How to connect to several HDFS file systems from one SPL application
With the new version of streamsx.hdfs toolkit (version 4.1.1 or higher ) it is possible to connect to several HDFS servers from one IBM stream SPL application.
https://github.com/IBMStreams/streamsx.hdfs/releases
It is possible to read files from one HDFS Cluster and write them to the other HDFS Cluster.
Or it is possible to split the incoming streams in two or n streams and write every stream in a different HDFS file system.
The following configuration shows an overview about the connection of one IBM stream application to two different HDFS file systems.
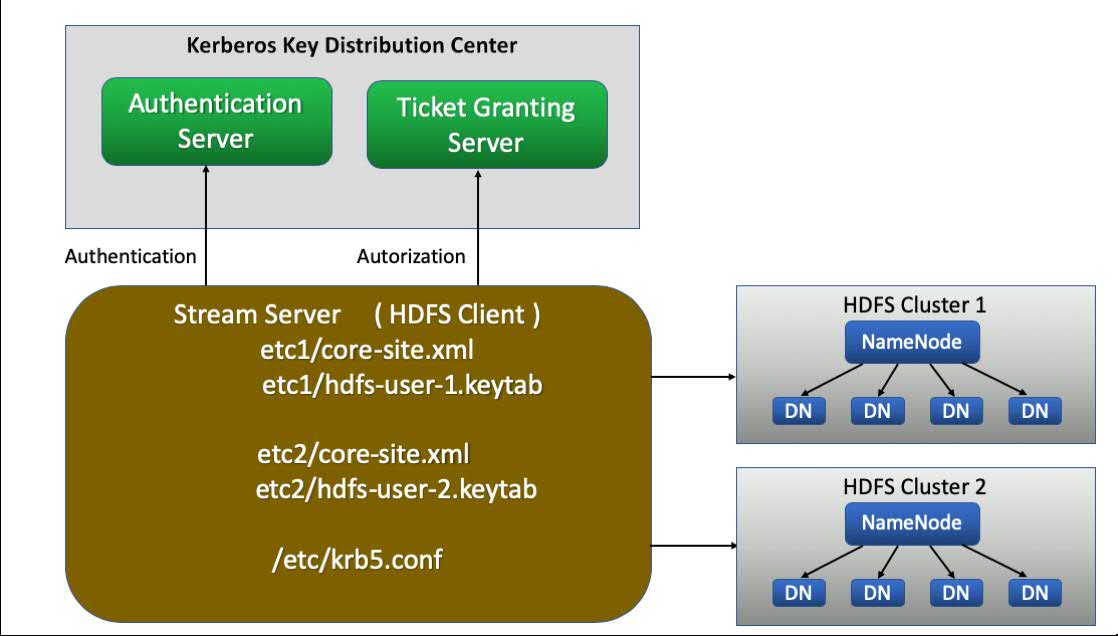
An HDFS Cluster is comprised of a NameNode, which manages the cluster metadata, and DataNodes (DN) that store the data. Files and directories are represented on the NameNode by inodes. Inodes record attributes like permissions, modification and access times, or namespace and disk space quotas.
More details in:
https://hortonworks.com/apache/hdfs/#section_2
https://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html
https://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/ClusterSetup.html
The following SPL sample demonstrates how to connect from one IBM stream application to two different HDFS servers.
Before you start with the SPL application, please perform the following steps:
- Add the IP Address and the host names of both HDFS clusters into /etc/hosts file of stream server.
- Copy the core-site-xml file from HDFS Cluster 1 into etc1 directory in your SPL project
- Copy the core-site-xml file from HDFS Cluster 2 into etc2 directory in your SPL project
- Copy the hdfs-user keytab from HDFS Cluster 1 into etc1 directory in your SPL project
- Copy the hdfs-user keytab from HDFS Cluster 2 into etc2 directory in your SPL project
In some configuration the Kerberos key distribution center is installed on the same HDFS server.
Make sure that the both HDFS server have the same realm as kerberos configuration.
The ambari creates for two HDFS servers separate keytab files with the same name.
For example
/etc/security/keytabs/hdfs.headless.keytab
But they are different keytab files and have different principals.
Here is the SPL sample:
namespace application ;
use com.ibm.streamsx.hdfs::HDFS2FileSink ;
composite HdfsKerberos
{
graph
// generates 20 lines
stream<rstring line> LineIn = Beacon(){
param
initDelay : 1.0 ;
period : 1.00;
iterations : 20u ;
output
LineIn : line = "line" +(rstring)IterationCount();
}
() as printLineIn = Custom(LineIn)
{
logic
onTuple LineIn : printStringLn(line);
}
// writes lines into HDFS 1
() as lineSink1 = HDFS2FileSink(LineIn)
{
param
// copy the kerberos keytab file for your hdfs user from first HDFS server
// into etc1 directory
// and change the value of authKeytab with your file name
authKeytab : "etc1/hdfs.headless1.keytab" ;
// kerberos principal for your hdfs user from first HDFS server
// replace it with your principal
authPrincipal : "hdfs-hdpcluster1@HDP2.COM";
// copy the core-site.xml file from HDFS server1 into etc1 directory
configPath : "etc1" ;
// Marke sure that the hdfsuser has write access to /user/xxxx directory on HDFS file system.
file :"TestFile-1.txt" ;
vmArg :"-Djava.security.krb5.conf=/etc/krb5.conf";
}
// writes lines into HDFS 2
() as lineSink2 = HDFS2FileSink(LineIn)
{
param
// copy teh kerberos keytab file for your hdfs user from secund HDFS server
// into etc2 directory
// and change the value of authKeytab with your file name
authKeytab : "etc2/hdfs.headless2.keytab" ;
// kerberos principal for your hdfs user from secund HDFS server
// replace it with your principal
authPrincipal : "hdfs-hdpcluster2@HDP2.COM";
// copy the core-site.xml file from HDFS server2 into etc2 directory
configPath : "etc2" ;
file :"TestFile-2.txt" ;
vmArg :"-Djava.security.krb5.conf=/etc/krb5.conf";
}
}