Many recent works on 3D object detection have focused on designing neural network architectures that can consume point cloud data. While these approaches demonstrate encouraging performance, they are typically based on a single modality and are unable to leverage information from other modalities, such as a camera. Although a few approaches fuse data from different modalities, these methods either use a complicated pipeline to process the modalities sequentially, or perform late-fusion and are unable to learn interaction between different modalities at early stages. In this work, we present PointFusion and VoxelFusion: two simple yet effective early-fusion approaches to combine the RGB and point cloud modalities, by leveraging the recently introduced VoxelNet architecture. Evaluation on the KITTI dataset demonstrates significant improvements in performance over approaches which only use point cloud data. Furthermore, the proposed method provides results competitive with the state-of-the-art multimodal algorithms, achieving top-2 ranking in five of the six bird's eye view and 3D detection categories on the KITTI benchmark, by using a simple single stage network.
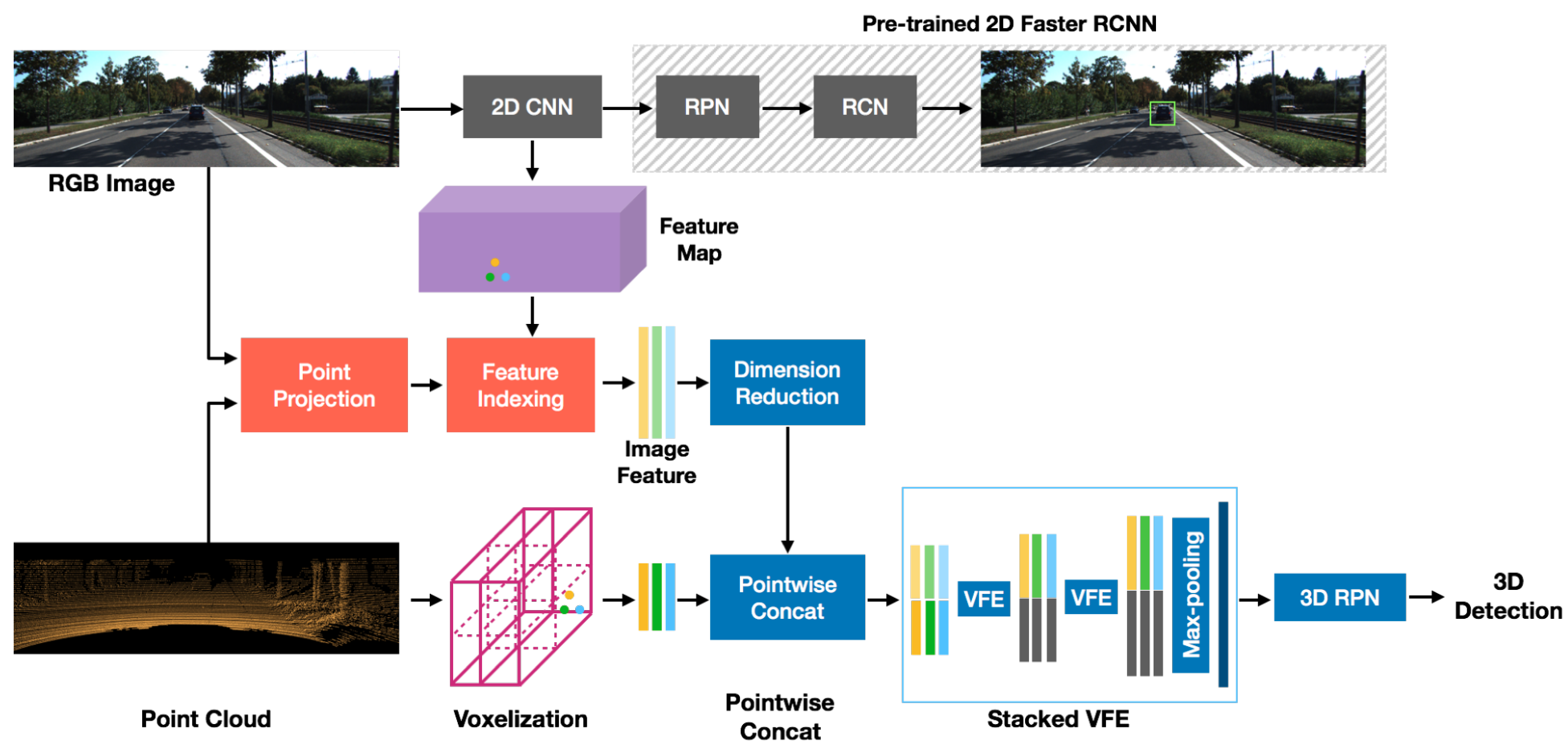
We implement MVX-Net and provide its results and models on KITTI dataset.
| Backbone | Class | Lr schd | Mem (GB) | Inf time (fps) | mAP | Download |
|---|---|---|---|---|---|---|
| SECFPN | 3 Class | cosine 80e | 6.7 | 63.5 | model | log |
@inproceedings{sindagi2019mvx,
title={MVX-Net: Multimodal voxelnet for 3D object detection},
author={Sindagi, Vishwanath A and Zhou, Yin and Tuzel, Oncel},
booktitle={2019 International Conference on Robotics and Automation (ICRA)},
pages={7276--7282},
year={2019},
organization={IEEE}
}