Existing apps require you to frame the cube in a grid and take a photo per side, with specific orientation requirements to detect the state. This project aims to detect the cube state through a video stream, with the user rotating the cube in front of a camera.
This project initially started as a CalHacks project where we built a SwiftUI app with C++ OpenCV (for Swift interoperability). The cube detection was done through pure classical CV (see project here), with CV techniques including masking & thresholding, contour maps, connected components, Canny edge detection and RDP polygonal approximation. Results can be seen here:
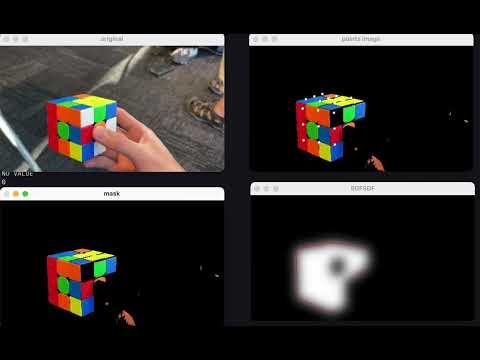
We use DINO + LangSAM (bbox output from DINO to LangSAM for segmentation) to produce a segmented cube (1-cube-segmentation), and pass this into a classical CV pipeline to detect the pieces (2-piece-detection), where the final state is extracted (3-state-mapping).

We obtained reasonable results on most cube inputs, with the exception of some hand placements obscuring corners, causing line detection to fail.
An immediate next goal is to train an end-to-end model, bypassing the classical CV steps.
This was our Machine Learning @ Berkeley's NMEP Project in Fall 2023.