Introduction to GKMX
GKMX stands for General Kernel Matrix Operations, which currently contain two templates GKMM (Matrix Matrix) and GKRM (Reduce Matrix). In brief, GKMM is a matrix matrix multiplication (C=A*B), but matrices A, B and C can have different types. If you are familiar with GEMM in the BLAS library (Basic Linear Algebra Subprograms), then you can now interpret GEMM as a special case of GKMM where all the types are the same (float, double, complex). However, when types of A, B and C are different, multiplication (x) and addition (+) may have no definition on these types. To make this work, an instance of GKMM must come with some appropriate transformations that satisfy the type system. We describe more features of GKMM and GKRM in details.
GKMM< OPKERNEL, OP1, OP2, TA, TB, TC, TV > computes the following:
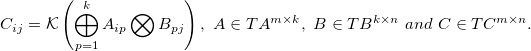
Here K has type OPKERNEL, bigoplus has type OP1, and bigotimes has type OP2. These operations satisfy
< TV > = OP1( < TV > OP2( < TA >, < TB > ) ), and
< TC > = OPKERNEL( < TV > ).
For example to implement a batched matrix matrix multiplication in double precision on x86_64 and Intel Xeon Phi, then we can create an instance gkmm called gkmm_dfma. Ignore those number in the template first. Those numbers are block sizes to optimization. We define OP1 and OP2 with STL. Notice that we did not use std::identity but define our own identity operator to accept extra arguments.
using namespace hmlp::gkmx;
template<typename TC, typename TV>
struct identity
{
inline TC operator()( const TV& x, int i, int j, int b ) const
{ return x; }
};
void gkmm_dfma
(
hmlpOperation_t transA, hmlpOperation_t transB,
int m, int n, int k,
double *A, int lda,
double *B, int ldb,
double *C, int ldc,
int batchSize
)
{
std::plus<double> op1;
std::multiplies<double> op2;
identity<double, double> opkernel;
double initV = 0.0;
gkmm
<104, 4096, 256, 8, 4, 104, 4096, 8, 4, 32,
false,
identity<double, double>, std::plus<double>, std::multiplies<double>,
double, double, double, double>
(
transA, transB,
m, n, k,
A, lda,
B, ldb,
C, ldc,
batchSize,
opkernel, op1, op2, initV
);
}See SEMIRINGKERNEL and FUSEDKERNEL for the prototype of architecture dependent kernels of GKMM.
GKRM< OPKERNEL, OP1, OP2, OPREDUCE, TA, TB, TC, TV > computes the following:
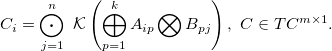
The new reduce operator (bigodot) has type OPREDUCE.
See SEMIRINGKERNEL and FUSEDKERNEL for the prototype of architecture dependent kernels of GKRM.
The goal of GKMX is to enable high performance computing on all matrix matrix multiplication like operations on most of the popular architectures. For x86_64 and Intel Xeon Phi architectures, GKMX implements the Goto algorithm [] in the BLIS framework [].