Partly automate the training procedure of a Neural Network for image classification.
The script can be easily changed/extended by customizing the basic functions before main.
Currently, it works for all the available datasets of tensorflow_datasets. In order to add support for a dataset which is available in the afformentioned package, its name has to be added in DATASET_CHOICES, in helpers/parser.py.
Alternatively, the load_data function can be changed in order to load custom datasets.
It is also recommended to alter the preprocess_data function.
Please note that the complicated ensembles models work only for a specific number of classes
and need to be changed for different numbers of classes, thus they depend on the dataset being used.
Refer to the comments of their submodels labels manipulation functions,
in order to see/change the classes for which they work.
- Built with Python 3.8 and Tensorflow 2.2.
- Implements the USTE(Unified Specialized Teachers Ensemble) method, which is useful for transferring the knowledge more efficiently to a smaller network. For more information, see: Knowledge Transfer.
- My diploma thesis: Lightweight Deep Learning For Embedded Intelligence
- PRLetters Journal Publcation: Improving knowledge distillation using unified ensembles of specialized teachers
usage: train_network.py [-h]
[-db {cifar10,cifar100,svhn_cropped,fashion_mnist,mnist}]
[-n {cifar100_complicated_ensemble_submodel2,cifar10_strong_ensemble,...}]
[-nx NEW_X] [-ny NEW_Y] [-sp START_POINT] [-ow] [-om]
[-oc] [-oh] [-op] [-oe] [-out OUT_FOLDER]
[-o {adam,rmsprop,sgd,adagrad,adadelta,adamax}] [-na]
[-lr LEARNING_RATE] [-lrp LEARNING_RATE_PATIENCE]
[-lrd LEARNING_RATE_DECAY] [-lrm LEARNING_RATE_MIN]
[-esp EARLY_STOPPING_PATIENCE] [-cn CLIP_NORM]
[-cv CLIP_VALUE] [-b1 BETA1] [-b2 BETA2] [-rho RHO]
[-m MOMENTUM] [-d DECAY] [-bs BATCH_SIZE]
[-ebs EVALUATION_BATCH_SIZE] [-e EPOCHS]
[-v VERBOSITY] [-seed SEED]
Training a CNN network.
optional arguments:
-h, --help show this help message and exit
-db {cifar10,cifar100,svhn_cropped,fashion_mnist,mnist},
--dataset {cifar10,cifar100,svhn_cropped,fashion_mnist,mnist}
The dataset to be used (default cifar10).
-n {cifar100_complicated_ensemble_submodel2,cifar10_strong_ensemble,...},
--network {cifar100_complicated_ensemble_submodel2,cifar10_strong_ensemble,...}
The network model to be used (default cifar10_model1).
-nx NEW_X, --new_x NEW_X
The new width for the images. If you do not want to
resize them, set new_x or new_y to 0 (default 0).
-ny NEW_Y, --new_y NEW_Y
The new height for the images.If you do not want to
resize them, set new_x or new_y to 0 (default 0).
-sp START_POINT, --start_point START_POINT
Filepath containing existing weights to initialize the
model.
-ow, --omit_weights Whether the weights should not be saved (default
False).
-om, --omit_model Whether the model should not be saved (default False).
-oc, --omit_checkpoint
Whether the best weights checkpoint should not be
saved (default False).
-oh, --omit_history Whether the training history should not be saved
(default False).
-op, --omit_plots Whether the training plots should not be saved
(default False).
-oe, --omit_evaluation
Whether the evaluation results should not be saved
(default False).
-out OUT_FOLDER, --out_folder OUT_FOLDER
Path to the folder where the outputs will be stored
(default out).
-o {adam,rmsprop,sgd,adagrad,adadelta,adamax}, --optimizer {adam,rmsprop,sgd,adagrad,adadelta,adamax}
The optimizer to be used. (default rmsprop).
-na, --no_augmentation
Whether the data should not be augmented. Augmentation
is suggested only for image data. (default False).
-lr LEARNING_RATE, --learning_rate LEARNING_RATE
The learning rate for the optimizer (default 0.001).
-lrp LEARNING_RATE_PATIENCE, --learning_rate_patience LEARNING_RATE_PATIENCE
The number of epochs to wait before decaying the
learning rate (default 8).
-lrd LEARNING_RATE_DECAY, --learning_rate_decay LEARNING_RATE_DECAY
The learning rate decay factor. If 0 is given, then
the learning rate will remain the same during the
training process. (default 0.1).
-lrm LEARNING_RATE_MIN, --learning_rate_min LEARNING_RATE_MIN
The minimum learning rate which can be reached
(default 1e-08).
-esp EARLY_STOPPING_PATIENCE, --early_stopping_patience EARLY_STOPPING_PATIENCE
The number of epochs to wait before early stoppingIf 0
is given, early stopping will not be applied. (default
15).
-cn CLIP_NORM, --clip_norm CLIP_NORM
The clip norm for the optimizer (default None).
-cv CLIP_VALUE, --clip_value CLIP_VALUE
The clip value for the optimizer (default None).
-b1 BETA1, --beta1 BETA1
The beta 1 for the optimizer (default 0.9).
-b2 BETA2, --beta2 BETA2
The beta 2 for the optimizer (default 0.999).
-rho RHO The rho for the optimizer (default 0.9).
-m MOMENTUM, --momentum MOMENTUM
The momentum for the optimizer (default 0.8).
-d DECAY, --decay DECAY
The decay for the optimizer (default 1e-06).
-bs BATCH_SIZE, --batch_size BATCH_SIZE
The batch size for the optimization (default 64).
-ebs EVALUATION_BATCH_SIZE, --evaluation_batch_size EVALUATION_BATCH_SIZE
The batch size for the evaluation (default 128).
-e EPOCHS, --epochs EPOCHS
The number of epochs to train the network (default
125).
-v VERBOSITY, --verbosity VERBOSITY
The verbosity for the optimization procedure (default
1).
-seed SEED, --seed SEED
The seed for all the random operations. Pass a
negative number, in order to have non-deterministic
behavior (default 0).
Note: The hyperparameters will be ignored if the chosen optimizer does not use
them. Little hack to just save a model from existing checkpoint: $python
train_network.py -sp checkpoint.h5 -e 0
train_network.py dataset cifar100 --network cifar100_baseline_ensemble_submodel2 --optimizer adam --epochs 150 --batch_size 64 --learning_rate 1e-4 --learning_rate_min 5e-6 --learning_rate_decay 0.4 --out_folder './NN-Train-Test/out/cifar100/baseline/model2'
The log contains the final values for all the metrics which have been chosen to be monitored.
These can be easily updated in the model.compile() method inside main.
Also, the init_callbacks() should be changed in order to monitor the desired metrics for the checkpoint, early stopping and learning rate decay.
loss: 2.3911
categorical_accuracy: 0.6344
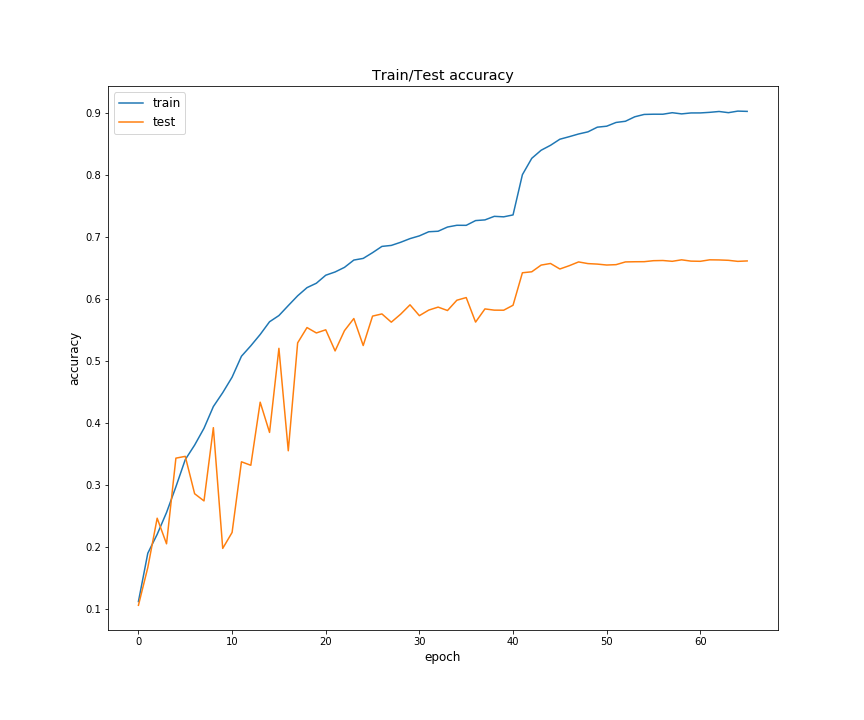
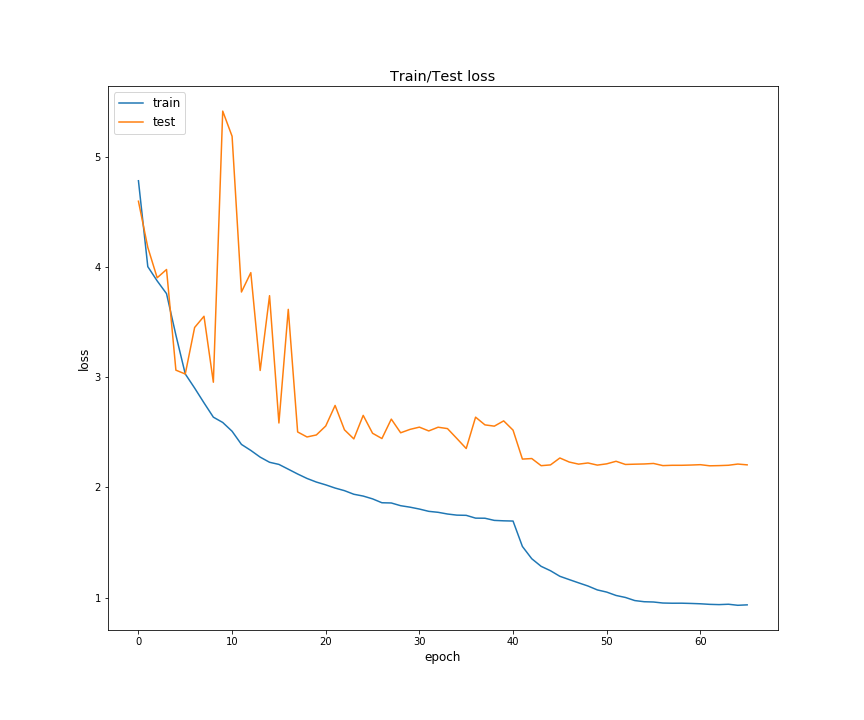

Some useful files (unless otherwise specified) are saved in the chosen out folder destination. These include:
- the final model's weights
- the model (in
kerasformat) - the best model's weights
- the training history