Modify Threading Scheme to Improve Performance with Large Numbers of Threads #70
Conversation
…nto peter/contention
|
Sped up the read from the grid of rtrees which brought the runtime down a little: But most importantly it now runs a lot faster cpus with fewer threads which helps address one thing I was worried about with this approach. |
| // the stucture of this tuple is (chunk_x, chunk_y, is_center_chunk, closest_x_point, closest_y_point) | ||
| let places_to_look = vec![ | ||
| (chunk_x, chunk_y, true, 0, 0), | ||
| (chunk_x + 1, chunk_y, false, (chunk_x + 1) * self.chunk_size as i32, y as i32), | ||
| (chunk_x - 1, chunk_y, false, chunk_x * self.chunk_size as i32, y as i32), | ||
| (chunk_x, chunk_y - 1, false, x as i32, chunk_y * self.chunk_size as i32), | ||
| (chunk_x, chunk_y + 1, false, x as i32, (chunk_y + 1) * self.chunk_size as i32), | ||
| (chunk_x + 1, chunk_y + 1, false, (chunk_x + 1) * self.chunk_size as i32, (chunk_y + 1) * self.chunk_size as i32), | ||
| (chunk_x - 1, chunk_y + 1, false, chunk_x * self.chunk_size as i32, (chunk_y + 1) * self.chunk_size as i32), | ||
| (chunk_x + 1, chunk_y - 1, false, (chunk_x + 1) * self.chunk_size as i32, chunk_y * self.chunk_size as i32), | ||
| (chunk_x - 1, chunk_y - 1, false, chunk_x * self.chunk_size as i32, chunk_y * self.chunk_size as i32), | ||
| ]; |
There was a problem hiding this comment.
I would really prefer this to be a struct defined inside the the function, tuples are fine for prototyping but end up being really tedious to use over the long term, especially > 2 length.
There was a problem hiding this comment.
Thanks for the pointer! This code is still pretty prototype-y so I will make a cleanup pass later and can definitely change this.
There was a problem hiding this comment.
I changed these tuples to an in-function struct in my most recent commit
|
That's an impressive speed up! I'll have a look :) |
|
Oh and FYI, if you are doing your iterative benchmarking via the cli you might want to check out hyperfine. |
|
Had a little time so I did some code clean up. Inpaint is now reenabled, tiling is still broken but should be a simple fix. Also @h3r2tic wanted to see if you ever got a chance to benchmark these changes on your hardware yet (no worries if not, I don't want to get in the way of your actual work) |
|
Fixed in painting. This pr is not mergable yet because it does not work for rectangular images and needs a simple heuristic to choose grid size but I will be able to get to those soon |
| ([coord_2d.x as i32, coord_2d.y as i32], a.0, a.1) | ||
| }) | ||
| .collect(); | ||
| self.flush_resolved( |
There was a problem hiding this comment.
Note this changes behavior when both inpainting and tiling are enabled. Now pixels which are not part of the inpaint region will be taken into account when tiling. I could change this back to the old behavior (where those pixels were ignored) by imho this behavior seems better
There was a problem hiding this comment.
Perhaps @anopara could have a look. I'm not quite sure what the implications are with the previous and the new behaviors.
There was a problem hiding this comment.
Hi, @Mr4k. First of all, this is some awesome work, thank you! Could you please elaborate on "Now pixels which are not part of the inpaint region will be taken into account when tiling" 😅 I'm not quite sure how exactly they will be used during tiling?
There was a problem hiding this comment.
Hi @anopara. Thanks for making this awesome project! I apologize because looking back my comment is definitely vague but here is a concrete example. Consider the output of the following command.
cargo run --release -- --out-size 304x308 --inpaint circles_mask.png --tiling -o imgs/01.png generate circles.png
(Importantly this command has both inpainting and tiling enabled)
using the following images:
circles.png:

circles_mask.png:

On master this generates this following image:

On my branch this will generate this image:

What I mean is that in my image the inpaint takes into account the pixels on the other side of the image to make it tile. As far as I understand this is because in master when you add the static pixels which are not part of the inpaint region to the rtree (
) you do not "reflect" them across image borders like you do when you add pixels during synthesis ( ). What I've done is just to use the same function for both which provides mirroring (when tiling is enabled) as a side effect.There was a problem hiding this comment.
Ah! That is a very good observation and that is indeed correct. Thank you for spotting this case. We indeed only mirror newly generated pixels 😅 Your proposed change is definitely a more desirable behavior! 👍
|
This pr now works for rectangular images and chooses a grid size based on k, the image size and number of pixels filled. So functionality wise I think it's fairly complete. |
There was a problem hiding this comment.
Apologies for the delay! Several things aligned, and then holidays stalled me some more :P
The code looks good. Thank you so much for all the work you've put into it! I've done some quality comparisons (haven't benchmarked yet). It seems to be producing similar results to the master branch, and images were identical for single-threaded runs in the tests I ran. Awesome work! A grid of R*-trees was indeed a great idea to speed it up :)
I've added a few comments; most of them are nitpicks, thought would be nice to get those in for code clarity. There's one thing about the tree grid where your cell culling might be too aggressive, though I haven't been able to notice any artifacts due to that in practice.
| let tile_adjusted_width = (self.output_size.width as f32 * 1.1) as u32 + 1; | ||
| let tile_adjusted_height = (self.output_size.height as f32 * 1.1) as u32 + 1; | ||
| self.tree_grid = TreeGrid::new( | ||
| tile_adjusted_width, | ||
| tile_adjusted_height, | ||
| max(tile_adjusted_width, tile_adjusted_height), | ||
| (self.output_size.width as f32 * 0.05) as u32 + 1, | ||
| (self.output_size.height as f32 * 0.05) as u32 + 1, |
There was a problem hiding this comment.
What's the reasoning behind the 1.1 multiplier, and why is 1 added on top of it?
There was a problem hiding this comment.
This was just a low quality thing on my part. The 1.1 is because in tiling mode you have boundaries which are 5% of the image size. I will move that into a constant. You are also right about the +1 being for rounding up. I will follow your suggestion below.
| ([coord_2d.x as i32, coord_2d.y as i32], a.0, a.1) | ||
| }) | ||
| .collect(); | ||
| self.flush_resolved( |
There was a problem hiding this comment.
Perhaps @anopara could have a look. I'm not quite sure what the implications are with the previous and the new behaviors.
| @@ -761,6 +702,35 @@ impl Generator { | |||
| let l2_precomputed = PrerenderedU8Function::new(metric_l2); | |||
| let mut total_processed_pixels = 0; | |||
| let max_workers = params.max_thread_count; | |||
| let mut has_fanned_out = false; | |||
There was a problem hiding this comment.
Can you add a comment to clarify the "fanned out"? Perhaps something along the lines of "use a single R*-tree initially, and fan out to a grid thereof later".
| @@ -817,6 +813,10 @@ impl Generator { | |||
| let max_candidate_count = params.nearest_neighbors as usize | |||
| + params.random_sample_locations as usize; | |||
|
|
|||
| let my_thread_num = thread_counter.fetch_add(1, Ordering::Relaxed); | |||
There was a problem hiding this comment.
Nitpick: should be my_thread_id for consistency with other ordinals.
| // Some items might still be pending a resolve flush. Do it now before we start the next stage. | ||
| self.force_flush_resolved(is_tiling_mode); | ||
| { | ||
| // append all resolved threads to resolved |
There was a problem hiding this comment.
Sounds like we're appending threads. Would rephrase to "append all per-thread resolved lists to the global list"
There was a problem hiding this comment.
haha true I'll rewrite that
| result.reserve(k); | ||
|
|
||
| // this isn't really the kth best distance but should be good enough for how simple it is | ||
| let mut kth_best_squared_distance = i32::max_value(); |
There was a problem hiding this comment.
Using i32 here starts feeling a bit tight -- some people use giant images, and there's a chance of this overflowing, particularly in the first stage of processing before "fanning out" to a larger grid of trees.
There was a problem hiding this comment.
oh wow never considered an image of that size. I'll bump to i64
| // a tiny optimization to help us throw far away neighbors | ||
| // saves us a decent amount of reads | ||
| if !is_center { | ||
| let squared_distance_to_closest_possible_point_on_chunk = (x as i32 |
There was a problem hiding this comment.
Ditto, a bunch of potentially dangerous i32 here.
| // a tiny optimization to help us throw far away neighbors | ||
| // saves us a decent amount of reads |
There was a problem hiding this comment.
Is this actually correct though? This seems to be just point-to-point distance against closest_point_on_boundary_. The latter seem to be centered on edges of cells, but are not guaranteed to be the closest point inside the cell.
There was a problem hiding this comment.
Sorry the name there might be a little confusing what I mean by closet point in cell is closest point on boundary. The optimization works as follows:
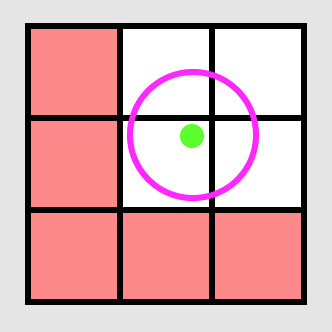
If the green dot is the pixel we are talking about (which is always in the middle cell) and we know that the k nearest neighbors so far are all within the purple circle then we don't have to search any of the red cells because their closest possible points (the boundary points) to our pixel are further than any of our candidate k closest neighbors. Also we cannot use this to filter out the middle cell (which we are inside of)
There was a problem hiding this comment.
Could you not end up in the following situation?
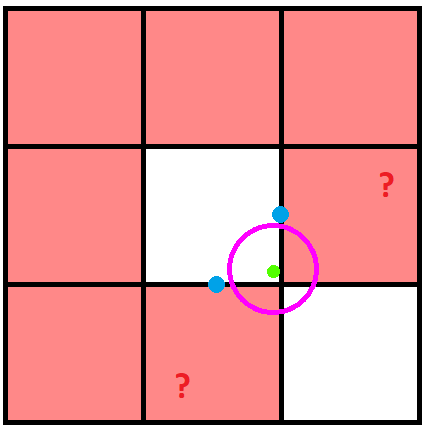
I have highlighted in blue what I'm assuming to be the boundary points of the missed cells.
There was a problem hiding this comment.
Thanks for the picture! I think the position of the blue points is incorrect. They should really be the closest point on each boundary to the current pixel. For the 4 corner cells this point is always a constant (the closest corner on that cell to the center of the grid) no matter which pixel we are addressing in the middle. However for the cells you highlighted as problematic the boundary points I compute are actually based on the green pixels x or y coordinates (in the case of your picture one would be directly below the green dot and the other would be directly to the right). In this case we would not rule out those cells because both of the points are within the purple circle.
There was a problem hiding this comment.
Here's a revised version of your picture (also added the bottom right corner's closest point to the diagram)

There was a problem hiding this comment.
Aha, so I did misread the code, thinking you were offsetting from the center. Make sense now, thanks!
|
|
||
| // Assume that all k nearest neighbors are in these cells | ||
| // it looks like we are rarely wrong once enough pixels are filled in | ||
| let places_to_look = vec![ |
There was a problem hiding this comment.
Looks like we can avoid a heap allocation by just removing the vec! characters :)
| }), | ||
| ); | ||
|
|
||
| // this isn't really the kth best distance but it's an okay approximation |
There was a problem hiding this comment.
I think a good deal of "this isn't really X" could be avoided by just calling the variable differently. How about something like kth_nearest_distance_upper_bound?
|
Thanks so much for reviewing (and for catching so many things)! I'll make the changes soon and generally try to make the naming better! And of course if you get a chance I'd love to know runtimes on more reference rigs but no pressure if you're busy. |
|
Tested on my Threadripper! Pretty consistent with the "Google Cloud 64 core cpu". |
|
Impressive improvement! |
|
Good to hear! Also thanks @repi! Just for completeness's sake here are some things I thought of that I decided were out of scope of this pr but thought might be worth mentioning:
Finally thanks so much @h3r2tic @anopara @Jake-Shadle for taking the time to benchmark / review my code! It was really fun to work on this. |
|
Good thoughts! Like you say, the initial serial part of the algorithm will certainly suffer from Amdahl's law. I suspect it can be parallelized to some extent; I can imagine schemes where one would pre-generate* the locations of points to be resolved, and then partition them between threads based on spatial proximity -- perhaps with sync points at specific locations of the point list. Quite unclear how much performance we could win though, as we're likely in the area of diminishing returns there. The R* tree was more of a "what can we plug in in a short amount of time that more or less matches the requirements" rather than a particularly conscious choice. We tried kD-trees before, and they weren't that great due to high branching factors, resulting in pointer chasing and branching in execution. Perhaps there's something better out there :) * Pre-generating the order of pixel locations for synthesis could enable us to use a high quality low-discrepancy sequence instead of just random, possibly improving the quality of generated images. |
|
Oh interesting point about the pre generated sequences. I had thought about doing something like that but I was worried that it would change the distribution. However it sounds like a different distribution could potentially allow for higher quality (or at least more predictable) synthesis if chosen carefully. |
Checklist
Description of Changes
Disclaimer: This pr is a big proposed change and is not fully ready yet (inpaint and tiling are currently disabled but should be easily fixable). The code isn't the cleanest (feel free to let me know if it's too hard to read) and could be optimized further but I wanted to put it up as a proof of concept see what you think, make sure my big assumptions about how the code works were not very wrong, and see how this runs on other people's machines before I go further.
Motivation:
After seeing that @h3r2tic had virtually no improvements from my previous pr on their 32 core cpu I rented a larger cloud machine (64 logical cores, Intel Xeon) to test out how my previous changes behaved with many cores. It turns out I didn't see any improvement either. I then tried with lower numbers of threads (48, 32, 24, 16, 8, etc) and noticed that the run time actually seemed to improve as I decreased the number of threads (after some fiddling I found 22 threads was the best number for my instance) and barely went up until < 16 threads were in use. I figured this was a contention problem, so I added some additional logging to measure the time it took to acquire various locks and found (at least on that machine) the time it took to acquire a write lock on the rtree went up proportionally with the number of threads. Also as a side effect I believe it dwarfed any improvement from my previous change to the point where it was barely noticeable.
Proposed Improvements:
I've made several changes which I have seen reduce contention on my test machines.
Replace the RTree with a grid of Rtrees
Advantages:
Most of the time (at least in the later stages of synthesis) two threads may be working on totally different areas of the image and will not need to access the same sets of pixels and therefore should not have to wait to read / write. To address this after the first few stages of synthesis I replace the single rtree with a grid of rtrees. Writes only lock the rtree in the grid cell which the pixel is in and reads just read from a cell and its neighbors. Overall this has seemed to improve contention considerably in my tests. (Possibly a multi threaded rtree is better than this but I couldn't find one and it seemed more difficult / error prone to build for likely little upside)
Drawbacks:
The actual read itself is a little slower, this is balanced out by the fact that far more threads can read and write at the same time but it should be optimized a little more for machines with fewer cores
Technically we can miss some neighbors if a pixels k nearest neighbors are outside of the current cell + 8 adjacent cells, however because we only use a grid after the first few steps there should be enough pixels where this is never a problem. I have not seen quality degrade (see below)
Places for improvement:
The read can definitely be optimized more (especially important for cpus with small numbers of cores)
The number of grid cells is currently just a random constant but really should vary with the number of threads / size of the image / k
Don’t write to resolved queue until after stage is complete (don't updated it when a pixel is placed)
After I switched to the rtree grid I noticed that although writes were really fast the resolved queue seemed to be suddenly very hard to acquire a lock on. After looking at the code more I decided that each thread could have its own resolved queue and I could combine them at the end of the stage. I don't think this actually changes the behavior of the code because the only time we read from the resolved queue is to redo pixels done in the previous stages so we don't care what pixels other threads have updated in the current stage.
Advantages:
The resolved queue is no longer backed up leading to a speed up
Disadvantages:
None that I see
Remove the Update Queue entirely
I removed the update queue to simplify things a little because the writes were now fast enough where I could write every time instead of needing to batch.
Advantages:
Code is simpler, very small speed up
Disadvantages:
I can't think of too much but possibly this could be bad not to have in the first few stages before we switch to the grid of rtrees
Could also be worse for smaller grid sizes
Results:
I’ve tested on only two large machines so far:
Google Cloud N1:
Threads: 64
Cpu: Intel(R) Xeon(R) CPU @ 2.30GHz:
AWS Z1d:
Threads: 48
Cpu: Intel® Xeon® Scalable (Clock speed is a little unclear but Amazon claims up to 4ghz)
I’m also curious to see what others get on cpus with large numbers of cores. @h3r2tic especially want to know how this runs on your 32 core cpu if you have the time.
Image Quality:
Because this change affects the threads and is fairly major I wanted to make sure that image quality did not change. It looks like tests still pass for everything that I didn’t break so the image hashes must be fairly close. I also manually inspected some large images but did not see any major changes. However it is important that the threads share one rtree for the first few stages before there are enough pixels to fill out a decent portion of the grid cells.
Related Issues
I don’t believe this is related to any mentioned issue