n_distinct way slower than length(unique) #977
Comments
|
A simulation and graph exploring the effect of vector length and uniqueness on the performance of library(dplyr)
library(microbenchmark)
set.seed(2015-08-05)
time_distinct <- function(uniques, len, class) {
x <- sample(uniques, len, replace = TRUE)
x <- as(x, class)
m <- microbenchmark(n_distinct(x),
length(unique(x)),
times = 1000L)
ret <- summary(m)
ret$uniques <- length(unique(x))
ret
}
timings <- expand.grid(uniques = round(10 ^ seq(0, 5, 1)),
len = round(10 ^ seq(1, 4, 1)),
class = c("numeric", "character"),
stringsAsFactors = FALSE) %>%
group_by(uniques, len, class) %>%
do(do.call(time_distinct, .))
library(ggplot2)
ggplot(timings, aes(uniques, median, color = expr, lty = class)) +
geom_line() +
scale_x_log10() +
geom_errorbar(aes(ymin = lq, ymax = uq), width = .1) +
facet_wrap(~ len, scales = "free") +
xlab("Number of unique elements in vector") +
ylab("Median time")
|

|
Confirmed. This will need some profiling, it's not immediately obvious where the extra time is spent. Some notes:
|
|
Can you please try |
|
Further improvements should be done in the context of r-lib/vctrs#8. |
|
I wonder if we can do better now with |
|
But there's also quadratic run time that occurs only when strings are involved, thanks @randomgambit: library(dplyr)
library(microbenchmark)
test <- function(N, M, transform = identity) {
x <- rep(seq_len(N), M)
y <- sample(transform(rep(seq_len(N), M)))
tbl <- tibble(x, y) %>% group_by(x)
tbl %>% mutate(n = n_distinct(y))
}
system.time(test(500, 1000))
#> user system elapsed
#> 0.104 0.004 0.109
system.time(test(1000, 1000))
#> user system elapsed
#> 0.304 0.012 0.316
system.time(test(1500, 1000))
#> user system elapsed
#> 0.412 0.004 0.417
system.time(test(2000, 1000))
#> user system elapsed
#> 0.639 0.004 0.644
system.time(test(2500, 1000))
#> user system elapsed
#> 0.665 0.024 0.690
system.time(test(3000, 1000))
#> user system elapsed
#> 0.936 0.040 0.976
system.time(test(500, 100, as.character))
#> user system elapsed
#> 0.082 0.000 0.082
system.time(test(1000, 100, as.character))
#> user system elapsed
#> 0.26 0.00 0.26
system.time(test(1500, 100, as.character))
#> user system elapsed
#> 0.586 0.000 0.586
system.time(test(2000, 100, as.character))
#> user system elapsed
#> 0.998 0.000 0.998
system.time(test(2500, 100, as.character))
#> user system elapsed
#> 1.559 0.000 1.559
system.time(test(3000, 100, as.character))
#> user system elapsed
#> 2.416 0.000 2.416
|
|
Is that the same thing as this perhaps: r-lib/tidyselect#56 |
|
There are two things here:
This might be a |
|
We need to use a profiler to identify the bottleneck here. Unfortunately, gprofiler doesn't work (yet) on the Mac, but I can take a look later. |
|
but for the mean time, perhaps we can isolate the special case when there is only one variable and use |
|
I'd like to see a profile before starting any action. |
|
At least, n_distinct still performs better when there are more than one variables: unsurprinsingly, because so it does a special case for the case when there is only one variable. |
|
I'll make this a use case for jointprof. |
|
@krlmlr any luck with the profiler ? |
|
Not yet, the timing is still consistent with the OP. Would you mind trying jointprof? The README should get you started: https://r-prof.github.io/jointprof/. (It has worked for me on OS X, but I haven't tried in a while.) |
|
I think I'll get on this once we can use the hashing from |
|
I am not sure whether this could be helpful for solving this issue but here is something that I came across yesterday while trying to figure out why my suppressPackageStartupMessages(library(tidyverse))
suppressPackageStartupMessages(library(data.table))
library(microbenchmark)
# create dummy data
df <- tibble(fact = rep(letters, each = 12 * 1e3),
month = rep(month.name, 26 * 1e3),
num = rep(sample(10000:100000, 312*10), 1e2),
prob = runif(312 * 1e3))
# run benchmark
microbenchmark(
dplyr = df %>%
group_by(fact, num) %>%
summarise(count = n_distinct(month))
,
data.table = as.data.table(df)[, .(count = n_distinct(month)), by = .(fact, num)]
, times = 1L)
#> Unit: milliseconds
#> expr min lq mean median uq
#> dplyr 64278.0464 64278.0464 64278.0464 64278.0464 64278.0464
#> data.table 377.4892 377.4892 377.4892 377.4892 377.4892
#> max neval
#> 64278.0464 1
#> 377.4892 1Created on 2019-03-01 by the reprex package (v0.2.1) Please let me know if I can be of any help. |
This comment has been minimized.
This comment has been minimized.
|
Very similar observation here, comparable to @MichaelAdolph. Confidential client data, so can't share more but key points are as follows:
Runs horribly slow. I.e. "I can't use this in production"-type slow. |
|
I can't reproduce this extreme slowness with the CRAN binaries, however it seems that dplyr is extremely sensitive to the optimisation flags it is compiled with. library(dplyr)
library(vctrs)
y <- rep(1:4096, 100)
bench::mark(
base = length(unique(y)),
dplyr = n_distinct(y),
vctrs = vec_unique_count(y)
)[1:6]
## Optimised binaries
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 base 4.11ms 4.69ms 194. 5.58MB 24.5
#> 2 dplyr 7.61ms 8.09ms 123. 2.39KB 0
#> 3 vctrs 4.4ms 4.85ms 196. 5.57MB 22.9
## No optimisation (except for base)
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 base 4.12ms 4.62ms 212. 5.58MB 39.1
#> 2 dplyr 53.58ms 54.95ms 18.1 0B 0
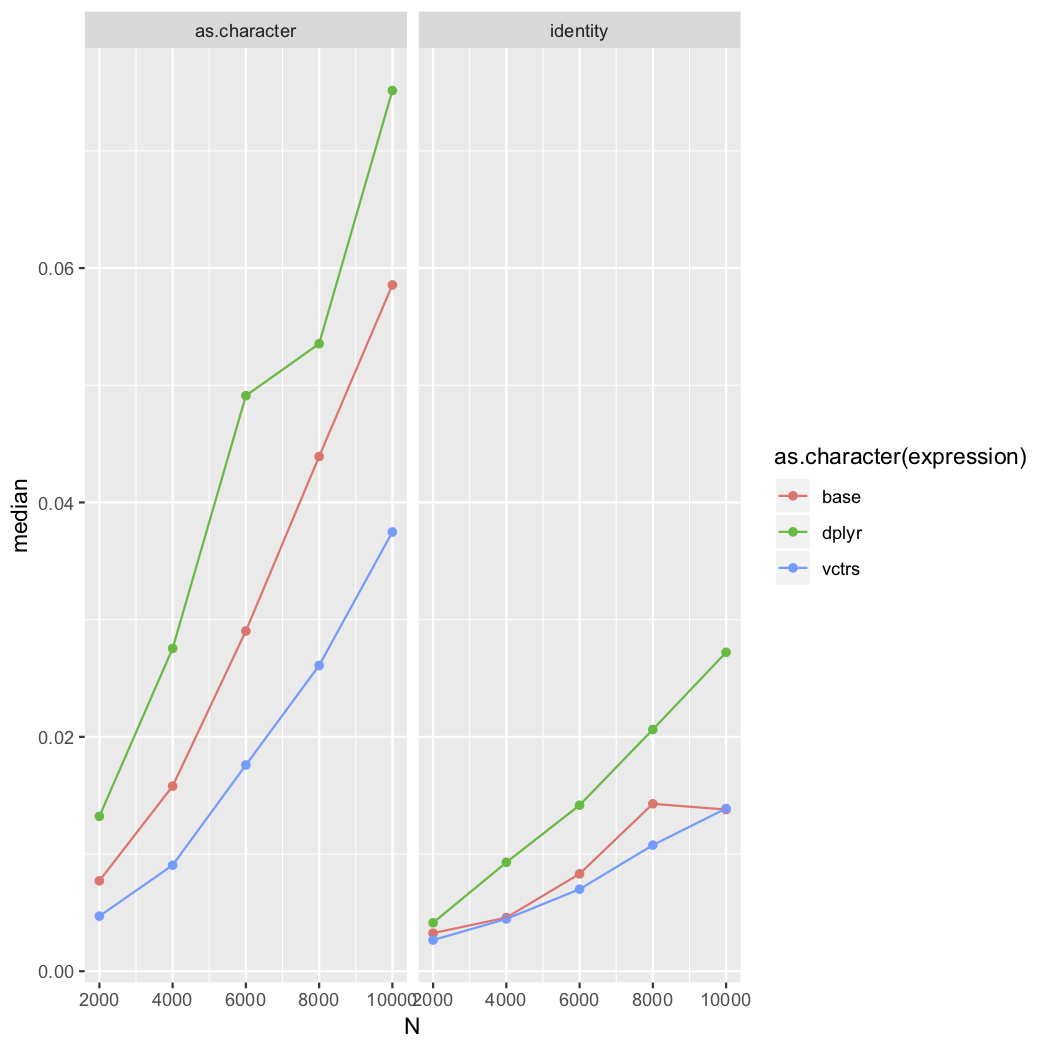
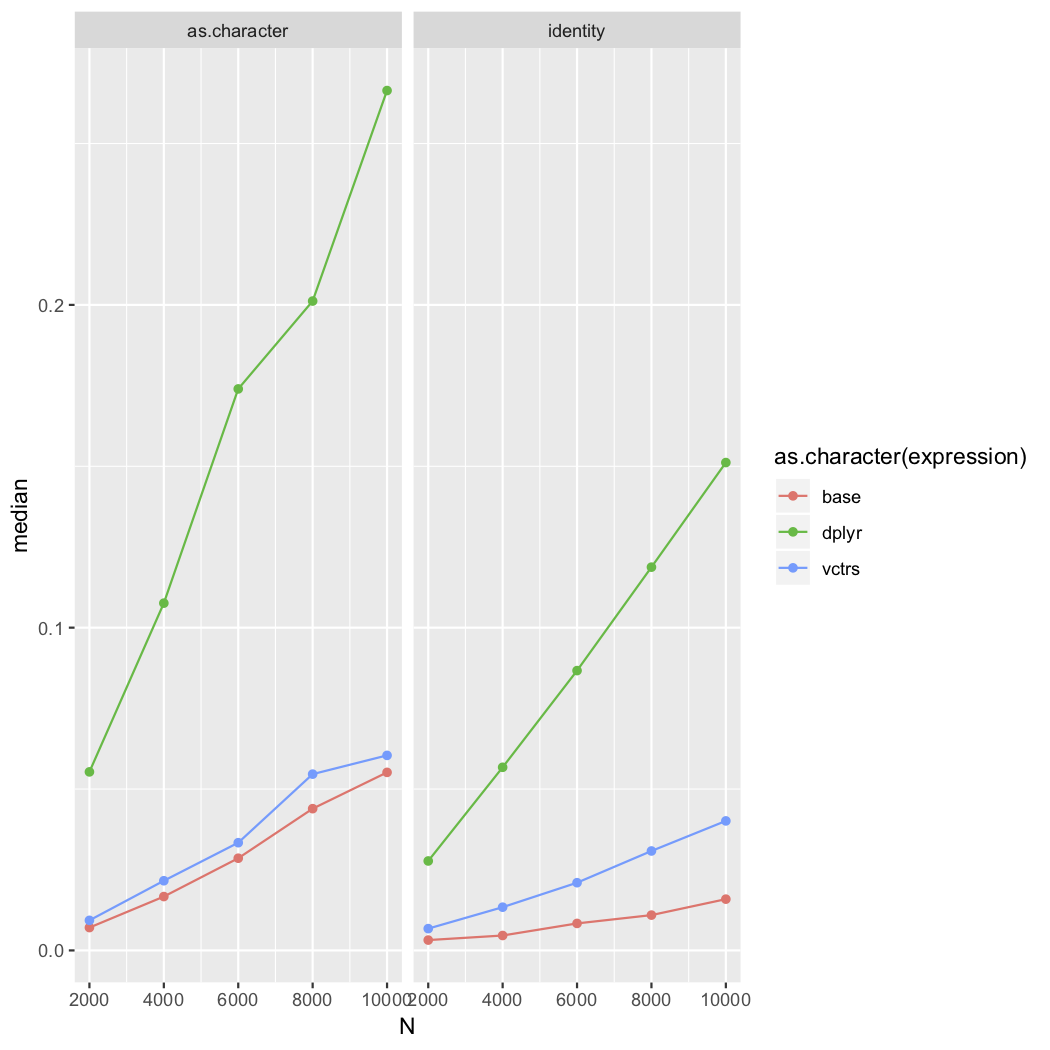
#> 3 vctrs 13.13ms 13.51ms 73.1 5.57MB 11.8The debug builds are especially slow with strings: library(dplyr)
library(vctrs)
res <- bench::press(
N = c(2000, 4000, 6000, 8000, 10000),
fn = c("identity", "as.character"),
{
M <- 100
x <- rep(seq_len(N), M)
# Can't press over a list?
fn <- get(fn)
y <- sample(fn(x))
bench::mark(
base = length(unique(y)),
dplyr = n_distinct(y),
vctrs = vec_unique_count(y)
)
}
)
library(ggplot2)
res %>%
ggplot(aes(
N,
median,
colour = as.character(expression)
)) +
geom_point() +
geom_line() +
facet_wrap(~fn)Release build
Debug build
IIUC, dplyr uses an STL hashmap? That could explain the slowness, as heavily templated C++ code is known to have slow debug builds, they need compiler inlining for speed. |
|
Thanks @lionel-! We'll switch the implementation to use |
uff, for real? This thing just killed my R numerous times. Maybe as a workaround warn the users? |
Can you post a reprex with a problematic case? I couldn't find anything wrong as long as dplyr is properly compiled with optimisations. I may have missed something. |
|
I can provide an extreme example that I was fighting last week. In my case I'm working with a data frame of about 4.6 million rows. But I can provide an example with a smaller set of records. I group by one column and then am summarizing the distinct counts of two of other columns. Using n_distinct it ran for about 2 hours. After I googled a bit and found this issue I changed it to use length(unique()) and it now runs in about 1 second. The example file I'm providing includes only 500,000 records. I'm attaching the data file to this comment. As mentioned the full dataset of 4.6 million records does take at least 2 hours for the dplyr version to run. library(microbenchmark)
library(dplyr)
load("/tmp/small_problems.Rdata")
microbenchmark(
namesSummary_base = small_problems %>%
group_by(tolower(problem_name)) %>%
summarise(n = n(),
numPractices = length(unique(rowkey)),
numAnimals = length(unique(rowkey))
),
namesSummary_dplyr = small_problems %>%
group_by(tolower(problem_name)) %>%
summarise(n = n(),
numLocations = n_distinct(location_id),
numAnimals = n_distinct(rowkey)),
times = 1L)
#> Unit: milliseconds
#> expr min lq mean median uq max neval
#> namesSummary_base 434.6912 434.6912 434.6912 434.6912 434.6912 434.6912 1
#> namesSummary_dplyr 27125.2335 27125.2335 27125.2335 27125.2335 27125.2335 27125.2335 1Created on 2019-05-28 by the reprex package (v0.3.0) My dplyr version is 0.8.0.1 and I'm running on Ubuntu Linux 19.04. I don't know how users are supposed to know if the dplyr we are using was "properly compiled with optimisations", so if there are special instructions for installing the dplyr package it needs to be documented. |
|
Interestingly, I just thought I'd see if there was a newer version of dplyr out there and updated to 0.8.1 off of CRAN. I re-ran the test and now the dplyr version is just as fast as the base R version. Here are the results using dplyr 0.8.1 of the above example I provided. |
|
@dkincaid Thanks, confirmed that with 0.8.0, a single run of your example takes 3 minutes with a debug build and 39s with a release build. On 0.8.1, the slowness is gone. Any idea what might have fixed it @romainfrancois? Perhaps something to do with groups or hybrid eval? 0.8.1## Release build
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 namesSummary_base 545ms 545ms 1.83 36.88MB 5.50
#> 2 namesSummary_dplyr 424ms 444ms 2.25 8.48MB 1.13
## Debug build
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 namesSummary_base 881.94ms 881.94ms 1.13 38.88MB 1.13
#> 2 namesSummary_dplyr 1.32s 1.32s 0.757 9.04MB 00.8.0.1## Release build
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 namesSummary_base 699ms 699ms 1.43 93.49MB 7.15
#> 2 namesSummary_dplyr 39s 39s 0.0256 8.58MB 0
## Debug build
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 namesSummary_base 1.01s 1.01s 0.990 93.49MB 2.97
#> 2 namesSummary_dplyr 3.26m 3.26m 0.00511 8.58MB 0I don't know of any documentation for configuring compilation, except for https://cran.r-project.org/doc/manuals/r-release/R-admin.pdf. My guess is that your distribution creates a correctly configured CFLAGS += -O3
CXXFLAGS += -O3
CXX1XFLAGS += -O3When you install a package, check the output for |
|
I don't recall right now. Might be an accidental fix 😆 |
|
This old issue has been automatically locked. If you believe you have found a related problem, please file a new issue (with reprex) and link to this issue. https://reprex.tidyverse.org/ |
I would like to move to more uniform implementation of dplyr memes; I really like the syntax. However, I am seeing several instances where dplyr analogues to plyr or base-R functions incur a severe performance hit on my data sets.
Here is a simple example ilustrating that dplyr's n_distinct is a factor of two slower than base-R.
The results are:
The text was updated successfully, but these errors were encountered: