Implementation of the Transformer model in the paper:
Ashish Vaswani, et al. "Attention is all you need." NIPS 2017.
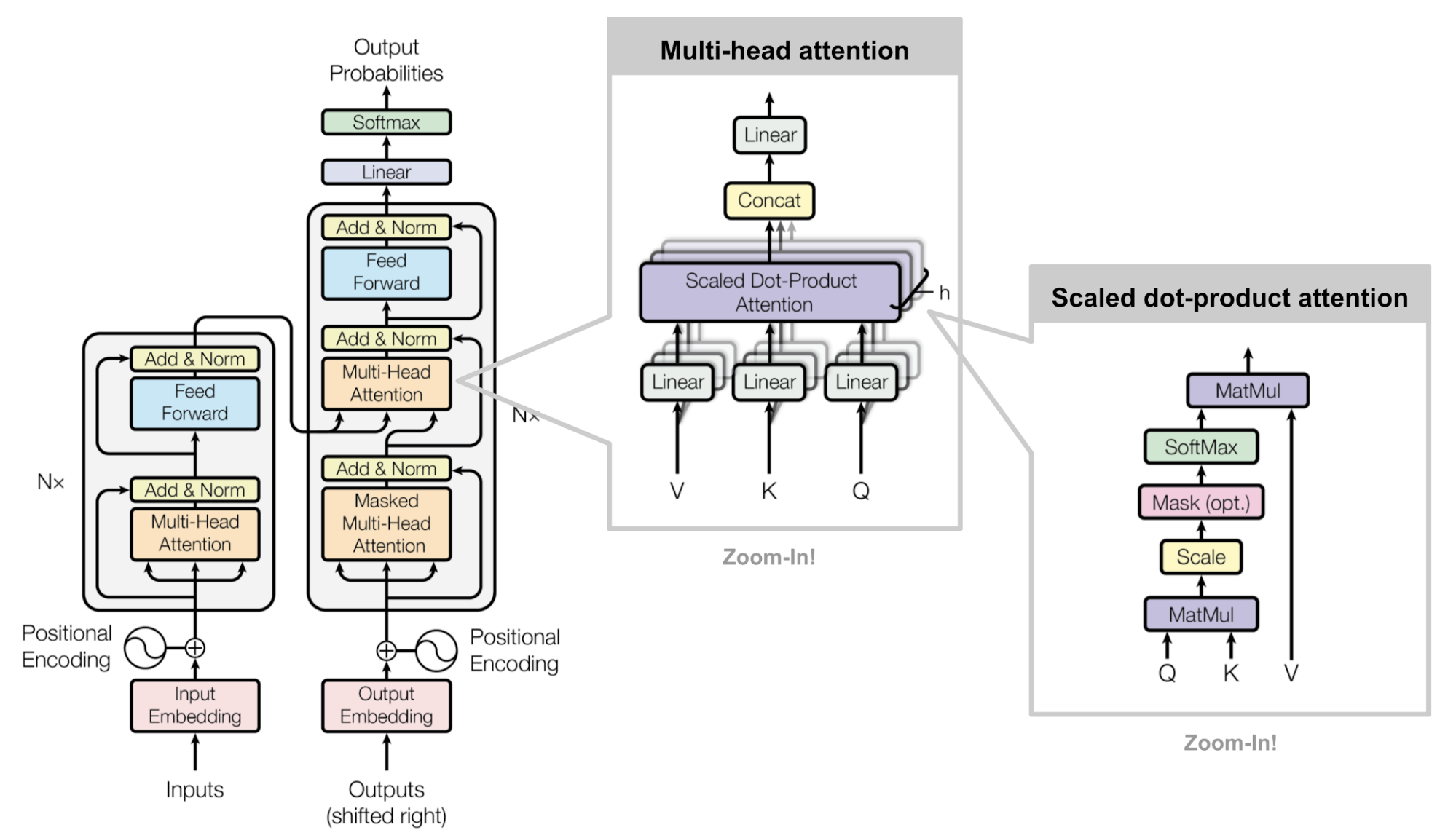
Check my blog post on attention and transformer:
Implementations that helped me:
- https://github.com/Kyubyong/transformer/
- https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py
- http://nlp.seas.harvard.edu/2018/04/01/attention.html
$ git clone https://github.com/lilianweng/transformer-tensorflow.git
$ cd transformer-tensorflow
$ pip install -r requirements.txt# Check the help message:
$ python train.py --help
Usage: train.py [OPTIONS]
Options:
--seq-len INTEGER Input sequence length. [default: 20]
--d-model INTEGER d_model [default: 512]
--d-ff INTEGER d_ff [default: 2048]
--n-head INTEGER n_head [default: 8]
--batch-size INTEGER Batch size [default: 128]
--max-steps INTEGER Max train steps. [default: 300000]
--dataset [iwslt15|wmt14|wmt15]
Which translation dataset to use. [default:
iwslt15]
--help Show this message and exit.
# Train a model on dataset WMT14:
$ python train.py --dataset wmt14Let's say, the model is saved in folder transformer-wmt14-seq20-d512-head8-1541573730 in checkpoints folder.
$ python eval.py transformer-wmt14-seq20-d512-head8-1541573730With the default config, this implementation gets BLEU ~ 20 on wmt14 test set.
[WIP] A couple of tricking points in the implementation.
- How to construct the mask correctly?
- How to correctly shift decoder input (as training input) and decoder target (as ground truth in the loss function)?
- How to make the prediction in an autoregressive way?
- Keeping the embedding of
<pad>as a constant zero vector is sorta important.