Subscriber
AresDB subscriber consumes messages from Kafka; transforms data based on configuration; upserts batch to sink (AresDB server or Kafka). It is designed as message lossless and supports AresDB single node mode and distributed mode.

In AresDB single node mode, subscriber first registers itself in etcd as a lease node; then periodically fetches job assignments from controller, consumes messages from Kafka, transforms and batches messages; finally directly sends batch of rows to one AresDB server.

In AresDB distributed mode, subscriber first registers itself in etcd as a lease node; then periodically fetches job assignments and enum dictionary from controller, consumes messages from Kafka, transforms messages to AresDB upsert batch format, partitions upsert batches based on table primary keys; finally publishes batches to its specified partitionID in Kafka. On AresDB cluster side, each server consumes upsert batches for the assigned shards.
AresDB subscriber first fetches all job assignments from AresDB controller, and then starts all consumers. Once initialization is complete, AresDB subscriber is running in four scenarios: Normal
- Normal
In this case, AresDB subscriber continuously consumes messages from Kafka, transforms data, upserts batch into sink(AresDB server or msg_out_topic in kafka) , and then commit the message offset.
- Add a job config
AresDB subscriber periodically checks AresDB controller. If there is a new job (ie, “add a job config”), it first creates consumer for the topic, and then continuously consumes messages from Kafka, transforms data, upserts batch into AresDB server, and then commit the message offset.
- Update a job config
AresDB subscriber periodically checks AresDB controller. If there is a job config update (ie, “update job config”), it first restarts consumer for the topic, and then continuously consumes messages from Kafka, transforms data, upserts batch into AresDB server, and then commit the message offset.
- Delete a job config
AresDB subscriber periodically checks AresDB controller. If there is a job config delete (ie, “delete a table config”), It triggers the consumer is closed.
AresDB subscriber uses namespace concept to achieve scalability. It can supports local static configuration or dynamic configuration from AresDB Controller.
In static configuration file, namespace is applied on ares cluster level and job level. A ares cluster namespace defines a set of aresDB hosts; a job namespace defines a set of job names. One aresDB subscriber is an instance which loads a pair of aresDB namespace and job namespace configuration. For example:
ares:
# A list of namespaces. Each namespace includes a list of ares clusters
namespaces:
dev01:
- dev-ares01
- dev-ares02
# A list of aresDB hosts. Each cluster includes master node address
hosts:
dev-ares01:
address: "localhost:9998"
timeout: 5
dev-ares02:
address: "localhost:9999"
timeout: 5
# A list of jobs which are defined in config/jobs
jobs:
# A list of namespaces. Each namespace includes a list of jobs.
namespaces:
job-test1:
- test1
job-test2:
- test2
Internally aresDB subscriber uses a map to maintain the relationship between sink(aresDB server or kafka) and jobs. For example.
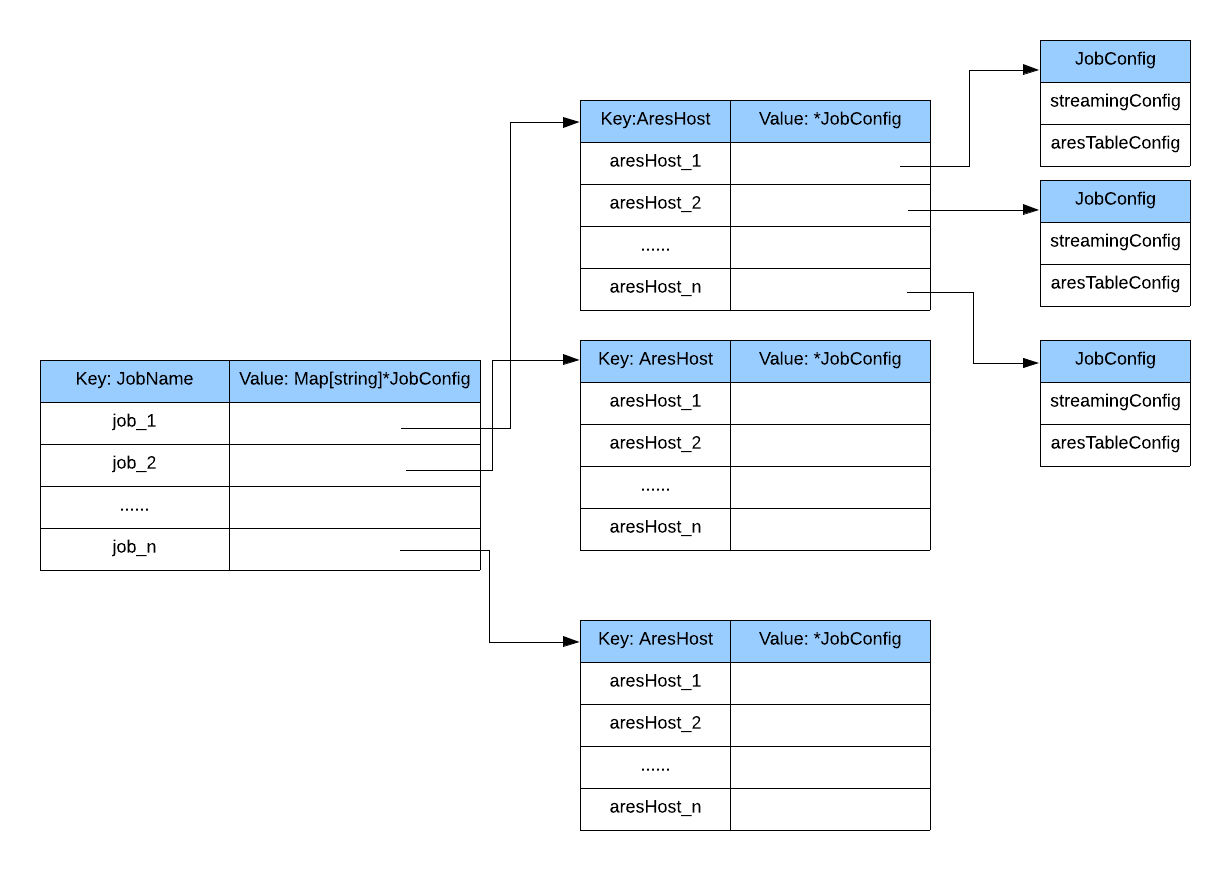
AresDB subscriber is not only able to maximize parallelism, but also to guarantee message lossless. Internally, one job has one or more drivers; one driver has one or more processors; one processor has one or more threads to handle batch upserts. The job commits Kafka offset once a batch upserts succeeds.
A processor maintains one taskQueue and one batchQueue. It has one consumer to consume&decode messages from Kafka and put messages into taskQueue; one batch worker fetches messages from taskQueue, creates batches and save to batchQueue; one db worker fetches batches from batchQueue, parses/transforms a batch, creates upsert batches, starts one or more threads to save messages into aresDB, finally commits kafka offset for this batch.
