7 простых JavaScript функций, показывающих, как машина может «учиться»
На других языках: English, Português
Нано-нейрон — это упрощенная версия нейрона из концепции нейронной сети. Нано-нейрон выполняет простейшую задачу и натренирован на конвертацию температуры из градусов Цельсия в градусы Фаренгейта.
Код NanoNeuron.js состоит из 7 простых JavaScript функций, затрагивающих обучение, тренировку, предсказание, прямое и обратное распространение сигнала модели. Целью написания этих функций было дать читателю минимальное, базовое объяснение (интуицию) того, как же все-таки машина может «обучаться». В коде не используются сторонние библиотеки. Как-говорится, только простые «vanilla» JavaScript функции.
Эти функци ни в коей мере не являются исчерпывающим руководством по машинному обучению. Множество концепций машинного обучения в них пропущено или же упрощено! Это упрощение допущено с единственной целью — дать читателю самое базовое понимание и интуицию о том, как машина в принципе может «учиться», чтобы в итоге «МАГИЯ машинного обучения» звучала для читателя все более как «МАТЕМАТИКА машинного обучения».
Вы, возможно, слышали о нейронах в контексте нейронных сетей. Нано-нейрон является упрощенной версией того самого нейрона. В этом примере мы напишем его реализацию с нуля. Для простоты примера мы не будем строить сеть из нано-нейронов. Мы остановимся на создании одного единственного нано-нейрона и попробуем научить его конвертировать температуру из градусов Цельсия в градусы Фаренгейта. Другими словами мы научим его предсказывать температуру в градусах Фаренгейта на основании температуры в градусах Цельсия.
Кстати, формула для конвертации градусов Цельсия в градусы Фаренгейта выглядит следующим образом:
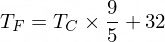
Но на данный момент наш нано-нейрон ничего об этой формуле не знает...
Начнем с создания функции, описывающей модель нашего нано-нейрона. Эта модель представляет собой простую линейную зависимость между x и y, которая выглядит следующим образом: y = w * x + b. Проще говоря, наш нано-нейрон — это ребенок, который умеет рисовать прямую линию в системе координат XY.
Переменные w и b являются параметрами модели. Нано-нейрон знает только эти два параметра линейной функции. Эти параметры как-раз и есть тем, что наш нано-нейрон будет учить во время процесса тренировки (обучения).
Единственная вещь, которую нано-нейрон на данном этапе умеет делать — это имитировать линейные зависимости. Делает он это в методе predict(), который принимает переменную x на входе и предсказывает переменную y на выходе. Никакой магии.
function NanoNeuron(w, b) {
this.w = w;
this.b = b;
this.predict = (x) => {
return x * this.w + this.b;
}
}(...постой... линейная регрессия это ты, что ли?)
Температура в градусах Цельсия может быть преобразована в градусы Фаренгейта по формуле: f = 1.8 * c + 32, где c — температура в градусах Цельсия и f — температура в градусах Фаренгейта.
function celsiusToFahrenheit(c) {
const w = 1.8;
const b = 32;
const f = c * w + b;
return f;
};В итоге мы хотим, чтобы наш нано-нейрон смог имитировать именно эту функцию. Он должен будет сам догадаться (научиться), что параметр w = 1.8 и b = 32 не зная об этом заранее.
Вот так функция конвертации выглядит на графике. Именно ее должен научиться «рисовать» наш нано-нейронный «малыш»:
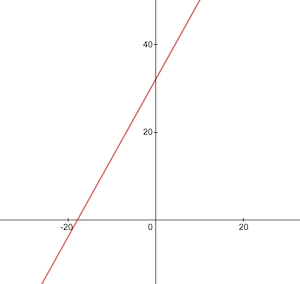
В классическом программировании нам известны данные на входе (x) и алгоритм преобразования этих данных (параметры w и b), но неизвестны выходные данные (y). Выходные данные вычисляются на основании входных с помощью известного нам алгоритма. В машинном обучении же напротив, известны лишь входные и выходные данные (x и y), а вот алгоритм перехода от x к y неизвестен (параметры w и b).
Именно генерацией входных и выходных данных мы сейчас и займемся. Нам необходимо сгенерировать данные для тренировки нашей модели и данные для тестирования модели. В этом нам поможет функция-помощник celsiusToFahrenheit(). Каждый из тренировочных и тестовых наборов данных представляет собой множество пар x и y. Например, если x = 2, то y = 35,6 и так далее.
В реальном мире, в основном, данные скорее-всего будут собраны, а не cгенерированы. Например, такими собранными данными может быть набор пар «фото лица» --> «имя человека».
Мы будем использовать ТРЕНИРОВОЧНЫЙ набор данных для обучения нашего нано-нейрона. Перед тем как тот вырастет и будет способен принимать решения самостоятельно мы должны научить его что является «правдой», а что «ложью» используя «правильные» данные из тренировочного набора.
Кстати, тут явно прослеживается жизненный принцип «мусор на входе — мусор на выходе». Если нано-нейрончику в тренировочный набор подкинуть «ложь», что 5°C конвертируются в 1000°F, то через много итераций обучения он станет этому верить и будет корректно конвертировать все значения температуры кроме 5°C. Нам надо быть очень осторожными с теми тренировочными данными, которые мы каждый день загружаем нашей мозговой нейронной сеточке.
Отвлекся. Продолжим.
Мы будем использовать ТЕСТОВЫЙ набор данных для оценки того, насколько наш нано-нейрон хорошо обучился и может делать корректные предсказания на новых данных, которых он не видел во время своего обучения.
function generateDataSets() {
// xTrain -> [0, 1, 2, ...],
// yTrain -> [32, 33.8, 35.6, ...]
const xTrain = [];
const yTrain = [];
for (let x = 0; x < 100; x += 1) {
const y = celsiusToFahrenheit(x);
xTrain.push(x);
yTrain.push(y);
}
// xTest -> [0.5, 1.5, 2.5, ...]
// yTest -> [32.9, 34.7, 36.5, ...]
const xTest = [];
const yTest = [];
// Начав с 0.5 и используя шаг 1, который мы использовали для тренировочного набора
// мы можем утверждать, что тестовый и тренировочный наборы не пересекаются.
for (let x = 0.5; x < 100; x += 1) {
const y = celsiusToFahrenheit(x);
xTest.push(x);
yTest.push(y);
}
return [xTrain, yTrain, xTest, yTest];
}Нам необходима определенная метрика (измерение, число, оценка), которая покажет насколько близко предсказание нано-нейрона к истинному. Другими словами это число/метрика/функция должна показать, насколько нано-нейрон прав или неправ. Это как в школе, ученик может за свою контрольную получить оценку 5 или 2.
В случае с нано-нейроном его ошибка (погрешность) между истинным значением y и предсказанным значением prediction будем производить по формуле:
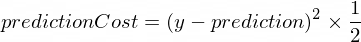
Как видно из формулы мы будем считать ошибку, как простую разницу между двумя значениями. Чем ближе значения друг к другу, тем меньше эта разница. Мы используем возведения в квадрат здесь для того, чтобы избавиться от знака, чтобы в итоге (1 - 2) ^ 2 было равнозначно (2 - 1) ^ 2. Деление на 2 происходит исключительно для того, чтобы упростить значение производной этой функции в формуле обратного распространения сигнала (об этом ниже).
Функция ошибки в данном случае будет выглядеть следующим образом:
function predictionCost(y, prediction) {
return (y - prediction) ** 2 / 2; // i.e. -> 235.6
}Произвести прямое распространение сигнала через нашу модель означает осуществить предсказания для всех пар из тренировочного набора данных xTrain и yTrain и вычислить среднюю ошибку (погрешность) этих предсказаний.
Мы всего-лишь даем нашему нано-нейрону «высказаться», позволяя ему сделать предсказания (конвертировать температуру). При этом нано-нейрон на данном этапе может очень сильно ошибаться. Среднее значение ошибки предсказания покажет нам насколько наша модель далека/близка к истине на данный момент. Значение ошибки здесь очень важно, поскольку изменив параметры w и b и произведя прямое распространение сигнала снова, мы сможем оценить стал ли наш нано-нейрон «умнее» с новыми параметрами или нет.
Средняя ошибка предсказаний нано-нейрона будет выполняться по следующей формуле:
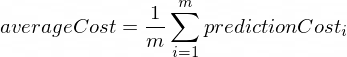
Где m — количество тренировочных экземпляров (в нашем случае у нас 100 пар данных).
Вот как мы можем реализовать это в коде:
function forwardPropagation(model, xTrain, yTrain) {
const m = xTrain.length;
const predictions = [];
let cost = 0;
for (let i = 0; i < m; i += 1) {
const prediction = nanoNeuron.predict(xTrain[i]);
cost += predictionCost(yTrain[i], prediction);
predictions.push(prediction);
}
// Нас интересует среднее значение ошибки.
cost /= m;
return [predictions, cost];
}Теперь, когда мы знаем насколько наш нано-нейрон прав или неправ в своих предсказаниях (основываясь на среднем значении ошибки), как мы можем сделать предсказания более точными?
Обратное распространения сигнала поможет нам в этом. Обратное распространение сигнала — это процесс оценки ошибки нано-нейрона и последующей корректировки его параметров w и b так, чтобы очередные предсказания нано-нейрона для всего набора тренировочных данных стали чуть-чуть точнее.
Вот здесь машинное обучение становится похожим на магию. Ключевая концепция здесь — это производная функции, которая показывает какого размера шаг и в какую сторону нам надо сделать, чтобы приблизиться к минимуму функции (в нашем случае к минимуму функции ошибки).
Конечной целью обучения нано-нейрона является нахождение минимума функции ошибки (см. функцию выше). Если нам удастся найти такие значения w и b при которых среднее значение функции ошибки будет маленьким, то это будет означать, что наш нано-нейрон неплохо справляется с предсказаниями температуры в градусах Фаренгейта.
Производные — это большая и отдельная тема, которую мы не покроем в этой статье. MathIsFun — отличный ресурс, который может дать базовое понимание производных.
Одна вещь, которую мы должны вынести из сути производной и которая поможет нам понять как работает обратное распространение сигнала — это то, что производная функции в определенной точке x и y, по своему определению, представляет собой касательную линию к кривой этой функции в точке x и y и указывает нам на направление к минимуму функции.

Изображение взято из MathIsFun
Например, на графике выше, вы видите, что в точке (x=2, y=4) наклон касательной показывает нам, что нужно двигаться влево и вниз, чтобы добраться до минимума функции. Также обратите внимание, что чем больше наклон касательной, тем быстрее мы должны двигаться к точке минимума.
Производные нашей средней функции ошибки averageCost по параметрам w и b будет выглядеть следующим образом:
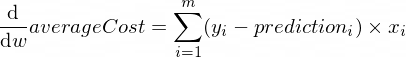
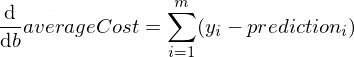
Где m — количество тренировочных экземпляров (в нашем случае у нас 100 пар данных).
Вы можете прочесть более детально о том, как брать производную сложных функций здесь.
function backwardPropagation(predictions, xTrain, yTrain) {
const m = xTrain.length;
// В начале мы не знаем насколько мы должны изменить параметры 'w' и 'b'.
// Поэтому размер шага пока равен 0.
let dW = 0;
let dB = 0;
for (let i = 0; i < m; i += 1) {
dW += (yTrain[i] - predictions[i]) * xTrain[i];
dB += yTrain[i] - predictions[i];
}
// Нас интересуют средние значения.
dW /= m;
dB /= m;
return [dW, dB];
}Теперь мы знаем, как оценить погрешность/ошибку предсказаний модели нашего нано-нейрона для всех тренировочных данных (прямое распространение сигнала). Мы так же знаем, как делать корректировку параметров w и b модели нано-нейрона (обратное распространение сигнала), чтобы улучшить точность предсказаний. Проблема в том, что если мы произведем прямое и обратное распространение сигнала всего один раз, то этого будет недостаточно для нашей модели, чтобы выявить и выучить зависимости и законы в тренировочных данных. Вы можете сравнить это с однодневным посещением школы учеником. Он/она должны ходить в школу регулярно, день за днем, год за годом, чтобы выучить весь материал.
Итак, мы должны повторить прямое и обратное распространение сигнала много раз. Этим как-раз и занимается функция trainModel(). Она будто «учительница» для модели нашего нано-нейрона:
- она проведет определенное время (
epochs) с нашим пока еще глупеньким нано-нейроном, пытаясь обучить его, - она будет использовать специальные книги (
xTrainиyTrainнаборы данных) для обучения, - она будет стимулировать нашего «ученика» учиться прилежнее (быстрее) используя параметр
alpha, который по сути регулирует скорость обучения.
Пару слов о параметре alpha. Это всего-лишь коэффициент (умножитель) для значений переменных dW и dB, которые мы вычисляем во время обратного распространения сигнала. Итак, производная показала нам направление к минимуму функции ошибки (об этом нам говорят знаки значений dW и dB). Также производная показала нам как быстро нам надо двигаться в сторону минимума функции (об этом нам говорят абсолютные значения dW и dB). Теперь нам надо умножить размер шага на alpha, чтобы отрегулировать скорость нашего приближения к минимуму (итоговый размер шага). Иногда, если мы будем использовать большие значения для alpha, мы можем идти настолько большими шагами, что можем попросту переступить минимум функции, тем самым пропустив его.
По аналогии с «учительницей», чем сильнее она заставляла бы нашего «нано-ученика» учиться, тем быстрее бы он выучился, НО, если заставлять и давить на него очень сильно, то у нашего «нано-ученика» может случиться нервный срыв и полная апатия и он совсем ничего не выучит.
Мы будем обновлять параметры нашей модели w и b следующим образом:
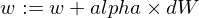
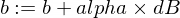
И вот так выглядит сама тренировка:
function trainModel({model, epochs, alpha, xTrain, yTrain}) {
// Это история обучения нашего нано-нейрона. Дневник успеваемости.
const costHistory = [];
// Начнем считать дни (эпохи) обучения
for (let epoch = 0; epoch < epochs; epoch += 1) {
// Прямое распространение сигнала.
const [predictions, cost] = forwardPropagation(model, xTrain, yTrain);
costHistory.push(cost);
// Обратное распространение сигнала.
const [dW, dB] = backwardPropagation(predictions, xTrain, yTrain);
// Корректируем параметры модели нано-нейрона, чтобы улучшить точность предсказаний.
nanoNeuron.w += alpha * dW;
nanoNeuron.b += alpha * dB;
}
return costHistory;
}Время использовать все ранее созданные функции вместе.
Создадим экземпляр модели нано-нейрона. На данный момент нано-нейрон не знает ничего о том, какими должны быть параметры w и b. Так что давайте установим w и b случайным образом.
const w = Math.random(); // i.e. -> 0.9492
const b = Math.random(); // i.e. -> 0.4570
const nanoNeuron = new NanoNeuron(w, b);Генерируем тренировочный и тестовый наборы данных.
const [xTrain, yTrain, xTest, yTest] = generateDataSets();Теперь давайте попробуем натренировать нашу модель используя небольшие шаги (0.0005) в течение 70000 эпох. Вы можете поэкспериментировать с этими параметрами, они определяются эмпирическим путем.
const epochs = 70000;
const alpha = 0.0005;
const trainingCostHistory = trainModel({model: nanoNeuron, epochs, alpha, xTrain, yTrain});Проверим, как изменялось значение ошибки нашей модели во время тренировки. Мы ожидаем, что значение ошибки после тренировки должно быть значительно меньше, чем до тренировки. Это означало бы, что наш нано-нейрон поумнел. Возможен также и противоположный вариант, когда после тренировки, погрешность предсказаний только выросла (например больших значениях шага обучения alpha).
console.log('Ошибка до тренировки:', trainingCostHistory[0]); // i.e. -> 4694.3335043
console.log('Ошибка после тренировки:', trainingCostHistory[epochs - 1]); // i.e. -> 0.0000024А вот как значение ошибки модели изменялось во время тренировки. По оси x находятся эпохи (в тысячах). Ожидаем, что график будет убывающим.
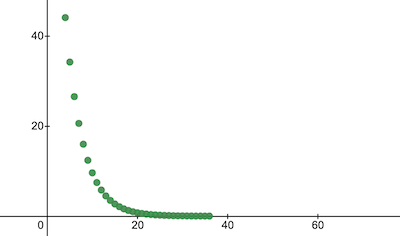
Давайте посмотрим на то, какие параметры «выучил» наш нано-нейрон. Ожидаем, что параметры w и b будут похожими на одноименные параметры из функции celsiusToFahrenheit() (w = 1.8 и b = 32), ведь именно ее наш нано-нейрон пытался имитировать.
console.log('Параметры нано-нейрона:', {w: nanoNeuron.w, b: nanoNeuron.b}); // i.e. -> {w: 1.8, b: 31.99}Как видим, нано-нейрон очень близок к функции celsiusToFahrenheit().
А теперь давайте посмотрим насколько точны предсказания нашего нано-нейрона для тестовых данных, которых он не видел во время обучения. Ошибка предсказаний для тестовых данных должна быть близкой к ошибке предсказаний для тренировочных данных. Это будет означать, что нано-нейрон выучил правильные зависимости и может корректно абстрагировать свой опыт и на ранее неизвестные ему данные (в этом ведь вся ценность модели).
[testPredictions, testCost] = forwardPropagation(nanoNeuron, xTest, yTest);
console.log('Ошибка на новых данных:', testCost); // i.e. -> 0.0000023Теперь, поскольку наш «нано-малыш» хорошо обучился в «школе» и теперь умеет достаточно точно конвертировать градусы Цельсия в градусы Фаренгейта даже для данных, которых он не видел, мы можем назвать его достаточно «умненьким». Теперь мы даже можем спрашивать у него совета касательно конвертации температуры, а ведь это и была цель всего обучения.
const tempInCelsius = 70;
const customPrediction = nanoNeuron.predict(tempInCelsius);
console.log(`Нано-нейрон "думает", что ${tempInCelsius}°C в Фаренгейтах будет:`, customPrediction); // -> 158.0002
console.log('А правильный ответ:', celsiusToFahrenheit(tempInCelsius)); // -> 158Очень близко! Как и люди, наш нано-нейрон — хорош, но не идеален :)
Успешного кодинга!
Вы можете клонировать репозиторий и запустить нано-нейрон локально:
git clone https://github.com/trekhleb/nano-neuron.git
cd nano-neuronnode ./NanoNeuron.jsСледующие концепции машинного обучения были упущены или упрощены для простоты объяснения.
Разделение тренировочного и тестового наборов данных
Обычно у вас есть один большой набор данных. В зависимости от количества экземпляров в этом наборе его разделение на тренировочный и тестовый наборы может осуществляться в пропорции 70/30. Данные в наборе должны быть случайным образом перемешаны перед разделением. Если же количество данных большое (например, миллионы), то разделение на тестовый и тренировочный наборы может производиться в пропорциях близких к 90/10 или 95/5.
Сила в сети
Обычно вы не найдете случаев, когда используется всего-лишь один нейрон. Сила именно в сети таких нейронов. Нейронная сеть может выучить гораздо более сложные зависимости.
Так же в примере выше, наш нано-нейрон может выглядеть скорее как простая линейная регрессия, чем как нейронная сеть.
Нормализация входных данных
Перед тренировкой принято производить нормализацию входных данных.
Векторная имплементация
Для нейронных сетей векторные (матричные) вычисления производятся значительно быстрее, чем вычисления в циклах for. Обычно прямое и обратное распространение сигнала производится именно с использованием матричных операций с использованием, например Python библиотеки Numpy.
Минимум функции ошибки
Функция ошибки, которую мы использовали для нано-нейрона очень упрощена. Она должна содержать логарифмические компоненты. Изменение формулы функции ошибки так же повлечет за собой изменение формул для прямого и обратного распространения сигнала.
Функция активации
Обычно выходное значение нейрона проходит еще через функцию активации. Для активации могут использоваться такие функции, как Sigmoid, ReLU и прочие.