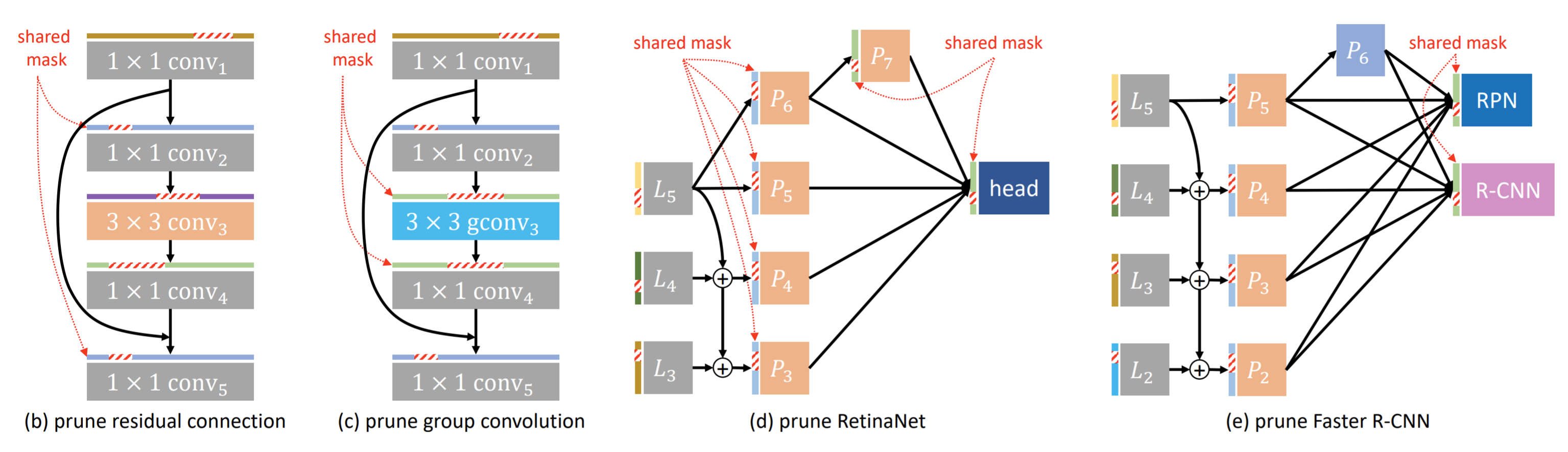
Network compression has been widely studied since it is able to reduce the memory and computation cost during inference. However, previous methods seldom deal with complicated structures like residual connections, group/depthwise convolution and feature pyramid network, where channels of multiple layers are coupled and need to be pruned simultaneously. In this paper, we present a general channel pruning approach that can be applied to various complicated structures. Particularly, we propose a layer grouping algorithm to find coupled channels automatically. Then we derive a unified metric based on Fisher information to evaluate the importance of a single channel and coupled channels. Moreover, we find that inference speedup on GPUs is more correlated with the reduction of memory rather than FLOPs, and thus we employ the memory reduction of each channel to normalize the importance. Our method can be used to prune any structures including those with coupled channels. We conduct extensive experiments on various backbones, including the classic ResNet and ResNeXt, mobilefriendly MobileNetV2, and the NAS-based RegNet, both on image classification and object detection which is under-explored. Experimental results validate that our method can effectively prune sophisticated networks, boosting inference speed without sacrificing accuracy.
| Model | Top-1 | Gap | Flop(G) | Remain(%) | Parameters(M) | Remain(%) | Config | Download | Onnx_cpu(FPS) |
|---|---|---|---|---|---|---|---|---|---|
| ResNet50 | 76.55 | - | 4.11 | - | 25.6 | - | mmcls | model | 55.360 |
| ResNet50_pruned_act | 75.22 | -1.33 | 2.06 | 50.1% | 16.3 | 63.7% | prune | finetune | pruned | finetuned | log | 80.671 |
| ResNet50_pruned_act + dist kd | 76.50 | -0.05 | 2.06 | 50.1% | 16.3 | 63.7% | prune | finetune | pruned | finetuned | log | 80.671 |
| ResNet50_pruned_flops | 75.61 | -0.94 | 2.06 | 50.1% | 16.3 | 63.7% | prune | finetune | pruned | finetuned | log | 78.674 |
| MobileNetV2 | 71.86 | - | 0.313 | - | 3.51 | - | mmcls | model | 419.673 |
| MobileNetV2_pruned_act | 70.82 | -1.04 | 0.207 | 66.1% | 3.18 | 90.6% | prune | finetune | pruned | finetuned | log | 576.118 |
| MobileNetV2_pruned_flops | 70.87 | -0.99 | 0.207 | 66.1% | 2.82 | 88.7% | prune | finetune | pruned | finetuned | log | 540.105 |
Note
- Because the pruning papers use different pretraining and finetuning settings, It is hard to compare them fairly. As a result, we prefer to apply algorithms on the openmmlab settings.
- This may make the experiment results are different from that in the original papers.
| Model(Detector-Backbone) | AP | Gap | Flop(G) | Remain(%) | Parameters(M) | Remain(%) | Config | Download | Onnx_cpu(FPS) |
|---|---|---|---|---|---|---|---|---|---|
| RetinaNet-R50-FPN | 36.5 | - | 250 | - | 63.8 | - | mmdet | model | 1.095 |
| RetinaNet-R50-FPN_pruned_act | 36.5 | 0.0 | 126 | 50.4% | 34.6 | 54.2% | prune | finetune | pruned | finetuned | log | 1.608 |
| RetinaNet-R50-FPN_pruned_flops | 36.6 | +0.1 | 126 | 50.4% | 34.9 | 54.7% | prune | finetune | pruned | finetuned | log | 1.609 |
| Model | AP | Gap | Flop(G) | Remain(%) | Parameters(M) | Remain(%) | Config | Download | Onnx_cpu(FPS) |
|---|---|---|---|---|---|---|---|---|---|
| rtmpose-s | 0.716 | - | 0.68 | - | 5.47 | - | mmpose | model | 196 |
| rtmpose-s_pruned_act | 0.691 | -0.025 | 0.34 | 50.0% | 3.42 | 62.5% | prune | finetune | pruned | finetuned | log | 268 |
| rtmpose-t | 0.682 | - | 0.35 | - | 3.34 | - | mmpose | model | 279 |
| Model | AP | Gap | Flop(G) | Remain(%) | Parameters(M) | Remain(%) | Config | Download | Onnx_cpu(FPS) |
|---|---|---|---|---|---|---|---|---|---|
| rtmpose-s-aic-coco | 0.722 | - | 0.68 | - | 5.47 | - | mmpose | model | 196 |
| rtmpose-s-aic-coco_pruned_act | 0.694 | -0.028 | 0.35 | 51.5% | 3.43 | 62.7% | prune | finetune | pruned | finetuned | log | 272 |
| rtmpose-t-aic-coco | 0.685 | - | 0.35 | - | 3.34 | - | mmpose | model | 279 |
- All FPS is test on the same machine with 11th Gen Intel(R) Core(TM) i7-11700 @ 2.50GHz.
We have three steps to apply GroupFisher to your model, including Prune, Finetune, Deploy.
Note: please use torch>=1.12, as we need fxtracer to parse the models automatically.
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 PORT=29500 ./tools/dist_train.sh \
{config_folder}/group_fisher_{normalization_type}_prune_{model_name}.py 8 \
--work-dir $WORK_DIRIn the pruning config file. You have to fill some args as below.
"""
_base_ (str): The path to your pretrained model checkpoint.
pretrained_path (str): The path to your pretrained model checkpoint.
interval (int): Interval between pruning two channels. You should ensure you
can reach your target pruning ratio when the training ends.
normalization_type (str): GroupFisher uses two methods to normlized the channel
importance, including ['flops','act']. The former uses flops, while the
latter uses the memory occupation of activation feature maps.
lr_ratio (float): Ratio to decrease lr rate. As pruning progress is unstable,
you need to decrease the original lr rate until the pruning training work
steadly without getting nan.
target_flop_ratio (float): The target flop ratio to prune your model.
input_shape (Tuple): input shape to measure the flops.
"""After the pruning process, you will get a checkpoint of the pruned model named flops_{target_flop_ratio}.pth in your workdir.
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 PORT=29500 ./tools/dist_train.sh \
{config_folder}/group_fisher_{normalization_type}_finetune_{model_name}.py 8 \
--work-dir $WORK_DIRThere are also some args for you to fill in the config file as below.
"""
_base_(str): The path to your pruning config file.
pruned_path (str): The path to the checkpoint of the pruned model.
finetune_lr (float): The lr rate to finetune. Usually, we directly use the lr
rate of the pretrain.
"""After finetuning, except a checkpoint of the best model, there is also a fix_subnet.json, which records the pruned model structure. It will be used when deploying.
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 PORT=29500 ./tools/dist_test.sh \
{config_folder}/group_fisher_{normalization_type}_finetune_{model_name}.py {checkpoint_path} 8First, we assume you are fimilar to mmdeploy. For a pruned model, you only need to use the pruning deploy config to instead the pretrain config to deploy the pruned version of your model.
python {mmdeploy}/tools/deploy.py \
{mmdeploy}/{mmdeploy_config}.py \
{config_folder}/group_fisher_{normalization_type}_deploy_{model_name}.py \
{path_to_finetuned_checkpoint}.pth \
{mmdeploy}/tests/data/tiger.jpegThe deploy config has some args as below:
"""
_base_ (str): The path to your pretrain config file.
fix_subnet (Union[dict,str]): The dict store the pruning structure or the
json file including it.
divisor (int): The divisor the make the channel number divisible.
"""The divisor is important for the actual inference speed, and we suggest you to test it in [1,2,4,8,16,32] to find the fastest divisor.
All the modules of GroupFisher is placesded in mmrazor/implementations/pruning/group_fisher/.
| File | Module | Feature |
|---|---|---|
| algorithm.py | GroupFisherAlgorithm | Dicide when to prune a channel according to the interval and the current iteration. |
| mutator.py | GroupFisherChannelMutator | Select the unit with the channel of the minimal importance and to prune it. |
| unit.py | GroupFisherChannelUnit | Compute fisher info |
| ops.py counters |
GroupFisherConv2d GroupFisherLinear corresbonding counters |
Collect model info to compute fisher info, including activation, grad and tensor shape. |
There are also some modules to support GroupFisher. These modules may be refactored and moved to other folders as common modules for all pruning algorithms.
| File | Module | Feature |
|---|---|---|
| hook.py | PruningStructureHook ResourceInfoHook |
Display pruning Structure iteratively. |
| prune_sub_model.py | GroupFisherSubModel | Convert a pruning algorithm(architecture) to a pruned static model. |
| prune_deploy_sub_model.py | GroupFisherDeploySubModel | Init a pruned static model for mmdeploy. |
@InProceedings{Liu:2021,
TITLE = {Group Fisher Pruning for Practical Network Compression},
AUTHOR = {Liu, Liyang
AND Zhang, Shilong
AND Kuang, Zhanghui
AND Zhou, Aojun
AND Xue, Jing-hao
AND Wang, Xinjiang
AND Chen, Yimin
AND Yang, Wenming
AND Liao, Qingmin
AND Zhang, Wayne},
BOOKTITLE = {Proceedings of the 38th International Conference on Machine Learning},
YEAR = {2021},
SERIES = {Proceedings of Machine Learning Research},
MONTH = {18--24 Jul},
PUBLISHER = {PMLR},
}