Student Network
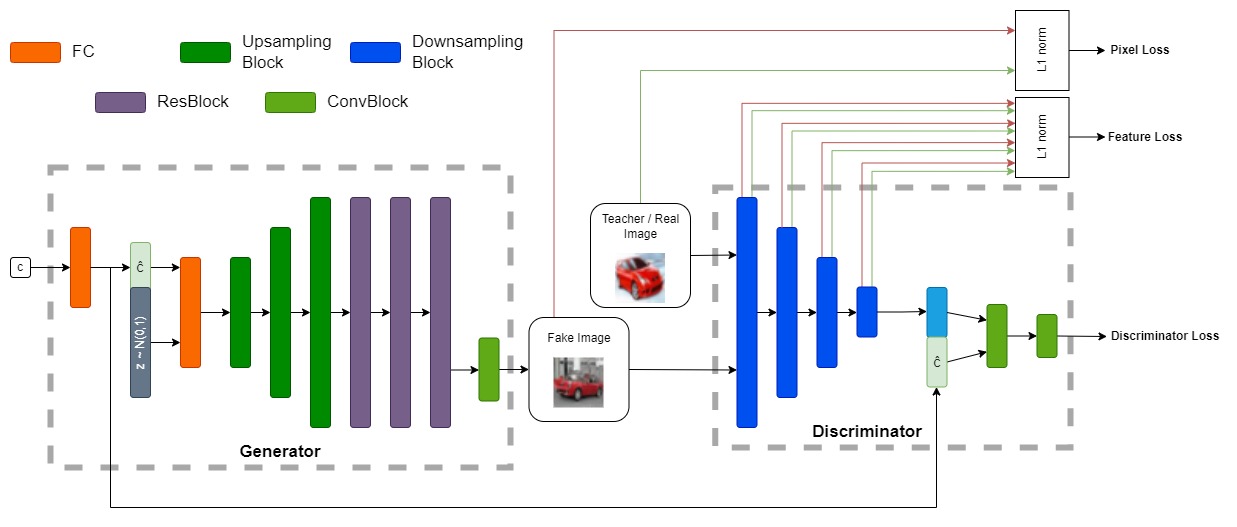
Overview of DiStyleGAN's architecture
Initially, the class condition (one-hot encoding) is projected to 128 dimensions, using a Fully Connected layer. Subsequently, the condition embedding, along with a random noise vector of 512 dimensions are concatenated and passed through another Fully Connected layer, which is followed by 3 consecutive Upsampling blocks. Each upsampling block consists of an upsample layer (scale_factor=2, mode='nearest'), a 3x3 convolution with padding, a Batch Normalization layer, and a Gated Linear Unit (GLU). Next, there are 3 residual blocks [1] and a final convolution, which produces the fake image.
DiStyleGAN's discriminator consists of 4 consecutive Downsampling blocks (4x4 strided-convolution, Spectral Normalization, and a LeakyReLU), with each of them reducing the spatial size of the input image by a factor of 2. Subsequently, the logit is concatenated with the class condition embedding and passed through two convolutions to produce the class-conditional discriminator loss.
The initial four downsampling blocks of the Discriminator are the ones producing the feature maps used in the objective function for the Feature Loss.
References
[1] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.