![]()

整体系统架构图
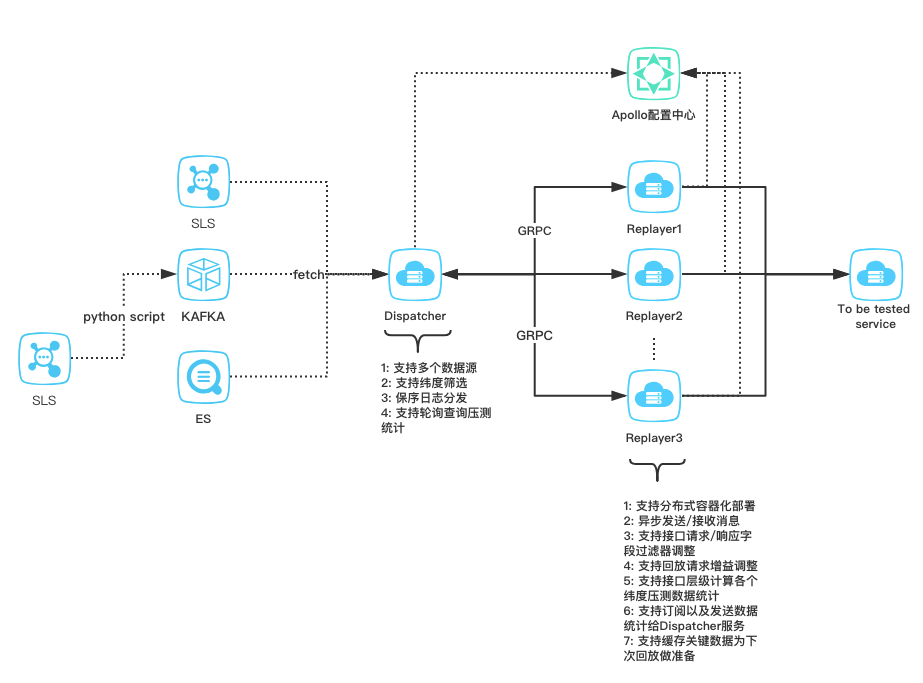
Dispatcher设计
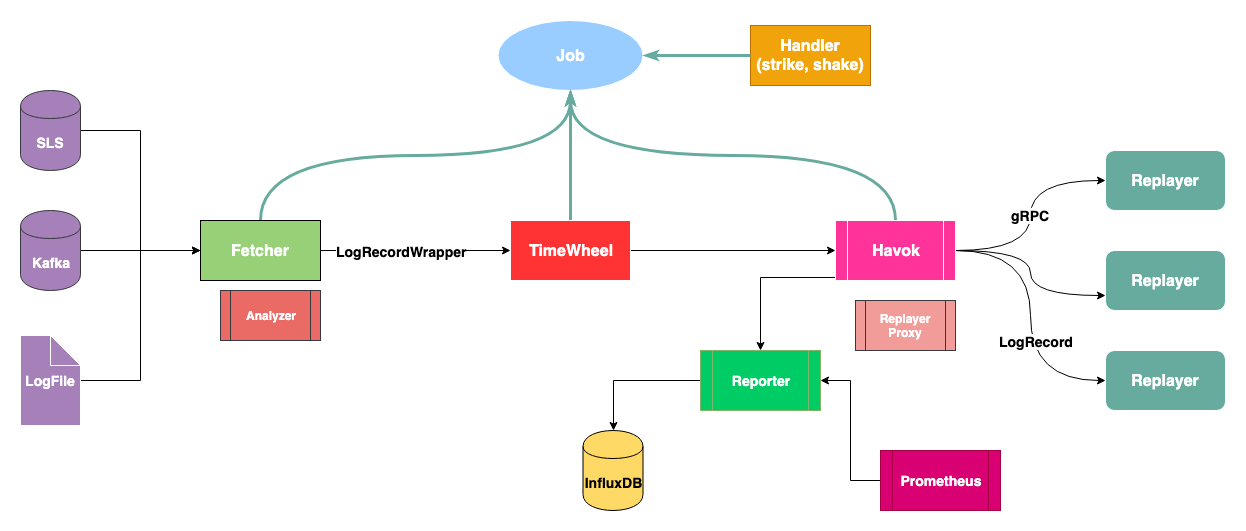
Dispatcher在整个架构里承担了日志数据的索引(下载)、排序(有规则约束)、时间控制、请求分发的任务,其主要有四大组件:
Fetcher负责对日志数据的索引以及反序列化(LogRecord),其定义为
type Fetcher interface{
TimeRange(begin, end time.Time)
WithAnalyzer(Analyzer)
SetOutput(chan<- *LogRecordWrapper)
SubTask
}其具体实现有以下几种:
FileFetcher: 本地单日志文件采集AliyunSLSConcurrencyFetcher: 阿里云SLS日志采集,因SLS日志不是严格排序的,该Fetcher会重排序一秒以内的日志KafkaSinglePartitionFetcher: 单Partition的Kafka采集器,无须重排序
未来计划实现以下Fetcher:
ElasticFetcher: ElasticSearch的日志收集对象KafkaFetcher: 完善的Kafka采集器,支持单topic、多partition
日志分析器,是Fetcher的组件之一,用于将采集到的单行日志[]byte反序列化成LogRecordWrapper对象
该interface定义如下:
type Analyzer interface {
Use(...AnalyzeFunc)
Analyze([]byte) *LogRecordWrapper
}一般情况下,你只需要实现一个AnalyzeFunc即可:
type AnalyzeFunc func([]byte) (*LogRecordWrapper, bool)时间轮,负责接收来自Fetcher的LogRecordWrapper数据并严格按照时间顺序发送给Havok
TimeWheel时钟递增幅度由defaultTimeWheelInterval来控制,当前设置为十毫秒,理论上日志发送会比较顺滑
同时TimeWheel也支持快放、慢放(可联想成播放器),由任务的JobConfiguration.Speed字段控制
项目的同名组件,实际为一个gRPC Server,负责与不同的Replayer通讯
该服务仅暴露两个rpc接口:
service Havok {
rpc Subscribe (ReplayerRegistration) returns (stream DispatcherEvent) {
}
rpc Report (StatsReport) returns (ReportReturn) { // 返回值标示在哪次request_id中断
}
}
Subscribe: replayer主动调用,dispatcher下发的信令都走DispatcherEvent流Report: replayer完成压测数据统计后调用
该对象赋予了Havok定向投递LogRecord的能力:
// WithHashFunc 更新hash算法
func (ip *ReplayerProxy) WithHashFunc(ha HashFunc) *ReplayerProxy
type HashFunc func(string) uint32当LogRecordWrapper.HashField字段被赋值后(在Analyzer控制),ReplayerProxy对该字段就会进行hash计算,根据计算结果投递到具体的replayer
默认的的HashFunc为RoundTrip,轮询分发,也内置了FNV Hash算法
该组件提供了聚合压测报告以及上报第三方的能力,主要模块是从ultron中移植过来:
可以实现以下func来扩展对聚合后报表的处理能力:
type ReportHandleFunc func(types.Report)结合grafana等,能够实现如下的展示效果:
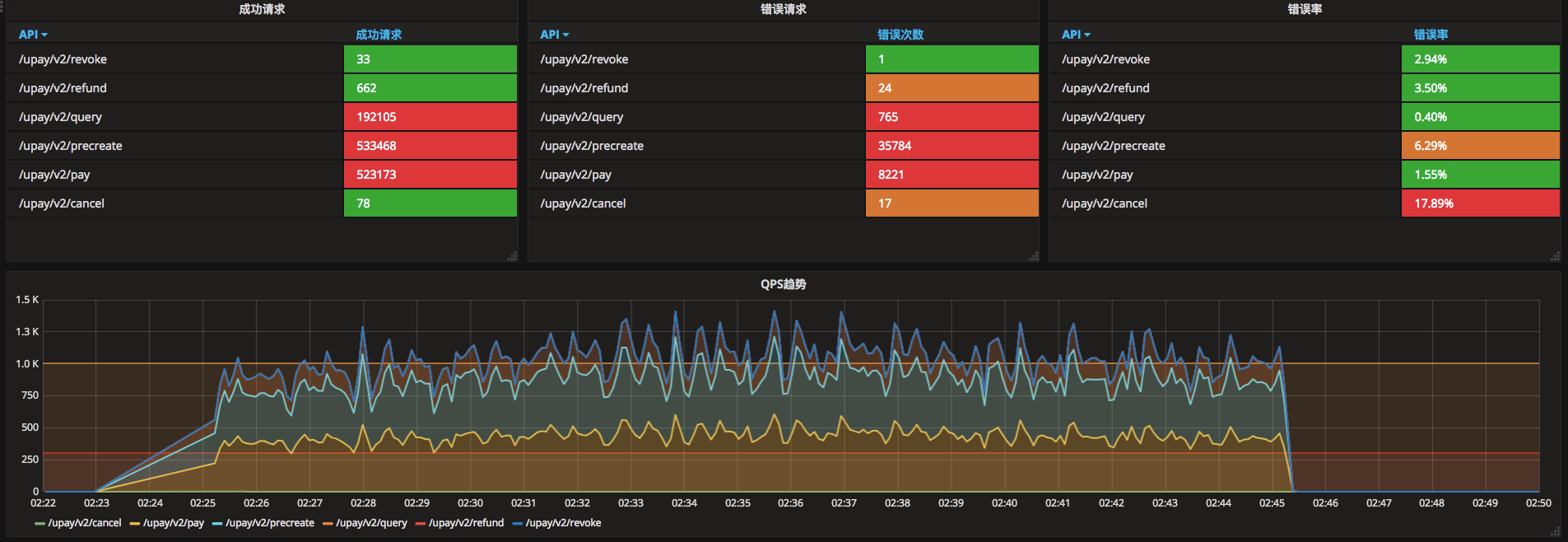
控制回放的时间范围、比例、速率,示例如下:
[job]
rate = 1.0 # 回放倍数,如2.0,表示一次请求回放两次
speed = 1.0 # 回放速率,如2.0,表示原来10秒内有5次请求发生,回放时会把这些请求在5秒回放完
begin = 1532058494000
end = 1532076494000使用FileFetcher
[fetcher]
type = "file"
[fetcher.file]
path = "havok_project.log"使用sls fetcher:
[fetcher]
type = "sls"
[fetcher.sls]
access_key_id = ""
access_key_secret = ""
region = "xxxx.log.aliyuncs.com"
project = "havok-project"
logstore = "havok-project"
expression = "arguments=* and message=\"invoking method start\"" # sls查询表达式
concurrency = 8
pre-download = 5000使用kafka fetcher
[fetcher]
type = "kafka-single-partition"
[fetcher.kafka]
brokers = ["127.0.0.1:9092", "127.0.0.1:9192"]
topic = "havok_project_pressure"
offset = -2 # oldestdispatcher同时启动了gRPC服务以及http服务,以下配置控制监听的端口
[service] # 暂时无效
http = ":16200"
grpc = ":16300"[reporter]
[reporter.influxdb]
url = "http://127.0.0.1:8086"
database = "stress-test"
user = ""
password = ""