This reposity holds the code for the paper Enhancing the Performance of Automated Grade Prediction in MOOC using Graph Representation Learning (arXiv version)
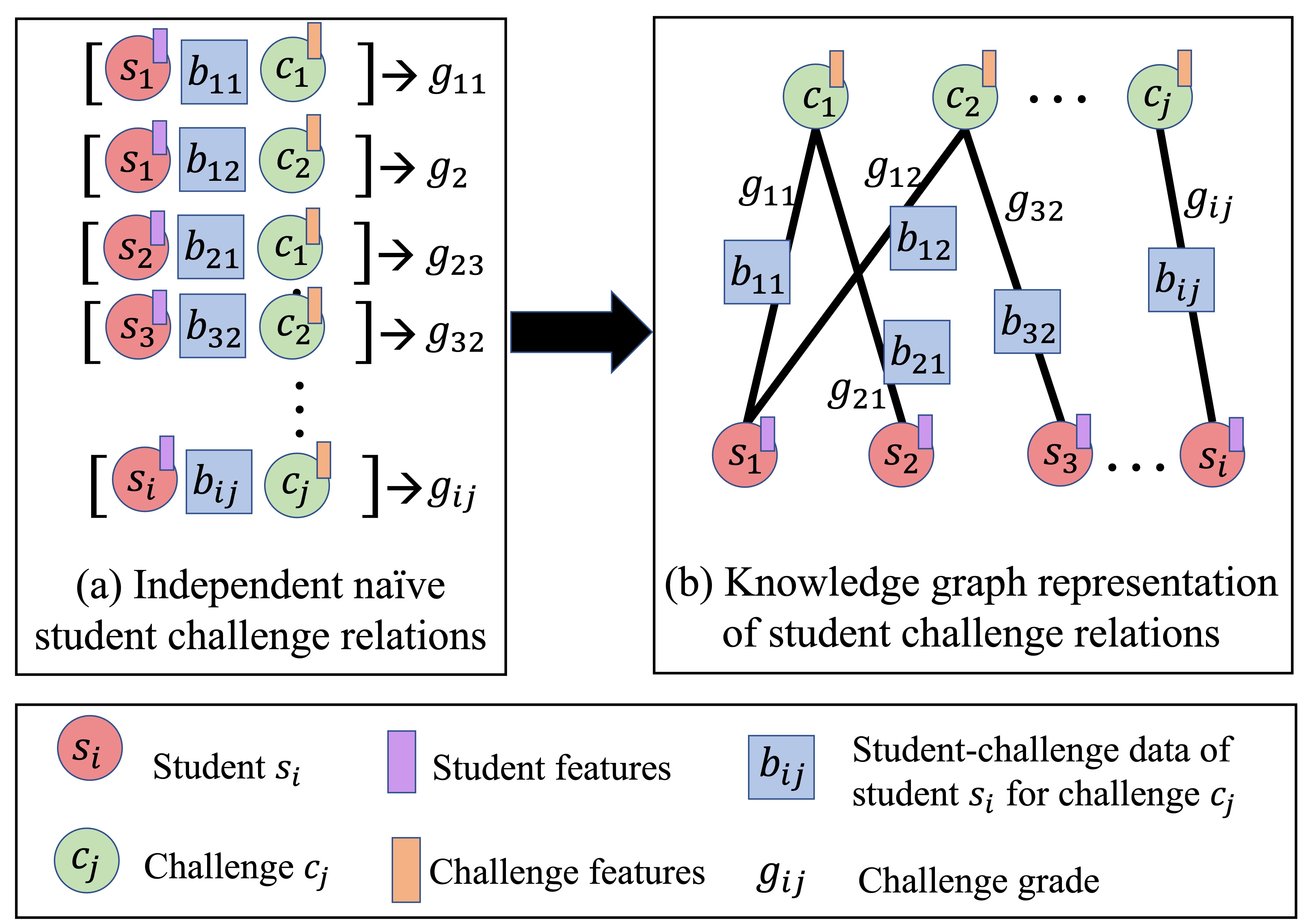
Visualizing the traditional approach used in prior prediction models compared to our graph representation
dataset is saved under data/ folder in a file named
grade_prediction_mooc.csv

Entities and their relations in the MOOPer dataset
The dataset has the following format:
- One line per student-challenge interaction/edge.
- Each line includes: user_id, challenge_id, timestamp, course_id, exercise_id, difficulty, retry_status, duration, final_score.
- The first line is the network format.
- final_score is 0, 1, 2, 3 or 4.
The first few lines of the dataset can be:
user_id,challenge_id,timestamp,course_id,exercise_id,difficulty,retry_status,duration,final_score
0,1,0,0,6,3,0,155,3
0,2,1,0,6,2,0,200,3
0,3,2,0,6,1,0,457,2
0,4,3,0,6,1,0,40000,4
0,5,4,0,6,1,0,9655,2
You can install all the required packages using the following command:
$ pip install -r requirements.txt
To enhance the dataset using graph structural information, run the code in the file create_graph_enhanced_dataset.py. This code computes node properties like degree and centrality for each node in the graph as well as node embeddings using two popular node embedding algorithms, namely DeepWalk and node2vec algorithms. Finally, two enhanced datasets are created and saved under data/ folder.
mooc_with_deepwalk_embedding.csv contains the dataset enhanced with graph basic properties as well as DeepWalk embeddings.
mooc_with_node2vec_embedding.csv contains the dataset enhanced with graph basic properties as well as node2vec embeddings.
The embeddings are also saved separately under the data/ folder.
To predict the grade, three traditional machine learning models are used:
- Random Forest Classifier,
- Gradient Boosting Classifier,
- XGBoost
Run the file named train.py to apply these 3 models on 3 different dataset settings: original dataset, original dataset + node2vec embeddings, original dataset + DeepWalk embeddings. This saves the models under models/ folder.
Comparing the performance of 9 models on grade prediction task. The best algorithm in each column is displayed in bold

Detailed classification results for different Gradient Boosting variations

Run the file named additional_analysis.py to plot the confusion matrices and feature importances for the Gradient Boosting method on different datasets. Also, to showcase the strength of the algorithm in predicting grades for low-performing/struggling students, we compare Gradient Boosting's performance in predicting grades for different categories of students on different datasets.
If you use the code or data, please cite the following paper:
@INPROCEEDINGS{Farokhi2023Mooper, author={Farokhi, Soheila and Yaramal, Aswani and Huang, Jiangtao and Khan, Muhammad Fawad Akbar and Qi, Xiaojun and Karimi, Hamid}, booktitle={2023 IEEE 10th International Conference on Data Science and Advanced Analytics (DSAA)}, title={Enhancing the Performance of Automated Grade Prediction in MOOC using Graph Representation Learning}, year={2023}, volume={}, number={}, pages={1-10}, doi={10.1109/DSAA60987.2023.10302642}}