![]()


{kind=link}
KNAW Humanities Cluster
Centre for Language and Speech technology, Radboud University Nijmegen
Induction of Linguistic Knowledge Research Group, Tilburg University
Website: https://languagemachines.github.io/ucto/
Ucto tokenizes text files: it separates words from punctuation, and splits sentences. This is one of the first tasks for almost any Natural Language Processing application. Ucto offers several other basic preprocessing steps such as changing case that you can all use to make your text suited for further processing such as indexing, part-of-speech tagging, or machine translation.
Ucto comes with tokenisation rules for several languages (packaged separately) and can be easily extended to suit other languages. It has been incorporated for tokenizing Dutch text in Frog (https://languagemachines.github.io/frog), our Dutch morpho-syntactic processor.
The software is intended to be used from the command-line by researchers in Natural Language Processing or related areas, as well as software developers. An Ucto python binding is also available separately.
Features:
- Comes with tokenization rules for English, Dutch, French, Italian, Turkish, Spanish, Portuguese and Swedish; easily extendible to other languages. Rules consists of regular expressions and lists. They are packaged separately as uctodata.
- Recognizes units, currencies, abbreviations, and simple dates and times like dd-mm-yyyy
- Recognizes paired quote spans, sentences, and paragraphs.
- Produces UTF8 encoding and NFC output normalization, optionally accepting other input encodings as well.
- Ligature normalization (can undo for isntance fi,fl as single codepoints).
- Optional conversion to all lowercase or uppercase.
- Supports FoLiA XML
Ucto was written by Maarten van Gompel and Ko van der Sloot. Work on Ucto was funded by NWO, the Netherlands Organisation for Scientific Research, under the Implicit Linguistics project, the CLARIN-NL program, and the CLARIAH project.
This software is available under the GNU Public License v3 (see the file COPYING).
To install Ucto, first consult whether your distribution's package manager has an up-to-date package:
- Alpine Linux users can do
apk install ucto. - Debian/Ubuntu users can do
apt install uctobut this version will likely be significantly out of date! - Arch Linux users can install Frog via the AUR.
- macOS users with homebrew can do:
brew tap fbkarsdorp/homebrew-lamachine && brew install ucto - An OCI container image is also available and can be used with Docker:
docker pull proycon/ucto. Alternatively, you can build an OCI container image yourself using the providedDockerfilein this repository.
To compile and install manually from source:
$ bash bootstrap.sh
$ ./configure
$ make
$ sudo make install
If you want to automatically download, compile and install the latest stable versions of
the required dependencies, then run ./build-deps.sh prior to the above. You
can pass a target directory prefix as first argument and you may need to
prepend sudo to ensure you can install there. The dependencies are:
- ticcutils - A shared utility library
- libfolia - A library for the FoLiA format.
- uctodata - Data files for ucto, packaged separately
If you already have these dependencies, e.g. through a package manager or manually installed, then you should skip this step.
You will still need to take care to install the following 3rd party dependencies through your distribution's package manager, as they are not provided by our script:
icu- A C++ library for Unicode and Globalization support. On Debian/Ubuntu systems, install the package libicu-dev.libxml2- An XML library. On Debian/Ubuntu systems install the package libxml2-dev.libexttextcat- A language detection package.- A sane build environment with a C++ compiler (e.g. gcc 4.9 or above or clang), make, autotools, libtool, pkg-config
Tokenize an english text file to standard output, tokens will be
space-seperated, sentences delimiter by <utt>:
$ ucto -L eng yourfile.txt
The -L flag specifies the language (as a three letter iso-639-3 code), provided a configuration file exists for that language. The configurations are provided separately, for various languages, in the uctodata package. Note that older versions of ucto used different two-letter codes, so you may need to update the way you invoke ucto.
To output to file instead of standard output, just add another positional argument with the desired output filename.
If you want each sentence on a separate line (i.e. newline delimited rather than delimited by
<utt>), then pass the -n flag. If each sentence is already on one line
in the input and you want to leave it at that, pass the -m flag.
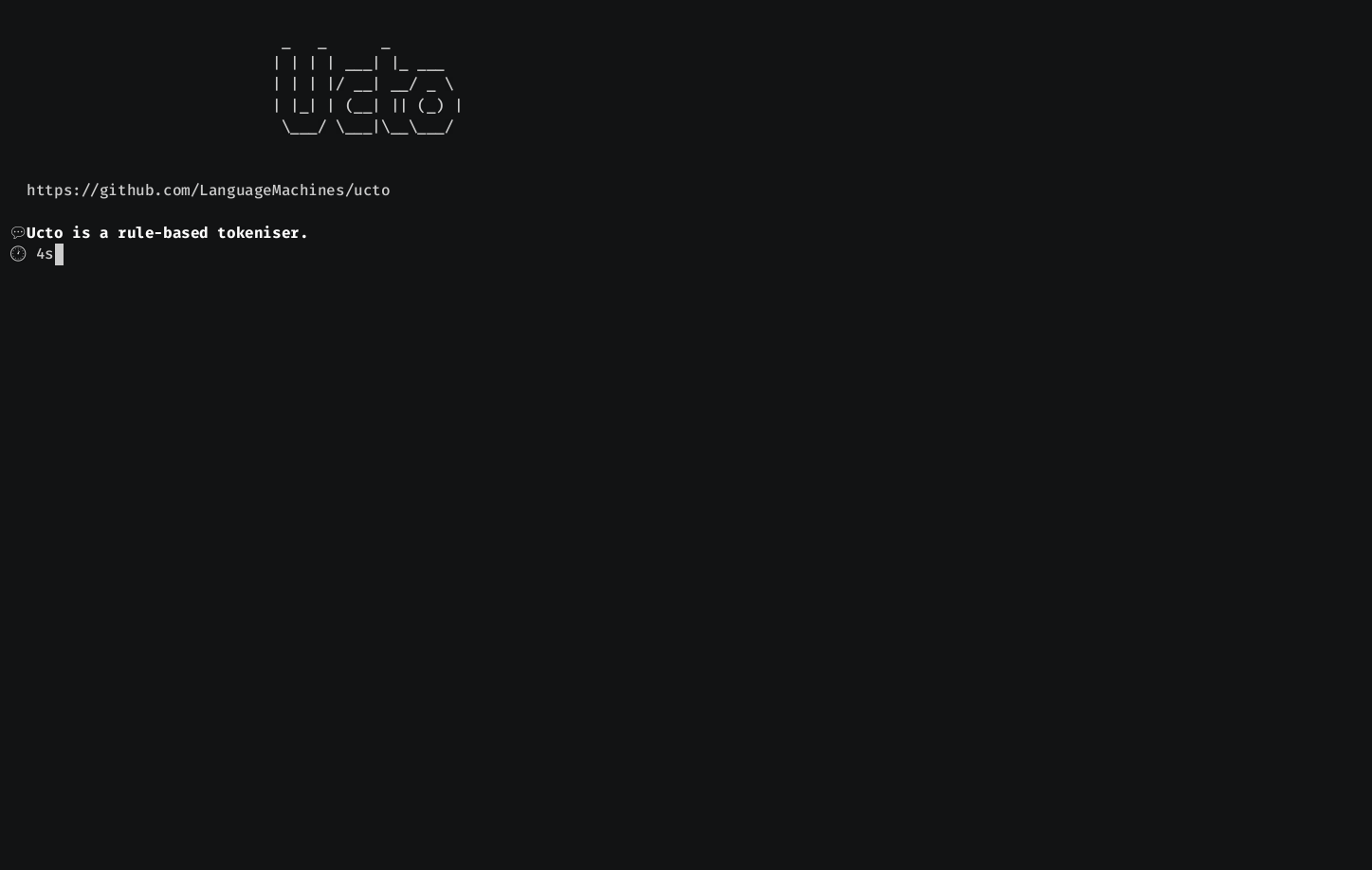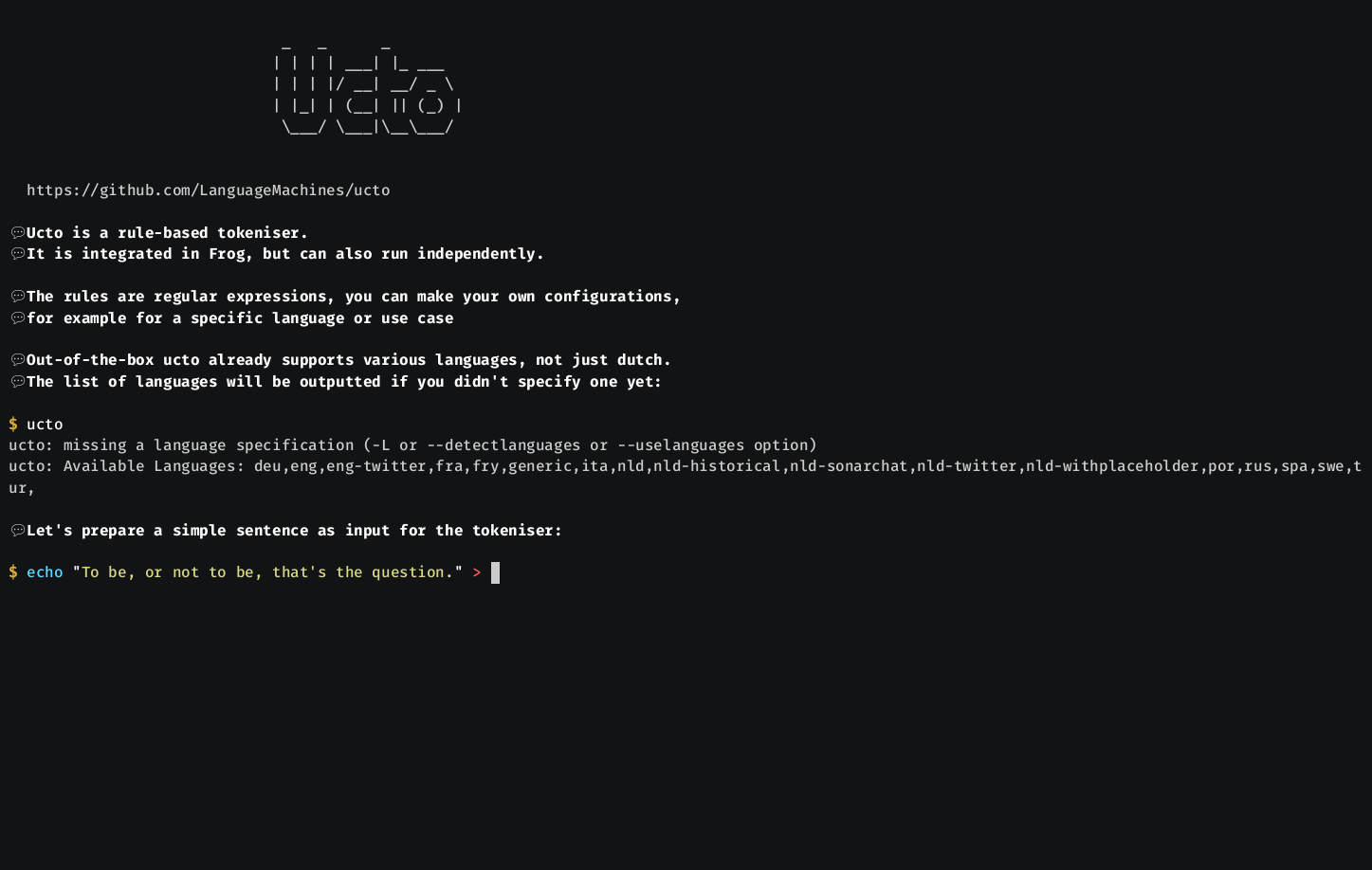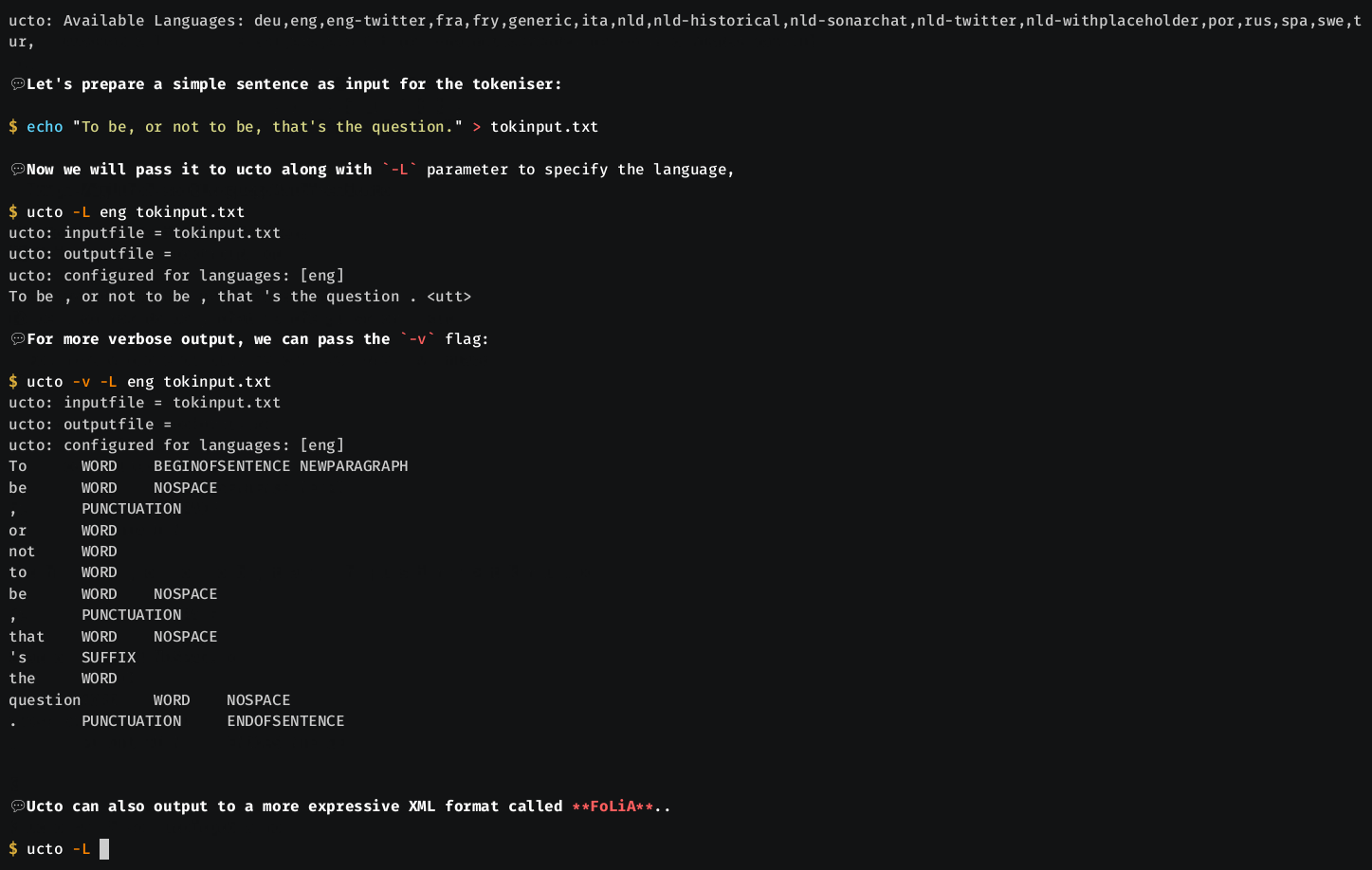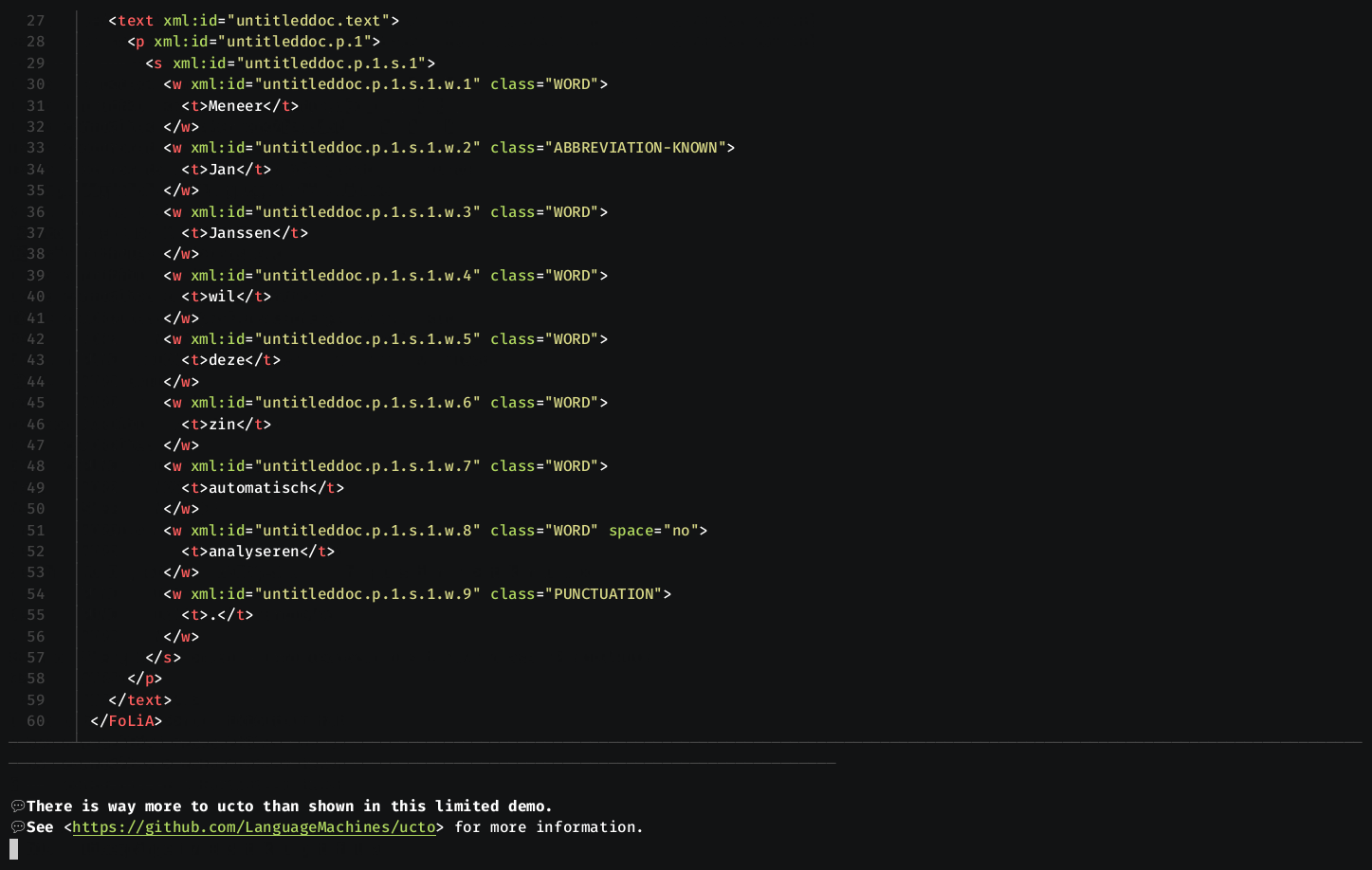
Tokenize plaintext to FoLiA XML using the -X flag, you can specify an ID
for the FoLiA document using the --id= flag.
$ ucto -L eng -X --id=hamlet hamlet.txt hamlet.folia.xml
Note that in the FoLiA XML output, ucto encodes the class of the token (date, url, smiley, etc...) based on the rule that matched.
For further documentation consult the ucto documentation.
A pre-made container image can be obtained from Docker Hub as follows:
docker pull proycon/ucto
Alternatively, you can build a docker container as follows, make sure you are in the root of this repository:
docker build -t proycon/ucto .
This builds the latest stable release, if you want to use the latest development version from the git repository instead, do:
docker build -t proycon/ucto --build-arg VERSION=development .
Run the container interactively as follows, you can pass any additional arguments that ucto takes.
docker run -t -i proycon/ucto
Add the -v /path/to/your/data:/data parameter (before -t) if you want to mount your data volume into the container at /data.
If you are looking to run Ucto as a webservice yourself, please see https://github.com/proycon/ucto_webservice . It is not included in this repository.