antlr repl simple
antlr 资源参考:
- antlr 官方主页: http://www.antlr.org/
- eclipse 插件: https://github.com/jknack/antlr4ide
- maven 依赖:
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4</artifactId>
<version>4.2</version>
</dependency>- 源码仓库: https://github.com/antlr/antlr4
- 语法文件收集仓库: https://github.com/antlr/grammars-v4
- 语法文件生成解析器工具类:
org.antlr.v4.Tool - 运行解析器测试类:
org.antlr.v4.runtime.misc.TestRig - 本教程源码: https://github.com/hanyong/lisping/tree/master/antlr-repl-simple
我现在使用的是最新 4.2 版本, http://search.maven.org/ 上发现还有个对应的 maven 插件 "antlr4-maven-plugin". 奇怪的是 antlr4 maven 插件官方和 google 都没找到相关文档 (只好拉源码自己 mvn site 生成文档?), 官方主推的 ANTLRWorks 好像是个 netbeans 插件, 汗... 对我来说使用 eclipse 插件就足够, 暂时不管别的.
antlr 的使用方式很简单, 写一个语法定义文件 "Somelang.g4",
然后调用 org.antlr.v4.Tool
就可根据语法定义文件生成一个词法分析器和一个语法解析器.
或者直接调用 eclipse 插件.
选中语法定义文件, 直接点运行按钮即可生成分析器.
默认每次修改保存文件时都会自动重新生存,
默认生成目录为 "./target/generated-sources/antlr4".
我根据习惯修改了下插件配置, 禁用自动生成,
生成目录修改为 "src/main/java",
取消勾选 "Mark generated files as derived" 选项.
后来发现 antlr eclipse 插件有点问题,
- 生成目录总是被设置为 "Derived" (bug?), 生成目录是手动管理的正规目录时有问题,
- git 仓库下总是自动产生一个 ".gitignore" 文件,
非常烦人. 较好的办法还是设置一个不手动管理的目录, 如 "src/generated/java", 再用 "build-helper-maven-plugin" 插件及配套 eclipse 插件 (可在 m2e-extras 找到) 将自动生成目录添加到项目 source.
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<version>1.8</version>
<executions>
<execution>
<id>add-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>src/generated/java</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>编译原理上有两个概念, "词法分析" 和 "语法解析", 词法分析检查单词拼写, 产生一个个单词, 即 token. 语法解析则检查单词和标点符号 (也是 token) 组成句子的语法是否正确, 句子的含义是什么. 如果语法正确, antlr 还可以自动生成语法树.
antlr 同时支持词法分析和语法解析. 显然, 词法分析的输出作为语法解析的输入, 你也可以让 antlr 只做其中一样, 自己实现另外一样. 当然最好两件事都让 antlr 来做, 因为 antlr 两件事都做的很棒!
我们定义一个前缀表达式加法语言, 相当于一个精简版的 clojure 表达式. 合法语法示例 "test.clj" 如下:
(+
(+ 1 1)
(+ 5 5)
)姑且把它叫做 plus 语言, 然后为它实现一个解释器.
上述表达式应该得到计算结果 (1 + 1) + (5 + 5) = 12.
antlr 的使用方式很简单, 首先写一个语法定义文件 "Plus.g4".
然后调用 org.antlr.v4.Tool, 或 eclipse 插件,
根据语法定义文件生成一个词法分析器和一个语法解析器.
plus 简单语法定义如下:
grammar Plus;
expr: INT
| list
;
list: '(' '+' expr expr ')'
;
INT: [0-9]
;第一行 grammar Plus; 说明语法名称,
与 java 类似, 语法名必须与文件名同名.
这个名字将作为自动生成的 java 类名的前缀, 所以使用大写字母开头.
antlr 约定词法规则名字以大写字母开头, 如 INT,
语法规则名字以小写字母开头, 如 expr, list.
两者定义都以分号 ";" 结束.
antlr 说它的语法是基于 C 的, 易于学习,
感觉也有很多像正则表达式的地方.
两者的书写语法稍有不同.
词法规则貌似简单的字符串匹配.
语法规则中字面量放在单引号内,
可以直接通过名字引用其他词法和语法规则.
list 语句由 5 个 token 组成,
每个字面量 (标点符号) 也是一个 token,
词法分析器包含了 4 种 token.
所以在 antlr 中实际上是词法和语法混在一起,
更加方便描述和使用.
不知道语法文件怎么写? grammars-v4 收集了许多流行语言的语法写法示例, 你可以直接参考或者照抄.
使用 org.antlr.v4.runtime.misc.TestRig 可以直接运行生成的分析器.
antlr eclipse 插件没有直接支持这个,
不过使用 "Java Application" 运行配置也可以很方便的运行类.
新建运行配置 "grun-plus", 设置参数为 "plus.g4.Plus expr",
第一个参数是语法名,即分析器类名前缀, 所以加了 plus.g4. 包名,
第二个参数是要解析的语法规则名.
从使用帮助上看到, 如果是纯词法规则, 第二个参数可以用 "tokens".
还可以跟一个文件名参数, 表示从文件读入输入, 否则从标准输入读入.
运行 "grun-plus", 输入 (+ 1 2), 可看到如下输出报错:
(+ 1 2)
line 1:2 token recognition error at: ' '
line 1:4 token recognition error at: ' '
line 1:7 token recognition error at: '\n'词法分析器尝试将所有输入都解析为 token,
所有输入字符都要有合法的词法分析规则.
可以照抄一段示例语法 WS: [ \t\r\n]+ -> skip ; 忽略空白字符.
修正后的语法定义如下:
grammar Plus;
expr: INT
| list
;
list: '(' '+' expr expr ')'
;
INT: [0-9]
;
WS: [ \t\r\n]+ -> skip
;再次运行 "grun-plus", 输入 (+ 1 2), 没有任何输出,
说明输入是合法的, antlr 已经识别出输入语法, 然后什么也没做...
修改 "grun-plus" 参数为 "plus.g4.Plus expr -tree src/test.clj", 即增加 "-tree src/test.clj" 参数, 让解析器以 test.clj 作为输入, 并打印出解析后的语法树. 输出结果为:
(expr (list ( + (expr (list ( + (expr 1) (expr 1) ))) (expr (list ( + (expr 5) (expr 5) ))) )))因为 clojure 语法输入本来就是语法树, 这没什么稀奇的, 对其他语言可是大功一件. 还可以使用 "-gui" 参数以图形化方式展示解析后的语法树. 修改 "grun-plus" 参数为 "plus.g4.Plus expr -gui src/test.clj", 再次运行, 可看到如下结果, 这下觉得牛逼了吧.
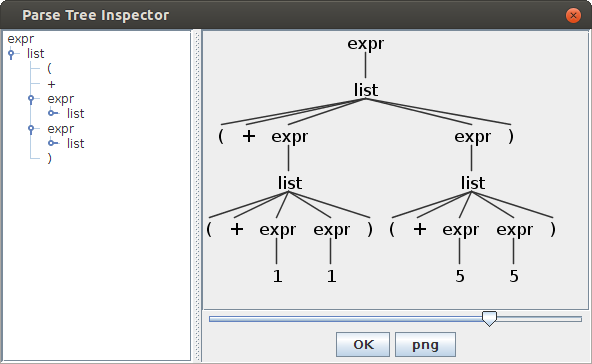
查看产生的解析器 PlusParser 源码,
每条语法规则对应一个同名的解析对应语法的函数.
编程方式使用解析器代码示例 "Plus.java" 如下:
package plus;
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CommonTokenStream;
import plus.g4.PlusLexer;
import plus.g4.PlusParser;
public class Plus {
public static void main(String[] args) throws Exception {
PlusLexer lexer = new PlusLexer(new ANTLRInputStream(System.in));
PlusParser parser = new PlusParser(new CommonTokenStream(lexer));
parser.expr();
}
}运行程序, 将在标准输入接受输入, 如果有语法错误将会提示, 否则跟之前的情形一样, 什么也不做...
antlr 实现了语法解析, 得到一条条语句, 但 antlr 只能帮你到这里了, 每条语句是什么意思, 要执行什么动作, 就要由我们来定义了. antlr 提供两种方式将语句映射到行为上, 类似解析 XML 时的 SAX 方式和 DOM 方式, antlr 支持 Actions 和 抽象语法树 ast 两种方式. 对解释器而言, 我们当然希望边输入边执行, 当然第一种方式更适合.
antlr 对 actions 的支持简单而直接, 直接在语法定义文件中插入 java 代码. 在定义语句的地方, 直接用 java 写出该语句要执行什么操作, 即定义语义. 文档参考: https://theantlrguy.atlassian.net/wiki/display/ANTLR4/Actions+and+Attributes
如可以直接在 list 语句下定义该语句要执行的操作:
list: '(' '+' expr expr ')'
{
System.out.println("find list");
}
;expr 是 INT 语句或 list 语句:
expr: INT
| list
;每条语句下可分别写出该语句要执行的操作:
expr: INT
{
System.out.println("find expr int");
}
| list
{
System.out.println("find expr list");
}
;编写 Actions 时, 还可以直接根据 token 名字访问 token 对象. 语句不能直接通过名字访问, 必须定义别名. 并且只能访问语句的属性, 不能访问语句对象本身. token 也可以定义别名访问, 同一语句中重复出现的 token 可以用不同的别名区分. "Plus.g4" 添加简单行为定义后代码如下:
grammar Plus;
expr: INT
{
System.out.println("found expr int: " + $INT.text);
}
| x = list
{
System.out.println("found expr list: " + $x.text);
}
;
list: '(' '+' a = expr b = expr ')'
{
System.out.printf("found list: %s + %s\n", $a.text, $b.text);
}
;
INT: [0-9]
;
WS: [ \t\r\n]+ -> skip
;重新生成解析器后再运行 Plus 解释器, 输入 (+ 1 2), 可看到如下输出:
(+ 1 2)
found expr int: 1
found expr int: 2
found list: 1 + 2
found expr list: (+12)就像不推荐直接在 JSP 页面中写 java 代码一样, 直接在语法文件中写 java 代码也不是一个好办法. 模仿 MVC 的思路, 可以考虑在独立的 java 文件中完成解释器的主要工作, 提供简单接口在语法文件中调用.
如上定义的加法器, 可以通过一个简单的堆栈机 "PlusVm" 实现,
提供 read, plus 两条指令.
package plus;
import java.util.ArrayDeque;
public class PlusVm {
private ArrayDeque<Integer> stack = new ArrayDeque<>();
public void read(String s) {
int n = Integer.parseInt(s);
stack.addLast(n);
System.out.println("read int: " + n);
}
public void plus() {
int b = stack.removeLast();
int a = stack.removeLast();
int c = a + b;
stack.addLast(c);
System.out.printf("plus: %d + %d = %d\n", a, b, c);
}
}语法文件通过 @header action 添加 import 语句,
通过 @members action 为 parser 添加 vm 成员,
然后在语法 action 中添加对 vm 的简单调用即可.
grammar Plus;
@parser::header {
import plus.PlusVm;
}
@parser::members {
PlusVm vm = new PlusVm();
}
expr: INT
{
vm.read($INT.text);
}
| x = list
;
list: '(' '+' expr expr ')'
{
vm.plus();
}
;
INT: [0-9]
;
WS: [ \t\r\n]+ -> skip
;重新编译运行, 执行结果如下:
(+ 1 2)
read int: 1
read int: 2
plus: 1 + 2 = 3(+
(+ 1 1)
(+ 5 5)
)
read int: 1
read int: 1
plus: 1 + 1 = 2
read int: 5
read int: 5
plus: 5 + 5 = 10
plus: 2 + 10 = 12测试结果正确, 至此, 我们实现了 plus 解释器的功能.
测试上述解释器时发现一个问题, 必须要输入结束才能看到结果, 而更友好的方式我们希望边输入边执行, 增量逐步执行和看到结果. 如输入:
(+
(+ 1 1)后就应该看到 1 + 1 = 2 的结果,
整个输入完再看到最后的 2 + 10 = 12.
跟了一下 ANTLRInputStream 的代码,
原来 ANTLRInputStream 一开始就尝试先读完整个输入流,
才开始进行解析.
这在编译时可以充分缓存文本, 提升性能.
看了一下 CharStream 的实现类还有一个 UnbufferedCharStream,
希望解释执行的场合应该使用这个类,
将 ANTLRInputStream 换成 UnbufferedCharStream.
同时将 CommonTokenStream 也换成 UnbufferedTokenStream<Token>.
重新运行程序, 出现如下异常:
Exception in thread "main" java.lang.UnsupportedOperationException: Unbuffered stream cannot know its size
at org.antlr.v4.runtime.UnbufferedCharStream.size(UnbufferedCharStream.java:295)
at org.antlr.v4.runtime.CommonToken.getText(CommonToken.java:189)
at plus.g4.PlusParser.expr(PlusParser.java:82)这个异常是在解释器解析 INT token 时,
调用 token 的 getText() 方法时产生的.
跟踪到 CommonToken.getText 的代码如下:
@Override
public String getText() {
if ( text!=null ) {
return text;
}
CharStream input = getInputStream();
if ( input==null ) return null;
int n = input.size();
if ( start<n && stop<n) {
return input.getText(Interval.of(start,stop));
}
else {
return "<EOF>";
}
}token 的 text 字段为空, getText() 方法会尝试从输入流中去取 text. 这时会调用 input.size() 方法, 而非缓冲流不支持这个方法, 因为非缓冲流尚未输入完成, 长度为知.
这里我有两个疑问:
- 既然 token 已经解析出来, 当前流的位置应该已经包含 token 文本,
为什么还要检查
(start<n && stop<n)? 从代码猜测好像是有些特殊 token 在源码之外, 这时 text 返回"<EOF>". - token 已经解析出来了, 为什么没有设置 text 字段 ? 难道在读取完 token 的文本前就能构造出 token (结果不是这样) ?
在 CommonToken 的所有构造函数上打断点,
看看 token 是如何识别和构造出来的.
跟踪到 CommonTokenFactory 的代码,
创建 token 后要根据 copyText 设置决定是否立即为 token 设置 text.
@Override
public CommonToken create(Pair<TokenSource, CharStream> source, int type, String text,
int channel, int start, int stop,
int line, int charPositionInLine)
{
CommonToken t = new CommonToken(source, type, channel, start, stop);
t.setLine(line);
t.setCharPositionInLine(charPositionInLine);
if ( text!=null ) {
t.setText(text);
}
else if ( copyText && source.b != null ) {
t.setText(source.b.getText(Interval.of(start,stop)));
}
return t;
}而默认的 CommonTokenFactory.DEFAULT 出于性能考虑默认设置了 copyText 为 false.
但用户可以手动创建工厂设置 copyText 为 true.
/**
* ... ...
* <p>
* The default value is {@code false} to avoid the performance and memory
* overhead of copying text for every token unless explicitly requested.</p>
*/
protected final boolean copyText;
/**
* ... ...
* When {@code copyText} is {@code false}, the {@link #DEFAULT} instance
* should be used instead of constructing a new instance.</p>
*
* @param copyText The value for {@link #copyText}.
*/
public CommonTokenFactory(boolean copyText) { this.copyText = copyText; }一些 token 在识别出其抽象意义后, 确实没必要保留原始文本, 如 "(", ")" 和 "if", "while" 等控制结构. antlr 的做法是明确需要原始文本时, 再回原始输入流去找. 但我们的解释器不符合这类场景:
- LISP 语法很紧凑, 其实很多 token 文本都是有意义的, 值得保留.
- 边输入边执行时效率要求不高. 输入没有完全缓存, 不能回原始文本去找.
一开始的想法是看 antlr 能不能针对特定 token 保留 text,
从代码上看没有这样的机制, 完全由一个 copyText 决定,
即使有这样的机制也太复杂.
既然 CommonTokenFactory 支持用户创建工厂,
看了下 Lexer 类也有个公共的 setTokenFactory 方法,
先试试看手动创建替换默认工厂.
修改后的代码如下:
package plus;
import org.antlr.v4.runtime.CommonTokenFactory;
import org.antlr.v4.runtime.Token;
import org.antlr.v4.runtime.UnbufferedCharStream;
import org.antlr.v4.runtime.UnbufferedTokenStream;
import plus.g4.PlusLexer;
import plus.g4.PlusParser;
public class Plus {
public static void main(String[] args) throws Exception {
PlusLexer lexer = new PlusLexer(new UnbufferedCharStream(System.in));
CommonTokenFactory tokenFactory = new CommonTokenFactory(true);
lexer.setTokenFactory(tokenFactory);
PlusParser parser = new PlusParser(new UnbufferedTokenStream<Token>(lexer));
parser.expr();
}
}运行结果如下:
(+
(+ 1 2)
read int: 1
read int: 2
(+ 5 5)
plus: 1 + 2 = 3
read int: 5
read int: 5
)
plus: 5 + 5 = 10
plus: 3 + 10 = 13结果还是有问题, (+ 1 2) 输入后没有被立即执行.
多次测试后发现解释器总是会慢一拍,
下一个 token 输入后, 上一条语句才被执行.
调试了一下代码, 解析器会在语法 match 后再调用 action, 代码片段 (语法文件自动生成的代码) 如下:
case INT:
enterOuterAlt(_localctx, 1);
{
setState(4); ((ExprContext)_localctx).INT = match(INT);
vm.read((((ExprContext)_localctx).INT!=null?((ExprContext)_localctx).INT.getText():null));
}解析器 org.antlr.v4.runtime.Parser 的 match 方法检查类型正确后会调用 consume() 方法,
代码片段如下:
@NotNull
public Token match(int ttype) throws RecognitionException {
Token t = getCurrentToken();
if ( t.getType()==ttype ) {
_errHandler.reportMatch(this);
consume();
}
else {
... ... error handing
}
return t;
}解析器的 consume() 方法调用到 token stream 的 consume() 方法,
UnbufferedTokenStream.consume() 调用了 sync(1),
尝试读入下一个 token (预读?).
public void consume() {
... ...
sync(1);
}结果要下一个 token 读入后, 当前语句才会被执行.
我们希望输入一行命令, 即回车后,
已输入的命令就应该立即被执行.
立即想到, 可以将当前被忽略的回车作为一个额外的 token 输入.
但回车 token 破坏了现有的语法结构,
除非在现在语法的任意 token 间都添加任意的回车 token,
这显然不合理.
能不能让 token stream 将 token 传递给解析器时,
过滤掉回车 token, 从而不影响语法解析.
尝试看一下从 token stream 取 token 的方法,
有 get, LT 两个方法, 修改似乎比较麻烦.
另一种思路是尝试修改 token stream 的 consume() 方法去掉 sync(1) 操作,
token stream 可以在明确被请求 token 时再执行 sync 操作,
但看 antlr 代码也不好直接修改, 再考虑其他方案.
跟了一下 sync 的代码, 直接调了 fill() 方法.
protected void sync(int want) {
int need = (p+want-1) - n + 1; // how many more elements we need?
if ( need > 0 ) {
fill(need);
}
}fill() 方法如下:
protected int fill(int n) {
for (int i=0; i<n; i++) {
if (this.n > 0 && tokens[this.n-1].getType() == Token.EOF) {
return i;
}
Token t = tokenSource.nextToken();
add(t);
}
return n;
}本想修改 add() 方法跳过 NewLine token, 但这样破坏了 fill() 的返回值.
语法定义没有 skip EOL, 又在 token stream 中 skip 掉, 是一种 hack 手段, 也破坏了语法定义的通用性, 这个办法也不合理. 最好的办法是让 stream 和分词器合作, EOL 要 skip 掉, 但如果最后一个 token 是 EOL, consume 时就不要 sync 了.
调试读入空白 token 时, 回车也不能结束 token, 一定要输入其他非空白字符. 所以独立 EOL token 还有个好处, 可以用回车来结束任意 token.
综合权衡, 还是尝试修改 stream 在 consume 时去掉 sync.
新建类 InterpreterTokenStream 继承 UnbufferedTokenStream<Token>,
复制 consume 方法, 注释掉 sync 一行.
修改后执行结果如下, 满足了我们期望的效果:
(+
(+ 1 2)
read int: 1
read int: 2
plus: 1 + 2 = 3
(+ 5 5)
read int: 5
read int: 5
plus: 5 + 5 = 10
)
plus: 3 + 10 = 13因为我们没有用 listener 相关的类, antlr Tool 可以设置 "-no-listener" 参数, 不要产生 listener 相关类, 代码更加清爽.
调试代码时发现 token 名字会直接作为自动生成代码中的常量定义, 将语法文件中的字面量都定义一个 token 名字, 可以产生更好读, 更易调试的代码. 添加 token 定义后语法文件修改如下:
grammar Plus;
@parser::header {
import plus.PlusVm;
}
@parser::members {
PlusVm vm = new PlusVm();
}
expr: INT
{
vm.read($INT.text);
}
| x = list
;
list: LIST_BEGIN PLUS expr expr LIST_END
{
vm.plus();
}
;
INT: [0-9] ;
LIST_BEGIN: '(' ;
LIST_END: ')' ;
PLUS: '+' ;
WS: [ \t]+ -> skip ;
EOL: ( '\r' '\n' ? | '\n' ) -> skip ;修改前后自动生成代码对比如下.
常量定义:
public static final int
T__2=1, T__1=2, T__0=3, INT=4, WS=5, EOL=6; public static final int
INT=1, LIST_BEGIN=2, LIST_END=3, PLUS=4, WS=5, EOL=6;语法规则:
enterOuterAlt(_localctx, 1);
{
setState(9); match(3);
setState(10); match(2);
setState(11); expr();
setState(12); expr();
setState(13); match(1);
vm.plus();
} enterOuterAlt(_localctx, 1);
{
setState(9); match(LIST_BEGIN);
setState(10); match(PLUS);
setState(11); expr();
setState(12); expr();
setState(13); match(LIST_END);
vm.plus();
}