We introduce SEED-X, a unified and versatile foundation model, which can serve as various multimodal AI assistants in the real world after different instruction tuning, capable of responding to a variety of user needs through unifying multi-granularity comprehension and generation.
All models, instruction tuning code and inference code are released!
2024-07-12 🤗 We release SEED-Story, a MLLM capable of generating multimodal long stories based on the pre-trained SEED-X (an earlier version). We also release StoryStream, a large-scale dataset designed for training and benchmarking multimodal story generation.
2024-05-21 🤗 A new online demo of the general instruction-tuned model SEED-X-I is available, with faster inference speed than the demo using Zero GPU on huggingface.
2024-05-03 🤗 We release 3.7M image editing data SEED-Data-Edit, which includes (1) Large-scale high-quality editing data produced by an automatic pipeline, (2) Real-world scenario data scraped from the internet that more accurately reflects user image editing intentions, (3) High-precision multi-turn editing data annotated by Photoshop experts.
2024-05-02 🤗 We release the training code for instruction tuning from the pre-trained foundation model SEED-X. Our codebase supports (a) large-scale multi-node training with deepspeed zero-2 and zero-3, (b) highly-efficient multiple training datapipes. To the best of our knowledge, our SEED series is the first open-source work on training MLLM that unifies multimodal comprehension and generation.
2024-04-27 🤗 We release the models including the pre-trained foundation model SEED-X, the general instruction-tuned model SEED-X-I, the editing model SEED-X-Edit, and our de-tokenier, which can generate realistic images from ViT features (w/o or w/ a condition image).
2024-04-22 🤗 We release an online gradio demo of a general instruction-tuned model SEED-X-I. SEED-X-I can follow multimodal instruction (including images with dynamic resolutions) and make responses with images, texts and bounding boxes in multi-turn conversation. SEED-X-I does not support image manipulation. If you want to experience SEED-X-Edit for high-precision image editing, the inference code and model will be released soon.
- Release the multimodal foundation model SEED-X.
- Release the instruction-tuned model SEED-X-Edit for high-precision image editing.
- Release 3.7M in-house image editing data.
- Release trainig code for instruction tuning.

 The introduced SEED-X, a unified and versatile foundation model, can serve as various multimodal AI assistants in the real world after different instruction tuning, capable of responding to a variety of user needs through unifying
multi-granularity comprehension and generation. Our instruction tuned models can
function as an interactive designer, generating images without descriptive captions while illustrating
creative intent, and showcasing visualizations of modified images based on user’s intent. They can act
as knowledgeable personal assistants, comprehending images of arbitrary sizes and offering relevant
suggestions in multi-turn conversations.
The introduced SEED-X, a unified and versatile foundation model, can serve as various multimodal AI assistants in the real world after different instruction tuning, capable of responding to a variety of user needs through unifying
multi-granularity comprehension and generation. Our instruction tuned models can
function as an interactive designer, generating images without descriptive captions while illustrating
creative intent, and showcasing visualizations of modified images based on user’s intent. They can act
as knowledgeable personal assistants, comprehending images of arbitrary sizes and offering relevant
suggestions in multi-turn conversations.
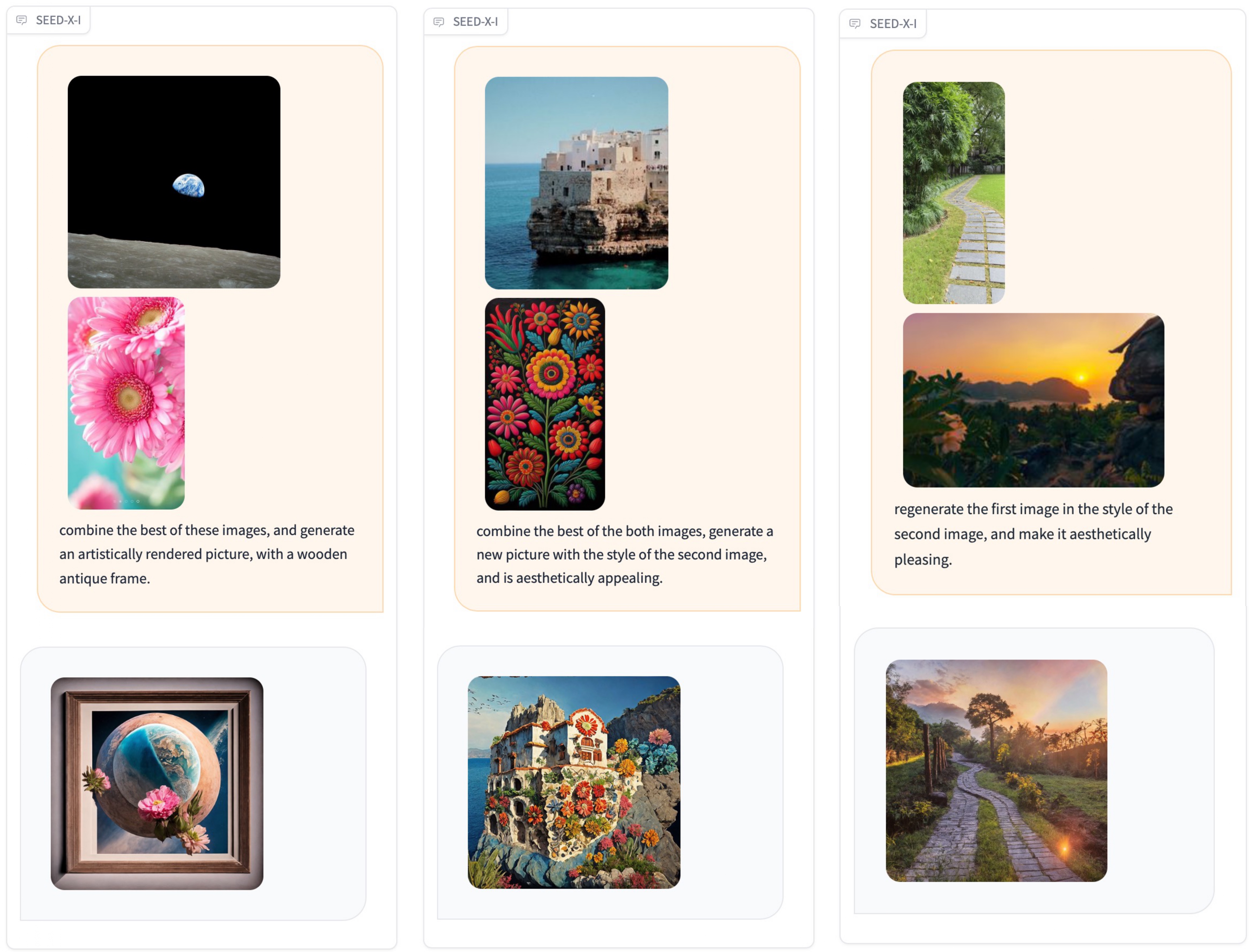 SEED-X is able to take multiple images as input, and follow its aesthetic vision and transform mediocre (or even low-resolution and low-quality) photos into something more impressive (In the example above, some of the input images have a resolution lower than 200). Feel free to try it by yourself in demo (Set "Force Image Generation" as True).
SEED-X is able to take multiple images as input, and follow its aesthetic vision and transform mediocre (or even low-resolution and low-quality) photos into something more impressive (In the example above, some of the input images have a resolution lower than 200). Feel free to try it by yourself in demo (Set "Force Image Generation" as True).
 Data examples of instruction-guided image editing in SEED-Data-Edit, which includes (1)
High-quality editing data produced by an automatic pipeline (first row), (2) Real-world scenario
data scraped from the internet that more accurately reflects user image editing intentions (second
row), (3) High-precision multi-turn editing data annotated by Photoshop experts (third row).
Data examples of instruction-guided image editing in SEED-Data-Edit, which includes (1)
High-quality editing data produced by an automatic pipeline (first row), (2) Real-world scenario
data scraped from the internet that more accurately reflects user image editing intentions (second
row), (3) High-precision multi-turn editing data annotated by Photoshop experts (third row).
The introduced SEED-Story, powered by SEED-X, is capable of generating multimodal long stories from user-provided images and texts as the beginning of the story. The generated story consists of rich and coherent narrative texts, along with images that are consistent in characters and style. The story can span up to 25 multimodal sequences, even though we only use a maximum of 10 sequences during training.

- Python >= 3.8 (Recommend to use Anaconda)
- PyTorch >=2.0.1
- NVIDIA GPU + CUDA
Clone the repo and install dependent packages
git clone https://github.com/AILab-CVC/SEED-X.git
cd SEED-X
pip install -r requirements.txtWe release the pretrained De-Tokenizer, the pre-trained foundation model SEED-X, the general instruction-tuned model SEED-X-I, the editing model SEED-X-Edit in in SEED-X-17B Hugging Face.
You can also download them separately as below,
- Check the SEED-X de-tokenizer weights in AILab-CVC/seed-x-17b-de-tokenizer
- Check the pre-trained foundation model SEED-X weights in AILab-CVC/seed-x-17b-pretrain
- Check the general instruction-tuned model SEED-X-I weights in AILab-CVC/seed-x-17b-instruct
- Check the editing model SEED-X-Edit weights in AILab-CVC/seed-x-17b-edit
Please download the checkpoints and save them under the folder ./pretrained. For example, ./pretrained/seed_x.
You also need to download stable-diffusion-xl-base-1.0 and Qwen-VL-Chat, and save them under the folder ./pretrained. Please use the following script to extract the weights of visual encoder in Qwen-VL-Chat.
python3 src/tools/reload_qwen_vit.py# For image reconstruction with ViT image features
python3 src/inference/eval_seed_x_detokenizer.py
# For image reconstruction with ViT image features and conditional image
python3 src/inference/eval_seed_x_detokenizer_with_condition.py# For image comprehension and detection
python3 src/inference/eval_img2text_seed_x.py
# For image generation
python3 src/inference/eval_text2img_seed_x.py# For image comprehension and detection
python3 src/inference/eval_img2text_seed_x_i.py
# For image generation
python3 src/inference/eval_text2img_seed_x_i.py# For image editing
python3 src/inference/eval_img2edit_seed_x_edit.py- Prepare the pretrained models including the pre-trained foundation model SEED-X and the visual encoder of Qwen-VL-Chat (See Model Weights).
- Prepare the instruction tuning data. For example, for "build_llava_jsonl_datapipes" dataloader, each folder stores a number of jsonl files, each jsonl file contains 10K pieces of content, with an example of the content as follows:
{"image": "coco/train2017/000000033471.jpg", "data": ["What are the colors of the bus in the image?", "The bus in the image is white and red.", "What feature can be seen on the back of the bus?", "The back of the bus features an advertisement.", "Is the bus driving down the street or pulled off to the side?", "The bus is driving down the street, which is crowded with people and other vehicles."]}For "build_caption_datapipes_with_pixels" dataloder, each folder stores a number of .tar files and reads image-text pairs in the form of webdataset.
For "build_single_turn_edit_datapipes" dataloder, each folder stores a number of jsonl files, each jsonl file contains 10K pieces of content, with an example of the content as follows:
{"source_image": "source_images/f6f4d0669694df5b.jpg", "target_image": "target_images/f6f4d0669694df5b.jpg", "instruction": "Erase the car that is parked in front of the Roebuck building."}- Run the following script.
# For general instruction tuning for multimodal comprehension and generation
sh scripts/train_seed_x_sft_comp_gen.sh# For training language-guided image editing
sh scripts/train_seed_x_sft_edit.sh- Obtain "pytorch_model.bin" with the following script.
cd train_output/seed_x_sft_comp_gen/checkpoint-xxxx
python3 zero_to_fp32.py . pytorch_model.bin- Change "pretrained_model_path" in "configs/clm_models/agent_seed_x.yaml" with the new checkpoint. For example,
pretrained_model_path: train_output/seed_x_sft_comp_gen/checkpoint-4000/pytorch_model.bin- Change the "llm_cfg_path" and "agent_cfg_path" in the inference script (See below), which will automatically load the trained LoRA weights onto the pretrained model SEED-X.
llm_cfg_path = 'configs/clm_models/llm_seed_x_lora.yaml'
agent_cfg_path = 'configs/clm_models/agent_seed_x.yaml'- Run the inference script,
# For image comprehension
python3 src/inference/eval_img2text_seed_x_i.py
# For image generation
python3 src/inference/eval_text2img_seed_x_i.py
# For image editing
python3 src/inference/eval_img2edit_seed_x_edit.pyIf you find the work helpful, please consider citing:
@article{ge2024seed,
title={SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation},
author={Ge, Yuying and Zhao, Sijie and Zhu, Jinguo and Ge, Yixiao and Yi, Kun and Song, Lin and Li, Chen and Ding, Xiaohan and Shan, Ying},
journal={arXiv preprint arXiv:2404.14396},
year={2024}
}SEED is licensed under the Apache License Version 2.0 except for the third-party components listed in License.
During training SEED-X, we freeze the original parameters of LLaMA2 and optimize the LoRA module.