# DeepRL
> If you have any question or want to report a bug, please open an issue instead of emailing me directly.
Modularized implementation of popular deep RL algorithms in PyTorch.
Easy switch between toy tasks and challenging games.
Implemented algorithms:
* (Double/Dueling/Prioritized) Deep Q-Learning (DQN)
* Categorical DQN (C51)
* Quantile Regression DQN (QR-DQN)
* (Continuous/Discrete) Synchronous Advantage Actor Critic (A2C)
* Synchronous N-Step Q-Learning (N-Step DQN)
* Deep Deterministic Policy Gradient (DDPG)
* Proximal Policy Optimization (PPO)
* The Option-Critic Architecture (OC)
* Twined Delayed DDPG (TD3)
* [Off-PAC-KL/TruncatedETD/DifferentialGQ/MVPI/ReverseRL/COF-PAC/GradientDICE/Bi-Res-DDPG/DAC/Geoff-PAC/QUOTA/ACE](#code-of-my-papers)
The DQN agent, as well as C51 and QR-DQN, has an asynchronous actor for data generation and an asynchronous replay buffer for transferring data to GPU.
Using 1 RTX 2080 Ti and 3 threads, the DQN agent runs for 10M steps (40M frames, 2.5M gradient updates) for Breakout within 6 hours.
# Dependency
* PyTorch v1.5.1
* See ```Dockerfile``` and ```requirements.txt``` for more details
# Usage
```examples.py``` contains examples for all the implemented algorithms.
```Dockerfile``` contains the environment for generating the curves below.
Please use this bibtex if you want to cite this repo
```
@misc{deeprl,
author = {Zhang, Shangtong},
title = {Modularized Implementation of Deep RL Algorithms in PyTorch},
year = {2018},
publisher = {GitHub},
journal = {GitHub Repository},
howpublished = {\url{https://github.com/ShangtongZhang/DeepRL}},
}
```
# Curves (commit ```9e811e```)
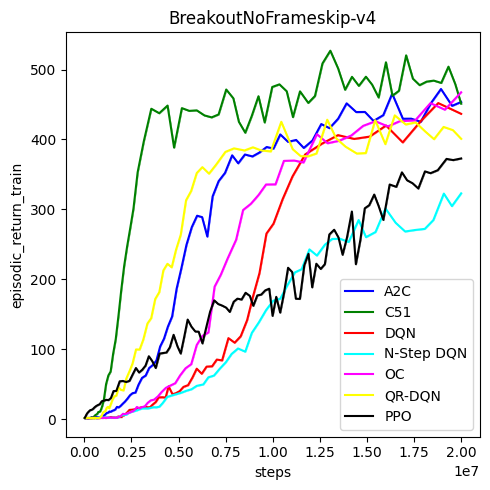
## BreakoutNoFrameskip-v4 (1 run)
## Mujoco
* DDPG/TD3 evaluation performance.

(5 runs, mean + standard error)
* PPO online performance.

(5 runs, mean + standard error, smoothed by a window of size 10)
# References
* [Human Level Control through Deep Reinforcement Learning](https://www.nature.com/nature/journal/v518/n7540/full/nature14236.html)
* [Asynchronous Methods for Deep Reinforcement Learning](https://arxiv.org/abs/1602.01783)
* [Deep Reinforcement Learning with Double Q-learning](https://arxiv.org/abs/1509.06461)
* [Dueling Network Architectures for Deep Reinforcement Learning](https://arxiv.org/abs/1511.06581)
* [Playing Atari with Deep Reinforcement Learning](https://arxiv.org/abs/1312.5602)
* [HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent](https://arxiv.org/abs/1106.5730)
* [Deterministic Policy Gradient Algorithms](http://proceedings.mlr.press/v32/silver14.pdf)
* [Continuous control with deep reinforcement learning](https://arxiv.org/abs/1509.02971)
* [High-Dimensional Continuous Control Using Generalized Advantage Estimation](https://arxiv.org/abs/1506.02438)
* [Hybrid Reward Architecture for Reinforcement Learning](https://arxiv.org/abs/1706.04208)
* [Trust Region Policy Optimization](https://arxiv.org/abs/1502.05477)
* [Proximal Policy Optimization Algorithms](https://arxiv.org/abs/1707.06347)
* [Emergence of Locomotion Behaviours in Rich Environments](https://arxiv.org/abs/1707.02286)
* [Action-Conditional Video Prediction using Deep Networks in Atari Games](https://arxiv.org/abs/1507.08750)
* [A Distributional Perspective on Reinforcement Learning](https://arxiv.org/abs/1707.06887)
* [Distributional Reinforcement Learning with Quantile Regression](https://arxiv.org/abs/1710.10044)
* [The Option-Critic Architecture](https://arxiv.org/abs/1609.05140)
* [Addressing Function Approximation Error in Actor-Critic Methods](https://arxiv.org/abs/1802.09477)
* Some hyper-parameters are from [DeepMind Control Suite](https://arxiv.org/abs/1801.00690), [OpenAI Baselines](https://github.com/openai/baselines) and [Ilya Kostrikov](https://github.com/ikostrikov/pytorch-a2c-ppo-acktr)
# Code of My Papers
> They are located in other branches of this repo and seem to be good examples for using this codebase.
* [Global Optimality and Finite Sample Analysis of Softmax Off-Policy Actor Critic under State Distribution Mismatch](https://arxiv.org/abs/2111.02997) [[Off-PAC-KL](https://github.com/ShangtongZhang/DeepRL/tree/Off-PAC-KL)]
* [Truncated Emphatic Temporal Difference Methods for Prediction and Control](https://arxiv.org/abs/2108.05338) [[TruncatedETD](https://github.com/ShangtongZhang/DeepRL/tree/TruncatedETD)]
* [A Deeper Look at Discounting Mismatch in Actor-Critic Algorithms](https://arxiv.org/abs/2010.01069) [[Discounting](https://github.com/ShangtongZhang/DeepRL/tree/discounting)]
* [Breaking the Deadly Triad with a Target Network](https://arxiv.org/abs/2101.08862) [[TargetNetwork](https://github.com/ShangtongZhang/DeepRL/tree/TargetNetwork)]
* [Average-Reward Off-Policy Policy Evaluation with Function Approximation](https://arxiv.org/abs/2101.02808) [[DifferentialGQ](https://github.com/ShangtongZhang/DeepRL/tree/DifferentialGQ)]
* [Mean-Variance Policy Iteration for Risk-Averse Reinforcement Learning](https://arxiv.org/abs/2004.10888) [[MVPI](https://github.com/ShangtongZhang/DeepRL/tree/MVPI)]
* [Learning Retrospective Knowledge with Reverse Reinforcement Learning](https://arxiv.org/abs/2007.06703) [[ReverseRL](https://github.com/ShangtongZhang/DeepRL/tree/ReverseRL)]
* [Provably Convergent Two-Timescale Off-Policy Actor-Critic with Function Approximation](https://arxiv.org/abs/1911.04384) [[COF-PAC](https://github.com/ShangtongZhang/DeepRL/tree/COF-PAC), [TD3-random](https://github.com/ShangtongZhang/DeepRL/tree/TD3-random)]
* [GradientDICE: Rethinking Generalized Offline Estimation of Stationary Values](https://arxiv.org/abs/2001.11113) [[GradientDICE](https://github.com/ShangtongZhang/DeepRL/tree/GradientDICE)]
* [Deep Residual Reinforcement Learning](https://arxiv.org/abs/1905.01072) [[Bi-Res-DDPG](https://github.com/ShangtongZhang/DeepRL/tree/Bi-Res-DDPG)]
* [Generalized Off-Policy Actor-Critic](https://arxiv.org/abs/1903.11329) [[Geoff-PAC](https://github.com/ShangtongZhang/DeepRL/tree/Geoff-PAC), [TD3-random](https://github.com/ShangtongZhang/DeepRL/tree/TD3-random)]
* [DAC: The Double Actor-Critic Architecture for Learning Options](https://arxiv.org/abs/1904.12691) [[DAC](https://github.com/ShangtongZhang/DeepRL/tree/DAC)]
* [QUOTA: The Quantile Option Architecture for Reinforcement Learning](https://arxiv.org/abs/1811.02073) [[QUOTA-discrete](https://github.com/ShangtongZhang/DeepRL/tree/QUOTA-discrete), [QUOTA-continuous](https://github.com/ShangtongZhang/DeepRL/tree/QUOTA-continuous)]
* [ACE: An Actor Ensemble Algorithm for Continuous Control with Tree Search](https://arxiv.org/abs/1811.02696) [[ACE](https://github.com/ShangtongZhang/DeepRL/tree/ACE)]