UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning
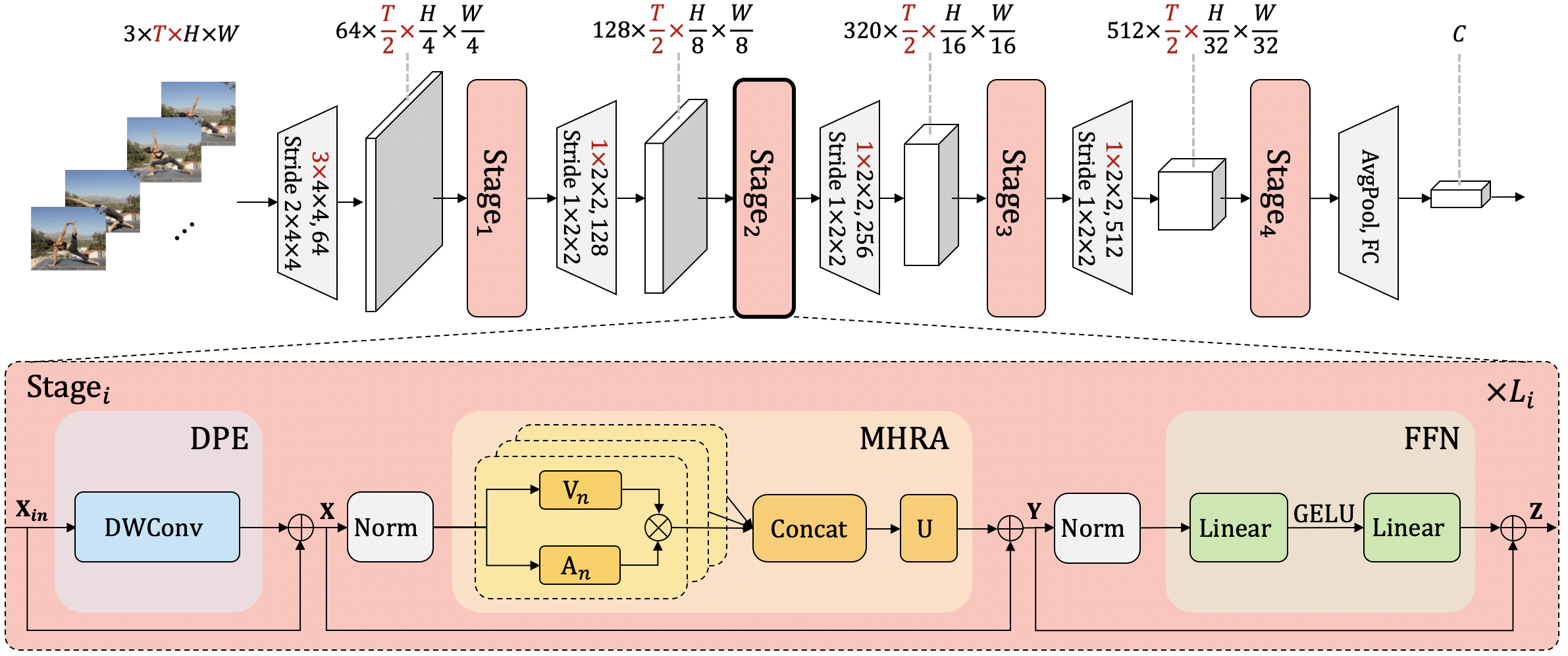
It is a challenging task to learn rich and multi-scale spatiotemporal semantics from high-dimensional videos, due to large local redundancy and complex global dependency between video frames. The recent advances in this research have been mainly driven by 3D convolutional neural networks and vision transformers. Although 3D convolution can efficiently aggregate local context to suppress local redundancy from a small 3D neighborhood, it lacks the capability to capture global dependency because of the limited receptive field. Alternatively, vision transformers can effectively capture long-range dependency by self-attention mechanism, while having the limitation on reducing local redundancy with blind similarity comparison among all the tokens in each layer. Based on these observations, we propose a novel Unified transFormer (UniFormer) which seamlessly integrates merits of 3D convolution and spatiotemporal self-attention in a concise transformer format, and achieves a preferable balance between computation and accuracy. Different from traditional transformers, our relation aggregator can tackle both spatiotemporal redundancy and dependency, by learning local and global token affinity respectively in shallow and deep layers. We conduct extensive experiments on the popular video benchmarks, e.g., Kinetics-400, Kinetics-600, and Something-Something V1&V2. With only ImageNet-1K pretraining, our UniFormer achieves 82.9%/84.8% top-1 accuracy on Kinetics-400/Kinetics-600, while requiring 10x fewer GFLOPs than other state-of-the-art methods. For Something-Something V1 and V2, our UniFormer achieves new state-of-the-art performances of 60.9% and 71.2% top-1 accuracy respectively.
| frame sampling strategy | resolution | backbone | top1 acc | top5 acc | reference top1 acc | reference top5 acc | mm-Kinetics top1 acc | mm-Kinetics top5 acc | testing protocol | FLOPs | params | config | ckpt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 16x4x1 | short-side 320 | UniFormer-S | 80.9 | 94.6 | 80.8 | 94.7 | 80.9 | 94.6 | 4 clips x 1 crop | 41.8G | 21.4M | config | ckpt |
| 16x4x1 | short-side 320 | UniFormer-B | 82.0 | 95.0 | 82.0 | 95.1 | 82.0 | 95.0 | 4 clips x 1 crop | 96.7G | 49.8M | config | ckpt |
| 32x4x1 | short-side 320 | UniFormer-B | 83.1 | 95.3 | 82.9 | 95.4 | 83.0 | 95.3 | 4 clips x 1 crop | 59G | 49.8M | config | ckpt |
The models are ported from the repo UniFormer and tested on our data. Currently, we only support the testing of UniFormer models, training will be available soon.
- The values in columns named after "reference" are the results of the original repo.
- The values in
top1/5 accis tested on the same data list as the original repo, and the label map is provided by UniFormer. The total videos are available at Kinetics400 (BaiduYun password: g5kp), which consists of 19787 videos. - The values in columns named after "mm-Kinetics" are the testing results on the Kinetics dataset held by MMAction2, which is also used by other models in MMAction2. Due to the differences between various versions of Kinetics dataset, there is a little gap between
top1/5 accandmm-Kinetics top1/5 acc. For a fair comparison with other models, we report both results here. Note that we simply report the inference results, since the training set is different between UniFormer and other models, the results are lower than that tested on the author's version. - Since the original models for Kinetics-400/600/700 adopt different label file, we simply map the weight according to the label name. New label map for Kinetics-400/600/700 can be found here.
- Due to some difference between SlowFast and MMAction2, there are some gaps between their performances.
For more details on data preparation, you can refer to preparing_kinetics.
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]Example: test UniFormer-S model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/uniformer/uniformer-small_imagenet1k-pre_16x4x1_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pklFor more details, you can refer to the Test part in the Training and Test Tutorial.
@inproceedings{
li2022uniformer,
title={UniFormer: Unified Transformer for Efficient Spatial-Temporal Representation Learning},
author={Kunchang Li and Yali Wang and Gao Peng and Guanglu Song and Yu Liu and Hongsheng Li and Yu Qiao},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=nBU_u6DLvoK}
}