RNN分类之后, 在评估处怎么获得每个字符的概率呢 #50
Comments
|
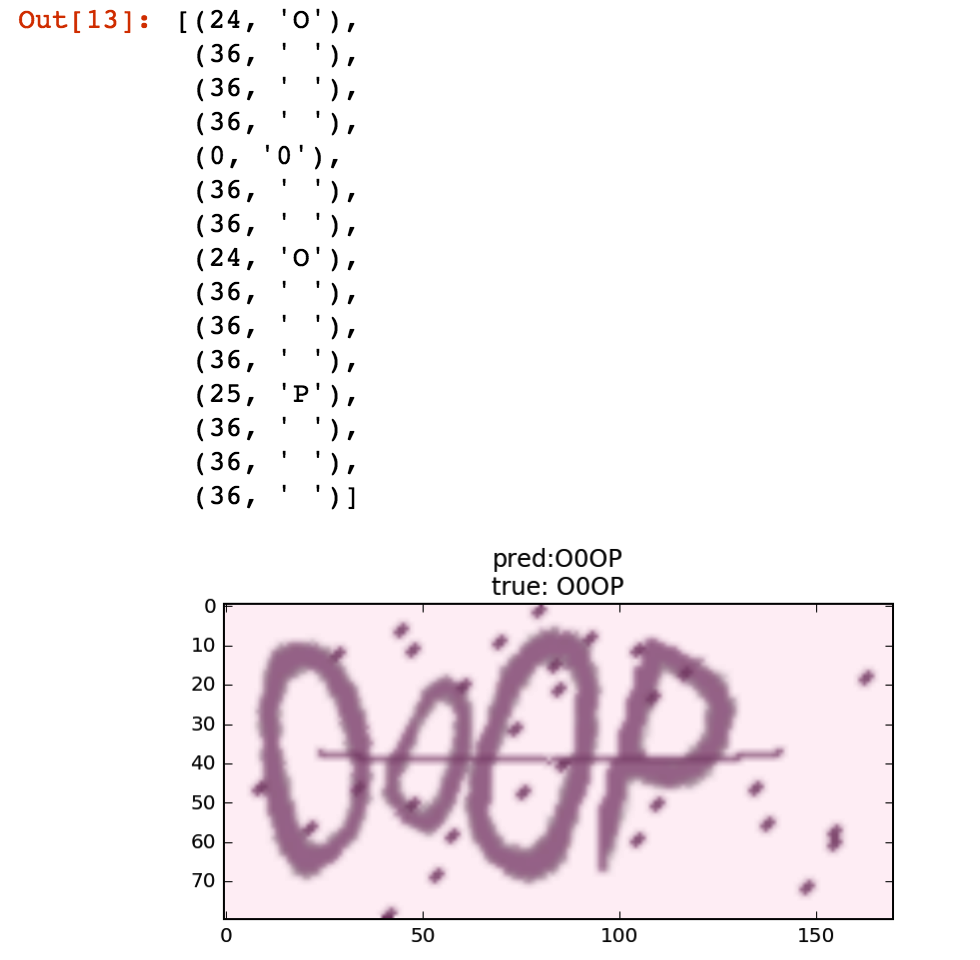
y_pred 就是每个字符的概率,比如我们可以对 y_pred 的概率找最大的值来看输出的概率对应的字符: argmax = np.argmax(y_pred, axis=2)[0]
list(zip(argmax, ''.join([characters2[x] for x in argmax])))
|
# for free
to join this conversation on GitHub.
Already have an account?
# to comment
out = K.get_value(K.ctc_decode(y_pred, input_length=np.ones(shape[0]) * shape[1])[0][0])[:, :4]每个字符的概率该如何读出,我对RNN不熟悉,请大佬指点迷津,万分感谢
The text was updated successfully, but these errors were encountered: