diff --git a/readme-sync/v0/senseml-reference/3000 - llm-based-methods/1000 - list.md b/readme-sync/v0/senseml-reference/3000 - llm-based-methods/1000 - list.md
index e547e4d00..a1f9474fa 100644
--- a/readme-sync/v0/senseml-reference/3000 - llm-based-methods/1000 - list.md
+++ b/readme-sync/v0/senseml-reference/3000 - llm-based-methods/1000 - list.md
@@ -50,8 +50,8 @@ Parameters
| singleLLMCompletion | boolean. default: false | If Sensible returns incomplete or duplicate results in a list that's under ~20 pages long, set this parameter to True to troubleshoot.
If true, Sensible concatenates the top-scoring chunks into a single batch to send as context to the LLM, instead of batching calls to the LLM. By avoiding splitting context, you can avoid problems such as the LLM failing to recognize the end of one list and the start of another. See Notes for more information.
- The following limits apply:
- If the extracted list exceeds the output limit for a single API response from an LLM engine (~16k tokens or ~20 pages for all supported LLM engines), Sensible truncates the list.
- Rarely, Sensible fails to truncate a list at ~16k token output and returns an error. This can happen if the source text in the [context](doc:list#notes) has a very small font size. To avoid this type of error, set this parameter to false. | Don't set this parameter to true if you set the LLM Engine parameter to Long. The Single LLM Completion parameter limits output to ~16k tokens, so it'll truncate longer lists. |
| | | ***FIND CONTEXT*** | |
| source_ids | array of field IDs in the current config | If specified, prompts an LLM to extract data from another field's output. For example, if you extract a field `_checking_transactions` and specify it in this parameter, then Sensible searches for the answers to `frequency of deposits` and `frequency of withdrawals` in `_checking_transactions`, rather than searching the whole document to locate the [context](doc:prompt#notes). Note that the `_checking_transactions` field must precede the `transactions_frequencies` field in the fields array in this example.
Use this parameter to:
- reformat or otherwise transform the outputs of other fields.
- narrow down the [context](doc:prompt#notes) for your prompts to a specific part of the document.
- troubleshoot or simplify complex prompts that aren't performing reliably. Break the prompt into several simpler parts, and chain them together using successive Source Ids in the fields array.
For an example, see [Examples](doc:list#example-extract-data-from-other-fields). | If you configure this parameter, then generally don't configure:
- LLM Engine parameter
- Single LLM Completion parameter
- If you configure this parameter, Sensible doesn't allow you to specify the following parameters:
- Multimodal Engine parameter
- Chunk Scoring Text parameter
- Search By Summarization parameter
- Page Hinting parameter
- Chunk Count parameter
- Chunk Size parameter
- Chunk Overlap Percentage parameter
- Page Range parameter |
+| searchBySummarization | boolean. default: false | Set this to true to troubleshoot situations in which Sensible misidentifies the part of the document that contains the answers to your prompts.
This parameter is compatible with documents up to 1,280 pages long.
When true, Sensible uses a [completion-only retrieval-augmented generation (RAG) strategy](https://www.sensible.so/blog/embeddings-vs-completions-only-rag): Sensible prompts an LLM to summarize each page in the document, prompts a second LLM to return the pages most relevant to your prompt based on the summaries, and extracts the answers to your prompts from those pages. | If you set this parameter to true, then Sensible sets the following for chunk-related parameters and ignores any configured values:
- Chunk Size parameter: 1
- Chunk Overlap Percentage parameter: 0
- Chunk Count parameter: 5 |
| | | ***GLOBAL PARAMETERS*** | |
-| searchBySummarization | | For information about this parameter, see [Advanced LLM prompt configuration](doc:prompt#parameters) | |
| contextDescription | | For information about this parameter, see [Advanced LLM prompt configuration](doc:prompt#parameters) | |
| pageHinting | | For information about this parameter, see [Advanced LLM prompt configuration](doc:prompt#parameters) | |
| chunkCount | | For information about this parameter, see [Advanced LLM prompt configuration](doc:prompt#parameters) | |
diff --git a/readme-sync/v0/senseml-reference/3000 - llm-based-methods/1500 - query-group.md b/readme-sync/v0/senseml-reference/3000 - llm-based-methods/1500 - query-group.md
index 1c83dcfb2..0d2ea9f8f 100644
--- a/readme-sync/v0/senseml-reference/3000 - llm-based-methods/1500 - query-group.md
+++ b/readme-sync/v0/senseml-reference/3000 - llm-based-methods/1500 - query-group.md
@@ -66,6 +66,7 @@ Parameters
| | | ***FIND CONTEXT*** | |
| source_ids | array of field IDs in the current config | If specified, prompts an LLM to extract data from another field's output. For example, if you extract a field `_checking_transactions` and specify it in this parameter, then Sensible searches for the answer to `what is the largest transaction?` in `_checking_transactions`, rather than searching the whole document to locate the [context](doc:prompt#notes). Note that the `_checking_transactions` field must precede the `largest_transaction` field in the fields array in this example.
Use this parameter to:
- narrow down the [context](doc:prompt#notes) for your prompts to a specific part of the document.
- reformat or otherwise transform the outputs of other fields. For example, you can use this as an alternative to types such as the [Compose](doc:types#compose) type with prompts such as `if the context includes a date, return it in mm/dd/yyy format`.
- troubleshoot or simplify complex prompts that aren't performing reliably. Break the prompt into several simpler parts, and chain them together using successive Source ID parameters in the fields array.
To extract repeating data, such as a list, specify the Source Ids parameter for the [List](doc:list#parameters) method rather than for the Query Group method.
For an example, see [Examples](doc:query-group#example-transform-fields). | If you configure this parameter, then in the query group:
- Sensible doesn't support confidence signals.
- Sensible doesn't allow you to specify the following parameters:
- Multimodal Engine parameter
- Chunk Scoring Text parameter
- Search By Summarization parameter
- Page Hinting parameter
- Chunk Count parameter
- Chunk Size parameter
- Chunk Overlap Percentage parameter
- Page Range parameter |
| chunkScoringText | string | Use this parameter to narrow down the page location of the answer to your prompt. For details about context and chunks, see the Notes section.
A representative snippet of text from the part of the document where you expect to find the answer to your prompt. For example, if your prompt has multiple candidate answers, and the correct answer is located near unique or distinctive text that's difficult to incorporate into your question, then specify the distinctive text in this parameter.
If specified, Sensible uses this text to score chunks' relevancy. If unspecified, Sensible uses the prompt to score chunks.
Sensible recommends that the snippet is specific to the target chunk, semantically similar to the chunk, and structurally similar to the chunk.
For example, if the chunk contains a street address formatted with newlines, then provide a snippet with an example street address that contains newlines, like `123 Main Street\nLondon, England`. If the chunk contains a street address in a free-text paragraph, then provide an unformatted street address in the snippet. | If you set the Search By Summarization parameter to true, Sensible ignores any configured value for this parameter for the queries in the group. |
+| searchBySummarization | boolean. default: false | Set this to true to troubleshoot situations in which Sensible misidentifies the part of the document that contains the answers to your prompts.
This parameter is compatible with documents up to 1,280 pages long.
When true, Sensible uses a [completion-only retrieval-augmented generation (RAG) strategy](https://www.sensible.so/blog/embeddings-vs-completions-only-rag): Sensible prompts an LLM to summarize each page in the document, prompts a second LLM to return the pages most relevant to your prompt based on the summaries, and extracts the answers to your prompts from those pages. | If you set this parameter to true, then Sensible sets the following for chunk-related parameters and ignores any configured values:
- Chunk Size parameter: 1
- Chunk Overlap Percentage parameter: 0
- Chunk Count parameter: 5
- Chunk Scoring Text parameter
|
| | | ***EXTRACT FROM IMAGES*** | |
| multimodalEngine | object | Configure this parameter to:
- Extract data from images embedded in a document, for example, photos, charts, or illustrations.
- Troubleshoot extracting from complex text layouts, such as overlapping lines, lines between lines, and handwriting. For example, use this as an alternative to the [Signature](doc:signature) method, the [Nearest Checkbox](doc:nearest-checkbox) method, the [OCR engine](doc:ocr-engine), and line [preprocessors](doc:preprocessors).
This parameter sends an image of the document region containing the target data to a multimodal LLM (GPT-4o mini), so that you can ask questions about text and non-text images. This bypasses Sensible's [OCR](doc:ocr) and direct-text extraction processes for the region.
This parameter has the following parameters:
`region`: The document region to send as an image to the multimodal LLM. Configurable with the following options :
- To automatically select the [context](doc:query-group#notes) as the region, specify `"region": "automatic"`. If you configure this option for a non-text image, then help Sensible locate the context by including queries in the group that target text near the image, or by specifying the nearby text in the Chunk Scoring Text parameter.
- To manually specify a region, specify an [anchor](doc:anchor) close to the region you want to capture. Specify the region's dimensions in inches relative to the anchor using the [Region](doc:region) method's parameters, for example:
`"region": { `
`"start": "below",`
`"width": 8,`
`"height": 1.2,`
`"offsetX": -2.5,`
`"offsetY": -0.25`
`}` | |
| | | ***TROUBLESHOOT PROMPT*** | |
diff --git a/readme-sync/v0/senseml-reference/6000 - computed-field-methods/index.md b/readme-sync/v0/senseml-reference/6000 - computed-field-methods/index.md
index 7f2f2290e..df8bbbfd3 100644
--- a/readme-sync/v0/senseml-reference/6000 - computed-field-methods/index.md
+++ b/readme-sync/v0/senseml-reference/6000 - computed-field-methods/index.md
@@ -37,7 +37,7 @@ You can set the output of other fields as the [context](doc:prompt#notes) for ot
- Narrow down the [context](doc:prompt#notes) for your prompts to a specific part of the document.
- Troubleshoot or simplify complex prompts that aren't performing reliably. Break the prompt into several simpler parts, and chain them together using successive Source ID parameters in the fields array.
-To transform extracted document data using LLMs, configure the Source Ids parameter for the [Query Group](doc:query-group) or [List](doc:list#parameters) methods.
+To use other fields as context, configure the Source Ids parameter for the [Query Group](doc:query-group) or [List](doc:list#parameters) methods.
## Custom logic-based computed field methods
diff --git a/readme-sync/v0/senseml-reference/8000 - concepts/0350 - prompt.md b/readme-sync/v0/senseml-reference/8000 - concepts/0350 - prompt.md
index 636eeece7..1d6b6e5dc 100644
--- a/readme-sync/v0/senseml-reference/8000 - concepts/0350 - prompt.md
+++ b/readme-sync/v0/senseml-reference/8000 - concepts/0350 - prompt.md
@@ -53,7 +53,6 @@ For parameters specific to an LLM-based method, see its reference topic, for exa
| chunkOverlapPercentage | `0`, `0.25`, `0.5` defaults:
Query Group: 0.5
List: 0
NLP Table: 0.5 | The extent to which chunks overlap, as a percentage of the chunks' height. For example, `0.5` specifies each chunk overlaps by half its height.
Sensible recommends setting a non-zero overlap to avoid splitting data across chunks. Set overlap to 0 solely if you're confident that your document layout doesn't flow across page boundaries and you're using a one-page chunk size. | If you set the Search By Summarization parameter to true, then Sensible sets this parameter to 0 and ignores any configured value. |
| | | | |
| | | ***FIND CONTEXT*** | |
-| searchBySummarization | boolean. default: false | Set this to true to troubleshoot situations in which Sensible misidentifies the part of the document that contains the answers to your prompts.
This parameter is compatible with documents up to 1,280 pages long.
When true, Sensible uses a [completion-only retrieval-augmented generation (RAG) strategy](https://www.sensible.so/blog/embeddings-vs-completions-only-rag): Sensible prompts an LLM to summarize each page in the document, prompts a second LLM to return the pages most relevant to your prompt based on the summaries, and extracts the answers to your prompts from those pages. | If you set this parameter to true, then Sensible sets the following for chunk-related parameters and ignores any configured values:
- Chunk Size parameter: 1
- Chunk Overlap Percentage parameter: 0
- Chunk Count parameter: 5
- (for the Query Group method) Chunk Scoring Text parameter
|
| pageHinting | boolean. default: true | Includes or or removes page metadata for each chunk from the full prompt Sensible inputs to an LLM.
If set to true, then you can add location information to a prompt to narrow down the context's location. For example:
**Location relative to page number and position on page**
- "address in the top left of the first page of the document"
- "What is the medical paid value on the last claim of the second page?"
**Location relative to content in document**
- "total amount in the expense table"
- "phone number after section 2"
Set this to false if page numbers don't add useful information. For example, if your PDF converter automatically applied page numbers to scanned ID cards, set this parameter to false to ignore the page numbers, since their relationship to the cards' text is arbitrary.
| |
| pageRange | object | Configures the possible page range for finding the context in the document.
If specified, Sensible creates chunks in the page range and ignores other pages. For example, use this parameter to improve performance, or to avoid extracting unwanted data if your prompt has multiple candidate answers.
Contains the following parameters:
`startPage`: Zero-based index of the page at which Sensible starts creating chunks (inclusive).
`endPage`: Zero-based index of the page at which Sensible stops creating chunks (exclusive). | Sensible ignores this parameter when searching for a field's [anchor](doc:anchor). If you want to exclude the field's anchor using a page range, use the [Page Range](doc:page-range) preprocessor instead. |
| | | | |
diff --git a/readme-sync/v0/senseml-reference/8000 - concepts/draft-llms.md b/readme-sync/v0/senseml-reference/8000 - concepts/draft-llms.md
index 6eee7e24c..8176feed2 100644
--- a/readme-sync/v0/senseml-reference/8000 - concepts/draft-llms.md
+++ b/readme-sync/v0/senseml-reference/8000 - concepts/draft-llms.md
@@ -20,13 +20,13 @@ TO DOs: -- search by summarization is NOT global; NLP table don't support it.
+The following is an overview of how Sensible's LLM-based methods work. Use this overview to understand your configuration and troubleshooting options.
+### Overview
-### prompt overview
+Sensible supports LLM-based data extraction methods from documents. For example, for an insurance declaration document, you can submit the prompt `when does the insurance coverage start?`, and the LLM returns `08-14-24`.
-The following is an overview of how Sensible's LLM-based methods work, to help you undersatnd your configuration options.
-
-The most important constraint is that Sensible can't provide the text of a whole document to an LLM, unless the document is quite short. To meet the LLM's input token limit, Sensible must instead provide the LLM with a relevant extract from the document, or *context*. For example, for an insurance declaration document, the prompt might be `when does the coverage start?` and the (abbreviated) context might be something like:
+LLMs' input token limits are important constraints in this scenario. Because of these limits, Sensible must generally submit an excerpt of the document rather than the whole document to the LLM. This relevant excerpt is called *context*. For example, for the prompt `when does the insurance coverage start?`, the abbreviated context can be something like:
````txt
Tel: 1-800-851-2000 Declarations Page
@@ -34,22 +34,38 @@ This is a description of you coverage
Please retain for your coverage.
Policy Number: 555-555-55-55
Coverage Period:
-08-14-20 through 02-14-21
+08-14-24 through 02-14-25
+[etc]
````
Note that context doesn't have to be limited to contiguous pages in the document; it can consist of extracts scattered across the document.
-Most LLM-prompt troubleshooting has to do with context: locating it, making sure it's complete.
+### Example: Full prompt with context
+
+See the following image for an example of a *full prompt* that Sensible inputs to an LLM for the [Query Group](doc:query-group) method using the default embeddings scoring approach (TODO link to that section). When you write a prompt using an LLM-based method, Sensible creates a full prompt using the following:
-You can use a variety of configuration methods to locate the relevant and complete context in the document. Let's go through them from least to most configurable:
+- A prompt introduction
+- "context", made up of chunks excerpted from the document and of page metadata.
+- concatenated descriptive prompts you configure in an LLM-based method, such as in the [List](doc:list) or [Query Group](doc:query-group) methods.
+
+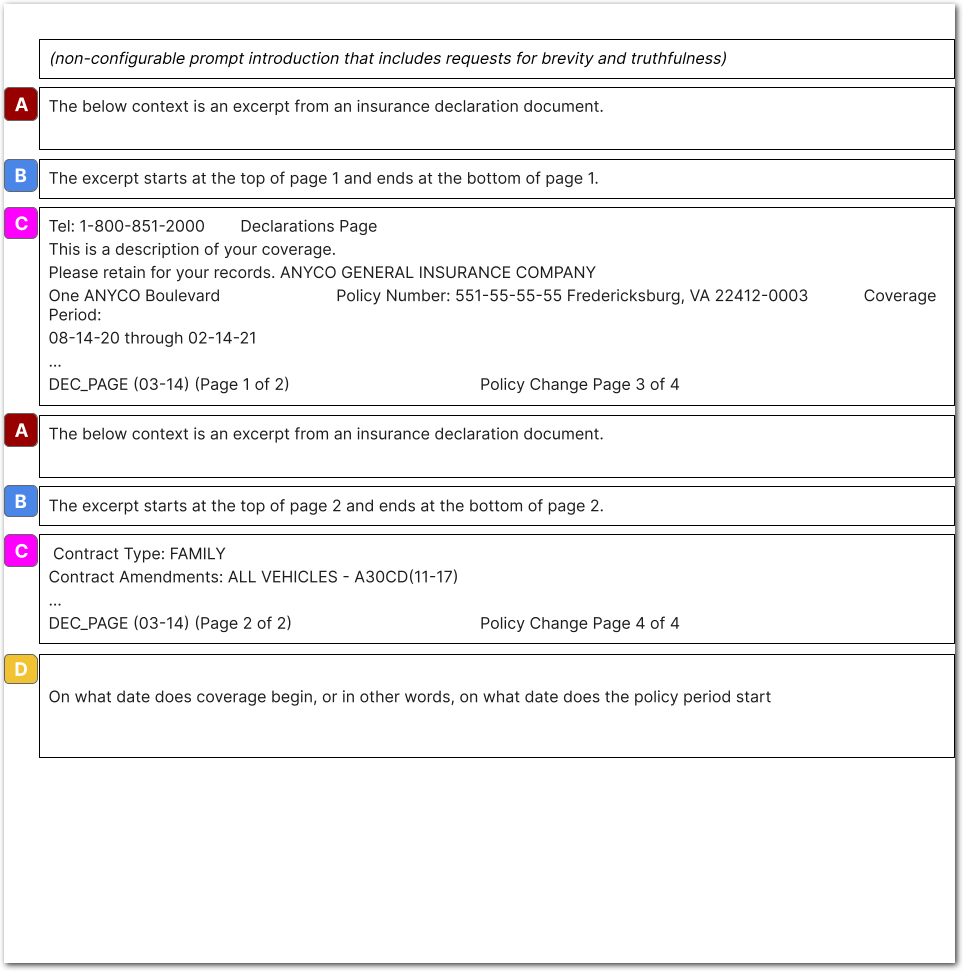
+| key | description |
+| ---- | ------------------------------------------------------------ |
+| A | Context description: an overall description of the chunks.
Note that the preceding image shows an example of a user-configured context description overriding the default. |
+| B | Page metadata for chunks. |
+| C | Chunks excerpted from document, concatenated into "context" |
+| D | Concatenation of all the descriptive prompts you configured in the method. For example, concatenation of all the column descriptions and the overall table description for the [NLP Table](doc:nlp-table) method. |
+Sensible provides configuration options for ensuring correct and complete contexts. For more information, see the following section.
// TODO: add a mermaid chart here??? https://docs.readme.com/main/docs/creating-mermaid-diagrams
-#### (most determinate) Use other extracted fields as context
+## Options for locating context
-You can extract data from other extracted fields using the Source Ids parameter for supported LLM-based methods. In this case, the context is predetermined: it's the output from the other fields. For example, say you use the Text Table method to extract the following data in a `snacks_rank` table (not shown in json for brevity):
+#### (Most determinate) Use other extracted fields as context
+
+You can prompt an LLM to answer questions about other [fields](doc:field-query-object)' extracted data. In this case, the context is predetermined: it's the output from the other fields. For example, say you use the Text Table method to extract the following data in a `snacks_rank` table:
```json
snack annual regional sales
@@ -58,130 +74,84 @@ corn chips $200k
bananas $150k
```
-If you create a Query Group method with the prompt `what is the best-selling snack?`, and specify `snacks_rank` as the context using the Source IDs parameter, then Sensible searches for answers to your question only in the extracted `snacks_rank` table. This can be useful for:
+If you create a Query Group method with the prompt `what is the best-selling snack?`, and specify `snacks_rank` as the context using the Source IDs parameter, then Sensible searches for answers to your question only in the extracted `snacks_rank` table rather than in the entire document. Use other fields as context to:
+
+- Reformat or otherwise transform the outputs of other fields.
+- Compute or generate new data from the output of other fields
+- Narrow down the [context](doc:prompt#notes) for your prompts to a specific part of the document.
+- Troubleshoot or simplify complex prompts that aren't performing reliably. Break the prompt into several simpler parts, and chain them together using successive Source ID parameters in the fields array.
-- TBD prompt chaining etc
+To use other fields as context, configure the Source Ids parameter for the [Query Group](doc:query-group) or [List](doc:list#parameters) methods.
-#### (TBD/TODO: most what?) Find context with page summaries
+#### (Best for legalese) Find context with page summaries
-You can locate context using page summaries when you set the Search By Summarization parameter for supported LLM-based methods. Sensible uses a [completion-only retrieval-augmented generation (RAG) strategy](https://www.sensible.so/blog/embeddings-vs-completions-only-rag): Sensible prompts an LLM to summarize each page in the document, prompts a second LLM to return the pages most relevant to your prompt based on the summaries, and extracts the answers to your prompts from those pages' text.
+You can locate context using page summaries when you set the Search By Summarization parameter for supported LLM-based methods. Sensible uses a [completion-only retrieval-augmented generation (RAG) strategy](https://www.sensible.so/blog/embeddings-vs-completions-only-rag): Sensible prompts an LLM to summarize each page in the document, prompts a second LLM to return the pages most relevant to your prompt based on the summaries, and uses those pages' text as the context. This strategy is can be useful for long documents in which multiple mentions of the same concept make finding relevant context difficult.
-#### (most configurable) Find context with chunk embeddings scores
+#### (Most configurable) Find context with embeddings scores
-Sensible's default method for locating context is as follows:
+Sensible's default method for locating context is to split the document into fractional page chunks, score them for relevancy using embeddings, and then return the top-scoring chunks as context.
-1. To meet the LLM's input token limit, Sensible splits the document into chunks. These chunks are usually a fraction of a page and can overlap. Configurable parameters include:
+The following steps provide details about the parameters you can use to configure this process:
+1. To meet the LLM's input token limit, Sensible splits the document into chunks. These chunks are a fraction of a page and can overlap. Parameters that configure this step include:
- Chunk Count
- Chunk Size
- Chunk Overlap Percentage
- Page Range
- - MORE, depending on the method
-
-2. Sensible selects the most relevant chunks and combines them with page-hinting data to create a "context". Configurable parameters include:
-
+2. Sensible selects the most relevant chunks and combines them with page-hinting data to create a "context". Parameters that configure this step include:
1. Page Hinting
- 2. MORE depending on the method. for example, for List and Query Group, you can use the LLM Engine parameter to determine the # of relevant chunks Sensible selects as relelvant.
+ 2. LLM Engine parameter
-3. Sensible creates a full prompt for the LLM that includes the context and the descriptive prompts you configure in the method. In detail, when you write a prompt using an LLM-based method, Sensible creates a full prompt using the following:
-
- - a prompt introduction
-
- - "context", made up of chunks excerpted from the document and of page metadata.
-
- - concatenated descriptive prompts you configure in an LLM-based method, such as in the [List](doc:list) or [Query Group](doc:query-group) methods.
-
- - Configurable parameters include:
-
- 1. Context Description
-
- 1. TODO/2do: are there actually more?
+3. Sensible creates a *full prompt* for the LLM that includes the context and the descriptive prompts you configure in the method. Parameters that configure this step include:
+ 1. Context Description
4. Sensible returns the LLM's response.
For specifics about how each LLM-based method works, see the Notes section for each method's SenseML reference topic, for example, [List](doc:list#notes) method.
-You can configure a lot of the variables in the preceding steps:
+## Troubleshooting options
--
+See the following tips for troubleshooting situations in which large language model (LLM)-based extraction methods return inaccurate responses, nulls, or errors.
-See the following image for an example of a full prompt that Sensible inputs to an LLM for the [Query Group](doc:query-group) method:
-
-
+### Fix error messages
-The following table shows parameters that configure parts of the full prompt and that are global, or common to all LLM-based methods:
+**Error message**
-| key | description | todo/2do delete this? global parameters |
-| ---- | ------------------------------------------------------------ | ------------------------------------------------------------ |
-| A | Overall description of the chunks.
The preceding image shows an example of a user-configured context description overriding the default. | Context Description |
-| B | Page metadata for chunks. | Page Hinting |
-| C | Chunks excerpted from document, concatenated into "context" | Chunk Count
Chunk Size
Chunk Overlap Percentage
Page Range |
-| D | Concatenation of all the descriptive prompts you configured in the method. For example, concatenation of all the column descriptions and the overall table description for the [NLP Table](doc:nlp-table) method. | Description fields |
-
-
-
-
-
-### list
-
-For an overview of how this method works when `"searchBySummarization": false` and `source_ids` are unspecified, see the following steps:
-
-1. Sensible finds the chunks of the document that most likely contain your target data:
-
- - Sensible concatenates all your property descriptions with your overall list description.
-
- - Sensible splits the document into equal-sized chunks.
-
- - Sensible scores your concatenated list descriptions against each chunk.
-
-
-2. Sensible selects a number of the top-scoring chunks:
-
- 1. If you specify Thorough or Long for the LLM Engine parameter, the Chunk Count parameter determines the number of top-scoring chunks Sensible selects to submit to the LLM.
- 2. If you specify Fast for the LLM Engine parameter, 1. Sensible selects a number of top-scoring chunks as determined by the Chunk Count parameter. 2. To improve performance, Sensible removes chunks that are significantly less relevant from the list of top-scoring chunks. The number of chunks Sensible sumbits to the LLM can therefore be smaller than the number specified by the Chunk Count parameter.
+```
+ConfigurationError: LLM response format is invalid
+```
-3. To avoid large language model (LLM)'s input token limits, Sensible batches the chunks into groups. The chunks in each page group can come from non-consecutive pages in the document. If you set the Single LLM Completion parameter to True, then Sensible creates a single group that contains all the top-scoring chunks and sets a larger maximum token input limit for the single group (about 120k tokens) than it does for batched groups.
+**Notes**
-4. For each chunk group, Sensible submits a full prompt to the LLM that includes the chunks as context, page-hinting data, and your prompts. For information about the LLM model, see the LLM Engine parameter. For more information about the full prompt, see [Advanced LLM prompt configuration](doc:prompt). The full prompt instructs the LLM to create a list formatted as a table, based on the context.
+Reword the prompt in simpler terms, chain the prompt using the Source Ids parameter, or avoid specifying a format in the prompt for the extracted data. Or, add a fallback field to bypass the error if the original query is working for most documents and you're only seeing the error intermittently. See the following section for more information about fallbacks.
-5. Sensible concatenates the results from the LLM for each page group and returns a list, formatted as a table.
+Background: Sensible returns this error when the LLM doesn't return its response in the JSON format that Sensible specifies in the backend for [full prompts](doc:prompt). This can occur when your `description` parameters prompt the LLM to return data in a specific format that conflicts with the expected JSON format.
- ### NLP table
+### Interpret confidence signals
- For an overview of how the NLP Table method works, see the following steps:
+Confidence signals are an alternative to confidence scores and to error messages. For information about troubleshooting LLM confidence signals, such as `multiple_possible_answers` or `answer_maybe_be_incomplete`, see [Qualifying LLM accuracy](doc:confidence).
+### Create fallbacks for null responses or false positives
- 1. To optimize performance, Sensible makes a list of the pages that are most likely to contain your target table. To make the list:
- - Sensible concatenates all your column descriptions with your overall table description.
- - Sensible splits the document into equal-sized, overlapping chunks.
- - Sensible scores your concatenated table descriptions against each chunk using the OpenAI Embeddings API.
- - Sensible gets a list of page numbers from the top-scoring chunks.
- 2. Sensible extracts all the tables on the pages most likely to contain your table, using the [OCR engine](doc:ocr-engine) specified by the document type. Sensible supports multi-page tables.
- 3. Sensible scores each table by how well it matches the descriptions you provide of the data you want to extract. To create the score:
+Sometimes an LLM prompt works for the majority of documents in a document type, but returns null or an inaccurate response (a "false positive") for a minority of documents. Rather than rewrite the prompt, which can cause regressions, create fallbacks targeted at the failing documents. For more information, see [Fallback strategies](doc:fallbacks).
- - Sensible concatenates all your column descriptions with your overall table description.
+### Trace source context
- - Sensible concatenates a number of the first rows of the table with the table title. Sensible uses the table title extracted by the table OCR provider, or falls back to using the text in a region above the table if the OCR provider doesn't find a title.
+Tracing the document's source text, or [context](doc:prompt#notes), for an LLM's answer can help you determine if the LLM is misinterpreting the correct text, or targeting the wrong text.
- - Sensible compares the two concatenations using the OpenAI Embeddings API.
- 4. Sensible creates a full prompt for the LLM (as specified by the LLM Engine parameter) that includes the top-scoring table, page hinting data, and your prompts. For more information about the full prompt, see [Advanced LLM prompt configuration](doc:prompt). The full prompt instructs the LLM to rewrite or restructure the best-scoring table based on your column descriptions and your overall table description. Note that if you select `rewriteTable: false`, Sensible uses an LLM (GPT-4) to rewrite the column headings' IDs, but doesn't otherwise restructure the table.
- 5. Sensible returns the restructured table.
+You can view the source text for an LLM's answer highlighted in the document for the Query Group method:
-### query group
+- In the visual editor, click the **Location** button in the output of a query field to view its source text in the document. For more information about how location highlighting works and its limitations, see [Location highlighting](doc:query-group#notes).
+
+- In the JSON editor, Sensible displays location highlighting by outline the context with [blue boxes](doc:color).
-When you specify `source_ids` , Sensible uses the specified IDs as context. Otherwise, see the following notes:
+### Locate source context
-- For an overview of how this method works when `"searchBySummarization": false`, see the following steps.
- - To meet the LLM's token limit for input, Sensible splits the document into equal-sized, overlapping chunks.
- - Sensible scores each chunk by its similarity to either the concatenated Description parameters for the queries in the group, or by the `chunkScoringText` parameter. Sensible scores each chunk using the OpenAPI Embeddings API.
- - Sensible selects a number of the top-scoring chunks and combines them into "context". The chunks can be non-consecutive in the document. Sensible deduplicates overlapping text in consecutive chunks. If you set chunk-related parameters that cause the context to exceed the LLM's token limit, Sensible automatically reduces the chunk count until the context meets the token limit.
- - Sensible creates a full prompt for the LLM (as determined by the LLM Engine parameter) that includes the chunks, page hinting data, and your Description parameters. For more information about the full prompt, see [Advanced LLM prompt configuration](doc:prompt).
+Sometimes, an LLM fails to locate the relevant portion of the document that contains the answers to your prompts. To troubleshoot targeting the wrong source text, or [context](doc:prompt#notes), in the document:
-- For an overview of how this method works when `"searchBySummarization": true`, see the following steps.
- 1. Sensible prompts an LLM (GPT-4o mini) to summarize each page in the document. Sensible ignores the Chunk Scoring Text parameter.
+- For the Query Group method, add more prompts to the group that target information in the context, even if you don't care about the answer. For the List and NLP Table methods, add prompts to extract each item in the list or column in the table, respectively.
- 2. Sensible prompts an LLM (GPT-4o) with all the indexed page summaries as context, and asks it to return a number of page indices that are most relevant to your concatenated Description parameters. The Chunk Count parameter configures the number of page indices that the LLM returns. Sensible recommends setting the Chunk Count parameter to less than 10.
+- If the context occurs consistently in a page range in the document, use the Page Hinting or Page Range parameters to narrow down the context's possible location. For more information about these parameters, see [Advanced LLM prompt configuration](doc:prompt). (TODO: rename topic to "global parameters"? rm it entirely?)
- 3. Sensible prompts an LLM (as configured by the LLM Engine parameter) to answer your prompts, with the full text of the relevant pages as context. If you configure the Page Hinting parameter, it takes effect in this and the preceding step. If you configure the Multimodal Engine parameter, it takes effect in this step.
\ No newline at end of file