ " z = sampling(z_mean, z_logsigma)\n",
+ " # z = # TODO\n",
+ " return z\n",
+ "\n",
" # Decode the latent space and output reconstruction\n",
" def decode(self, z):\n",
- " # TODO: use the decoder (self.decoder) to output the reconstruction\n",
+ " # TODO: use the decoder to output the reconstruction\n",
" reconstruction = self.decoder(z)\n",
" # reconstruction = # TODO\n",
" return reconstruction\n",
"\n",
" # The call function will be used to pass inputs x through the core VAE\n",
- " def call(self, x): \n",
+ " def call(self, x):\n",
" # Encode input to a prediction and latent space\n",
" y_logit, z_mean, z_logsigma = self.encode(x)\n",
"\n",
- " # TODO: call the sampling function that you created above using \n",
- " # z_mean and z_logsigma\n",
- " z = sampling(z_mean, z_logsigma)\n",
+ " # TODO: reparameterization\n",
+ " z = self.reparameterize(z_mean, z_logsigma)\n",
" # z = # TODO\n",
"\n",
" # TODO: reconstruction\n",
@@ -743,8 +874,10 @@
" y_logit, z_mean, z_logsigma = self.encode(x)\n",
" return y_logit\n",
"\n",
- "ss_vae = SS_VAE(latent_dim=32)"
- ]
+ "dbvae = DB_VAE(latent_dim)"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -752,7 +885,7 @@
"id": "M-clbYAj2waY"
},
"source": [
- "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed SS-VAE model in the `call` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n",
+ "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed DB_VAE model in the `call` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n",
"\n"
]
},
@@ -762,279 +895,242 @@
"id": "nbDNlslgQc5A"
},
"source": [
- "### Training the SS-VAE\n",
+ "### Adaptive resampling for automated debiasing with DB-VAE\n",
+ "\n",
+ "So, how can we actually use DB-VAE to train a debiased facial detection classifier?\n",
+ "\n",
+ "Recall the DB-VAE architecture: as input images are fed through the network, the encoder learns an estimate ${Q}(z|X)$ of the latent space. We want to increase the relative frequency of rare data by increased sampling of under-represented regions of the latent space. We can approximate ${Q}(z|X)$ using the frequency distributions of each of the learned latent variables, and then define the probability distribution of selecting a given datapoint $x$ based on this approximation. These probability distributions will be used during training to re-sample the data.\n",
"\n",
- "We are ready to train our SS-VAE model! Complete the `TODO`s in the following training loop to train the SS-VAE with face classification output."
+ "You'll write a function to execute this update of the sampling probabilities, and then call this function within the DB-VAE training loop to actually debias the model."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Fej5FDu37cf7"
+ },
+ "source": [
+ "First, we've defined a short helper function `get_latent_mu` that returns the latent variable means returned by the encoder after a batch of images is inputted to the network:"
]
},
{
"cell_type": "code",
+ "metadata": {
+ "id": "ewWbf7TE7wVc"
+ },
+ "source": [
+ "# Function to return the means for an input image batch\n",
+ "def get_latent_mu(images, dbvae, batch_size=1024):\n",
+ " N = images.shape[0]\n",
+ " mu = np.zeros((N, latent_dim))\n",
+ " for start_ind in range(0, N, batch_size):\n",
+ " end_ind = min(start_ind+batch_size, N+1)\n",
+ " batch = (images[start_ind:end_ind]).astype(np.float32)/255.\n",
+ " _, batch_mu, _ = dbvae.encode(batch)\n",
+ " mu[start_ind:end_ind] = batch_mu\n",
+ " return mu"
+ ],
"execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
"metadata": {
- "id": "xwQs-Gu5bKEK"
+ "id": "wn4yK3SC72bo"
},
- "outputs": [],
"source": [
- "### Training the SS-VAE ###\n",
+ "Now, let's define the actual resampling algorithm `get_training_sample_probabilities`. Importantly note the argument `smoothing_fac`. This parameter tunes the degree of debiasing: for `smoothing_fac=0`, the re-sampled training set will tend towards falling uniformly over the latent space, i.e., the most extreme debiasing."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "HiX9pmmC7_wn"
+ },
+ "source": [
+ "### Resampling algorithm for DB-VAE ###\n",
"\n",
- "comet_ml.init(project_name=\"6.s191lab2_part2_VAE\")\n",
- "comet_model_2 = comet_ml.Experiment()\n",
+ "'''Function that recomputes the sampling probabilities for images within a batch\n",
+ " based on how they distribute across the training data'''\n",
+ "def get_training_sample_probabilities(images, dbvae, bins=10, smoothing_fac=0.001):\n",
+ " print(\"Recomputing the sampling probabilities\")\n",
"\n",
- "# Hyperparameters\n",
- "batch_size = 32\n",
- "learning_rate = 5e-4\n",
- "latent_dim = 32\n",
+ " # TODO: run the input batch and get the latent variable means\n",
+ " mu = get_latent_mu(images, dbvae)\n",
+ " # mu = get_latent_mu('''TODO''') # TODO\n",
"\n",
- "# SS-VAE needs slightly more epochs to train since its more complex than \n",
- "# the standard classifier so we use 6 instead of 2\n",
- "num_epochs = 6\n",
+ " # sampling probabilities for the images\n",
+ " training_sample_p = np.zeros(mu.shape[0])\n",
"\n",
- "# instantiate a new SS-VAE model and optimizer\n",
- "ss_vae = SS_VAE(latent_dim)\n",
- "optimizer = tf.keras.optimizers.Adam(learning_rate)\n",
+ " # consider the distribution for each latent variable\n",
+ " for i in range(latent_dim):\n",
"\n",
- "# To define the training operation, we will use tf.function which is a powerful tool \n",
- "# that lets us turn a Python function into a TensorFlow computation graph.\n",
- "@tf.function\n",
- "def ss_vae_train_step(x, y):\n",
+ " latent_distribution = mu[:,i]\n",
+ " # generate a histogram of the latent distribution\n",
+ " hist_density, bin_edges = np.histogram(latent_distribution, density=True, bins=bins)\n",
"\n",
- " with tf.GradientTape() as tape:\n",
- " # Feed input x into ss_vae. Note that this is using the SS_VAE call function!\n",
- " y_logit, z_mean, z_logsigma, x_recon = ss_vae(x)\n",
+ " # find which latent bin every data sample falls in\n",
+ " bin_edges[0] = -float('inf')\n",
+ " bin_edges[-1] = float('inf')\n",
"\n",
- " '''TODO: call the SS_VAE loss function to compute the loss'''\n",
- " loss, class_loss, _ = ss_vae_loss_function(x, x_recon, y, y_logit, z_mean, z_logsigma)\n",
- " # loss, class_loss = ss_vae_loss_function('''TODO arguments''') # TODO\n",
- " \n",
- " '''TODO: use the GradientTape.gradient method to compute the gradients.\n",
- " Hint: this is with respect to the trainable_variables of the SS_VAE.'''\n",
- " grads = tape.gradient(loss, ss_vae.trainable_variables)\n",
- " # grads = tape.gradient('''TODO''', '''TODO''') # TODO\n",
+ " # TODO: call the digitize function to find which bins in the latent distribution\n",
+ " # every data sample falls in to\n",
+ " # https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.digitize.html\n",
+ " bin_idx = np.digitize(latent_distribution, bin_edges)\n",
+ " # bin_idx = np.digitize('''TODO''', '''TODO''') # TODO\n",
"\n",
- " # apply gradients to variables\n",
- " optimizer.apply_gradients(zip(grads, ss_vae.trainable_variables))\n",
- " return loss\n",
+ " # smooth the density function\n",
+ " hist_smoothed_density = hist_density + smoothing_fac\n",
+ " hist_smoothed_density = hist_smoothed_density / np.sum(hist_smoothed_density)\n",
"\n",
- "# get training faces from data loader\n",
- "all_faces = loader.get_all_train_faces()\n",
+ " # invert the density function\n",
+ " p = 1.0/(hist_smoothed_density[bin_idx-1])\n",
"\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
+ " # TODO: normalize all probabilities\n",
+ " p = p / np.sum(p)\n",
+ " # p = # TODO\n",
"\n",
- "# The training loop -- outer loop iterates over the number of epochs\n",
- "for i in range(num_epochs):\n",
+ " # TODO: update sampling probabilities by considering whether the newly\n",
+ " # computed p is greater than the existing sampling probabilities.\n",
+ " training_sample_p = np.maximum(p, training_sample_p)\n",
+ " # training_sample_p = # TODO\n",
"\n",
- " # IPython.display.clear_output(wait=True)\n",
- " print(\"Starting epoch {}/{}\".format(i+1, num_epochs))\n",
- " \n",
- " # get a batch of training data and compute the training step\n",
- " for j in tqdm(range(loader.get_train_size() // batch_size)):\n",
- " # load a batch of data\n",
- " (x, y) = loader.get_batch(batch_size)\n",
- " # loss optimization\n",
- " loss = ss_vae_train_step(x, y)\n",
- " comet_model_2.log_metric(\"loss\", loss, step=j)\n",
- " \n",
- " # plot the progress every 200 steps\n",
- " if j % 500 == 0: \n",
- " mdl.util.plot_sample(x, y, ss_vae)"
- ]
+ " # final normalization\n",
+ " training_sample_p /= np.sum(training_sample_p)\n",
+ "\n",
+ " return training_sample_p"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
"metadata": {
- "id": "uZBlWDPOVcHg"
+ "id": "pF14fQkVUs-a"
},
"source": [
- "Wonderful! Now we should have a trained SS-VAE facial classification model, ready for evaluation!"
+ "Now that we've defined the resampling update, we can train our DB-VAE model on the CelebA/ImageNet training data, and run the above operation to re-weight the importance of particular data points as we train the model. Remember again that we only want to debias for features relevant to *faces*, not the set of negative examples. Complete the code block below to execute the training loop!"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
"metadata": {
- "id": "Eo34xC7MbaiQ"
+ "id": "xwQs-Gu5bKEK"
},
"source": [
- "## 2.6 Using the SS-VAE to uncover and diagnose biases\n",
+ "### Training the DB-VAE ###\n",
"\n",
- "With the SS-VAE model trained, we are ready to use it to uncover and diagnose hidden biases that exist within the dataset.\n",
- "\n",
- "Recall that our goal with the SS-VAE was to learn the underlying ***latent distribution*** of features in the training dataset, in order to uncover potential feature representation disparities that exist within the data.\n",
+ "# Hyperparameters\n",
+ "params = dict(\n",
+ " batch_size = 32,\n",
+ " learning_rate = 5e-4,\n",
+ " latent_dim = 100,\n",
+ " num_epochs = 1, #DB-VAE needs slightly more epochs to train\n",
+ ")\n",
"\n",
- "Additionally, training the SS-VAE required both a VAE reconstruction loss as well as a supervised classification loss. The VAE reconstruction loss direclty reflects how well the model is able to handle particular input data -- the higher the reconstruction loss, the harder that particular example is for the model to learn.\n",
+ "experiment = create_experiment(\"6S191_Lab2_Part2_DBVAE\", params)\n",
"\n",
- "We consider both these aspects to understand sources of uncertainty and bias within the model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "QfVngr5J6sj3"
- },
- "source": [
- "### Linking model performance to uncertainty and bias\n",
+ "# instantiate a new DB-VAE model and optimizer\n",
+ "dbvae = DB_VAE(params[\"latent_dim\"])\n",
+ "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"])\n",
"\n",
- "We begin by considering the examples in the dataset with the highest loss. What can you tell about which features seemed harder to learn for the VAE? What might this tell us about where the model struggles, and what predictions it may be more biased or uncertain about?\n",
+ "# To define the training operation, we will use tf.function which is a powerful tool\n",
+ "# that lets us turn a Python function into a TensorFlow computation graph.\n",
+ "@tf.function\n",
+ "def debiasing_train_step(x, y):\n",
"\n",
- "#### **TODO: Analysis and reflection**\n",
+ " with tf.GradientTape() as tape:\n",
+ " # Feed input x into dbvae. Note that this is using the DB_VAE call function!\n",
+ " y_logit, z_mean, z_logsigma, x_recon = dbvae(x)\n",
"\n",
- "Complete the analysis in the code block below. Write short (~1 sentence) answers to the following questions and include them in your Debiasing Faces Lab submission to complete the `TODO`s!\n",
+ " '''TODO: call the DB_VAE loss function to compute the loss'''\n",
+ " loss, class_loss = debiasing_loss_function(x, x_recon, y, y_logit, z_mean, z_logsigma)\n",
+ " # loss, class_loss = debiasing_loss_function('''TODO arguments''') # TODO\n",
"\n",
- "1. What, if any, trends do you observe comparing the samples with the highest and lowest reconstruction loss?\n",
- "2. Based on these observations, which features seemed harder to learn for the VAE?\n",
- "3. How does reconstruction loss relate to uncertainty? Think back to our lecture on Robust & Trustworthy Deep Learning! What can you say about examples on which the model may be more or less uncertain?"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "BRAwm0Jlrktc"
- },
- "outputs": [],
- "source": [
- "### Linking model performance to uncertainty and bias\n",
+ " '''TODO: use the GradientTape.gradient method to compute the gradients.\n",
+ " Hint: this is with respect to the trainable_variables of the dbvae.'''\n",
+ " grads = tape.gradient(loss, dbvae.trainable_variables)\n",
+ " # grads = tape.gradient('''TODO''', '''TODO''') # TODO\n",
"\n",
- "# Load a random sample of 5000 faces from our dataset and compute the model performance on them\n",
- "(x, y) = loader.get_batch(5000, only_faces=True)\n",
- "y_logit, z_mean, z_logsigma, x_recon = ss_vae(x)\n",
- "loss, class_loss, vae_loss = ss_vae_loss_function(x, x_recon, y, y_logit, z_mean, z_logsigma)\n",
+ " # apply gradients to variables\n",
+ " optimizer.apply_gradients(zip(grads, dbvae.trainable_variables))\n",
+ " return loss\n",
"\n",
- "# Sort the results by the vae loss scores\n",
- "vae_loss = vae_loss.numpy()\n",
- "ind = np.argsort(vae_loss, axis=None)\n",
+ "# get training faces from data loader\n",
+ "all_faces = loader.get_all_train_faces()\n",
"\n",
- "# Plot the 25 samples with the highest and lowest reconstruction losses\n",
- "fig, ax = plt.subplots(1, 2, figsize=(16, 8))\n",
- "ax[0].imshow(mdl.util.create_grid_of_images(x[ind[:25]]))\n",
- "ax[0].set_title(\"Samples with the lowest reconstruction loss \\n\" + \n",
- " f\"Average recon loss: {np.mean(vae_loss[ind[:25]]):.2f}\")\n",
+ "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
"\n",
- "ax[1].imshow(mdl.util.create_grid_of_images(x[ind[-25:]]))\n",
- "ax[1].set_title(\"Samples with the highest reconstruction loss \\n\" + \n",
- " f\"Average recon loss: {np.mean(vae_loss[ind[-25:]]):.2f}\");\n",
+ "# The training loop -- outer loop iterates over the number of epochs\n",
+ "step = 0\n",
+ "for i in range(params[\"num_epochs\"]):\n",
"\n",
- "comet_model_2.log_figure()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "8SQSszTFjstZ"
- },
- "source": [
- "### Uncovering hidden biases through learned latent features \n",
+ " IPython.display.clear_output(wait=True)\n",
+ " print(\"Starting epoch {}/{}\".format(i+1, params[\"num_epochs\"]))\n",
"\n",
- "As we've seen above, loss is a powerful way to visualize which samples in our dataset the model has had trouble learning -- these examples are those that have high *model uncertainty*. However, this is not necessarily the same as bias!\n",
+ " # Recompute data sampling proabilities\n",
+ " '''TODO: recompute the sampling probabilities for debiasing'''\n",
+ " p_faces = get_training_sample_probabilities(all_faces, dbvae)\n",
+ " # p_faces = get_training_sample_probabilities('''TODO''', '''TODO''') # TODO\n",
"\n",
- "How can we determine the relative frequencies and distributions of different latent features learned by the model? How may these metrics reveal underlying biases?\n",
+ " # get a batch of training data and compute the training step\n",
+ " for j in tqdm(range(loader.get_train_size() // params[\"batch_size\"])):\n",
+ " # load a batch of data\n",
+ " (x, y) = loader.get_batch(params[\"batch_size\"], p_pos=p_faces)\n",
"\n",
- "Let's investigate how well the SS-VAE actually learned the latent features of the faces. To do this, we will inspect individual latent features -- holding all others constant -- and look at the distribution of these features in the data and their corresponding examples. We can examine the shape and probability density of the learned latent features. Further we directly compare different values of individual latent variables to corresponding relative classification accuracies (marginalizing out the effects of the other latent variables).\n",
+ " # loss optimization\n",
+ " loss = debiasing_train_step(x, y)\n",
+ " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
"\n",
- "#### **TODO: Analysis and reflection**\n",
+ " # plot the progress every 200 steps\n",
+ " if j % 500 == 0:\n",
+ " mdl.util.plot_sample(x, y, dbvae)\n",
"\n",
- "Complete the analysis in the code blocks below. Carefully inspect the different latent variables and their corresponding frequency distributions. Write short (~1 sentence) answers to the following questions and include them in your Debiasing Faces Lab submission to complete the `TODO`s!\n",
+ " step += 1\n",
"\n",
- "1. Pick two latent variables and describe what semantic meaning they reflect. Include screenshots of the realizations and probability distribution for the latent variables you select.\n",
- "2. For the latent variables selected, what can you tell about which features are under- or over-represented in the data? What might this tell us about how the model is biased?\n",
- "3. For the latent variables selected, how do these feature distribution differences affect classification performance? What, if any, general trends do you observe across the latent variables?\n",
- "4. Based on these observations, please describe your understanding of the bias of the facial detection classifier."
- ]
+ "experiment.end()"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "cellView": "form",
- "id": "8qcR9uvfCJku"
+ "id": "uZBlWDPOVcHg"
},
- "outputs": [],
"source": [
- "### Inspect different latent features\n",
- "\n",
- "#@title Change the sliders to inspect different latent features! { run: \"auto\" }\n",
- "idx_latent = 8 #@param {type:\"slider\", min:0, max:31, step:1}\n",
- "num_steps = 15\n",
- "\n",
- "# Extract all latent samples from the desired dimension\n",
- "latent_samples = z_mean[:, idx_latent]\n",
- "\n",
- "# Compute their density and plot\n",
- "density, latent_bins = np.histogram(latent_samples, num_steps, density=True)\n",
- "fig, ax = plt.subplots(2, 1, figsize=(15, 4))\n",
- "ax[0].bar(latent_bins[1:], density)\n",
- "ax[0].set_ylabel(\"Data density\")\n",
- "\n",
- "# Visualize reconstructions as we walk across the latent space\n",
- "latent_steps = np.linspace(np.min(latent_samples), np.max(latent_samples), num_steps)\n",
- "baseline_latent = tf.reduce_mean(z_mean, 0, keepdims=True)\n",
- "\n",
- "recons = []\n",
- "for step in latent_steps: \n",
- " # Adjust the latent vector according to our step\n",
- " latent = baseline_latent.numpy()\n",
- " latent[0, idx_latent] = step\n",
- " # Decode the reconstruction and store\n",
- " recons.append(ss_vae.decode(latent)[0])\n",
- "\n",
- "# Visualize all of the reconstructions!\n",
- "ax[1].imshow(mdl.util.create_grid_of_images(recons, (1, num_steps)))\n",
- "ax[1].set_xlabel(\"Latent step\")\n",
- "ax[1].set_ylabel(\"Visualization\");\n",
- "\n",
- "comet_model_2.log_figure()"
+ "Wonderful! Now we should have a trained and (hopefully!) debiased facial classification model, ready for evaluation!"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "3ExRRPO2z27z"
+ "id": "Eo34xC7MbaiQ"
},
"source": [
+ "## 2.6 Evaluation of DB-VAE on Test Dataset\n",
"\n",
- "### Inspect how the accuracy changes as a function of density in the latent space\n"
+ "Finally let's test our DB-VAE model on the test dataset, looking specifically at its accuracy on each the \"Dark Male\", \"Dark Female\", \"Light Male\", and \"Light Female\" demographics. We will compare the performance of this debiased model against the (potentially biased) standard CNN from earlier in the lab."
]
},
{
"cell_type": "code",
- "execution_count": null,
"metadata": {
- "id": "PnmPXmkGLBVU"
+ "id": "bgK77aB9oDtX"
},
- "outputs": [],
"source": [
- "### Accuracy vs. density in latent space\n",
- "\n",
- "# Loop through every latent dimension\n",
- "avg_logit_per_bin = []\n",
- "for idx_latent in range(latent_dim): \n",
- " latent_samples = z_mean[:, idx_latent]\n",
- " start = np.percentile(latent_samples, 5)\n",
- " end = np.percentile(latent_samples, 95)\n",
- " latent_steps = np.linspace(start, end, num_steps)\n",
- "\n",
- " # Find which samples fall in which bin of the latent dimension\n",
- " which_latent_bin = np.digitize(latent_samples, latent_steps)\n",
- " \n",
- " # For each latent bin, compute the accuracy (average logit score)\n",
- " avg_logit = []\n",
- " for j in range(0, num_steps+1): \n",
- " inds_in_bin = np.where(which_latent_bin == j)\n",
- " avg_logit.append(y_logit.numpy()[inds_in_bin].mean())\n",
- "\n",
- " avg_logit_per_bin.append(avg_logit)\n",
- " \n",
- "# Average the results across all latent dimensions and all samples\n",
- "accuracy_per_latent = np.mean(avg_logit_per_bin, 0)\n",
- "accuracy_per_latent = (accuracy_per_latent - accuracy_per_latent.min()) / np.ptp(accuracy_per_latent)\n",
- "\n",
- "# Plot the results\n",
- "plt.plot(np.linspace(np.min(z_mean), np.max(z_mean), num_steps+1), accuracy_per_latent,'-o')\n",
- "plt.xlabel(\"Latent step\")\n",
- "plt.ylabel(\"Relative accuracy\")\n",
- "\n",
- "comet_model_2.log_figure()\n",
- "comet_model_2.end()"
- ]
+ "dbvae_logits = [dbvae.predict(np.array(x, dtype=np.float32)) for x in test_faces]\n",
+ "dbvae_probs = tf.squeeze(tf.sigmoid(dbvae_logits))\n",
+ "\n",
+ "xx = np.arange(len(keys))\n",
+ "plt.bar(xx, standard_classifier_probs.numpy().mean(1), width=0.2, label=\"Standard CNN\")\n",
+ "plt.bar(xx+0.2, dbvae_probs.numpy().mean(1), width=0.2, label=\"DB-VAE\")\n",
+ "plt.xticks(xx, keys);\n",
+ "plt.title(\"Network predictions on test dataset\")\n",
+ "plt.ylabel(\"Probability\"); plt.legend(bbox_to_anchor=(1.04,1), loc=\"upper left\");\n"
+ ],
+ "execution_count": null,
+ "outputs": []
},
{
"cell_type": "markdown",
@@ -1042,79 +1138,29 @@
"id": "rESoXRPQo_mq"
},
"source": [
- "## 2.8 Conclusion and submission information\n",
- "\n",
- "**To be eligible for the Debiasing Faces Lab prize, you must submit a document of your answers to the short-answer `TODO`s with your complete lab submission.** Please see the short-answer `TODO`s replicated again here:\n",
+ "## 2.7 Conclusion and submission information\n",
"\n",
- "#### **TODO: Linking model performance to uncertainty and bias**\n",
+ "We encourage you to think about and maybe even address some questions raised by the approach and results outlined here:\n",
"\n",
- "1. What, if any, trends do you observe comparing the samples with the highest and lowest reconstruction loss?\n",
- "2. Based on these observations, which features seemed harder to learn for the VAE?\n",
- "3. How does reconstruction loss relate to uncertainty? Think back to our lecture on Robust & Trustworthy Deep Learning! What can you say about examples on which the model may be more or less uncertain?\n",
- "\n",
- "#### **TODO: Uncovering hidden biases through learned latent features**\n",
+ "* How does the accuracy of the DB-VAE across the four demographics compare to that of the standard CNN? Do you find this result surprising in any way?\n",
+ "* How can the performance of the DB-VAE classifier be improved even further? We purposely did not optimize hyperparameters to leave this up to you!\n",
+ "* In which applications (either related to facial detection or not!) would debiasing in this way be desired? Are there applications where you may not want to debias your model?\n",
+ "* Do you think it should be necessary for companies to demonstrate that their models, particularly in the context of tasks like facial detection, are not biased? If so, do you have thoughts on how this could be standardized and implemented?\n",
+ "* Do you have ideas for other ways to address issues of bias, particularly in terms of the training data?\n",
"\n",
- "1. Pick two latent variables and describe what semantic meaning they reflect. Include screenshots of the realizations and probability distribution for the latent variables you select.\n",
- "2. For the latent variables selected, what can you tell about which features are under- or over-represented in the data? What might this tell us about how the model is biased?\n",
- "3. For the latent variables selected, how do these feature distribution differences affect classification performance? What, if any, general trends do you observe across the latent variables?\n",
- "4. Based on these observations, please describe your understanding of the bias of the facial detection classifier.\n",
+ "**Try to optimize your model to achieve improved performance. To enter the competition, please upload the following to the lab submission site for the Debiasing Faces Lab ([submission upload link](https://www.dropbox.com/request/KGct8m2IyOBVvIoQdef3)).**\n",
"\n",
- "**To enter the competition, you must upload a document write-up as part of your complete lab submission for the Debiasing Faces Lab ([submission upload link](https://www.dropbox.com/request/TTYz3Ikx5wIgOITmm5i2)).** Complete details on submission are included in the next lab!\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mPRZReq4p68k"
- },
- "source": [
- "## 2.9 Thinking ahead\n",
+ "* Jupyter notebook with the code you used to generate your results;\n",
+ "* copy of the bar plot from section 2.6 showing the performance of your model;\n",
+ "* a written description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description;\n",
+ "* a written discussion of why these modifications helped improve performance.\n",
"\n",
- "Beyond this, we encourage you to think about the following questions as you prepare for the next lab, which will focus on mitigating the issues of bias and uncertainty that you just uncovered. Consider:\n",
- "* How do the samples with highest reconstruction loss and samples with highest bias compare? Which features is each one highlighting? Why do you think this is?\n",
- "* In what ways is the dataset biased so far? Can you imagine other features that the dataset is biased against that we have not uncovered yet?\n",
- "* How can the performance of the supervised VAE classifier be improved?\n",
- "* Do you have ideas for other ways to address issues of bias, particularly in terms of the training data?\n",
+ "**Name your file in the following format: `[FirstName]_[LastName]_Face`, followed by the file format (.zip, .ipynb, .pdf, etc).** ZIP files are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature (e.g., `[FirstName]_[LastName]_Face_TODO.pdf`, `[FirstName]_[LastName]_Face_Report.pdf`, etc.).\n",
"\n",
"Hopefully this lab has shed some light on a few concepts, from vision based tasks, to VAEs, to algorithmic bias. We like to think it has, but we're biased ;).\n",
"\n",
""
]
}
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "Ag_e7xtTzT1W",
- "NDj7KBaW8Asz"
- ],
- "provenance": []
- },
- "gpuClass": "standard",
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.9.6"
- },
- "vscode": {
- "interpreter": {
- "hash": "7812ea015bdcee6f23a998adcdd2ef97c151c0c241b7b7070987d9313e41299d"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
+ ]
+}
\ No newline at end of file