No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks
=======
Languages
Disclaimer
This repository and its contents are for academic and educational purposes only. All materials do not constitute financial, legal, or investment advice. No express or implied warranty is provided for the accuracy, completeness, or usefulness of the content. The authors and contributors are not responsible for any errors, omissions, or consequences arising from the use of the information on this website. Users should exercise their own judgment and consult professional advisors before making any financial, legal, or investment decisions. The use of any software and information contained in this repository is entirely at the user's own risk.
By using or accessing information in this repository, you agree to indemnify, defend, and hold harmless the authors, contributors, and any affiliated organizations or individuals from any and all claims or damages.
📢 Update (Date: 2024/03/12)
🐹 We are excited to share our paper, "No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks".
ICE-PIXIU is our comprehensive framework, featuring the first cross-lingual bilingual financial instruction dataset ICE-FIND, large language model ICE-INTENT, and evaluation benchmark ICE-FLARE. ICE-PIXIU combines various Chinese classification, extraction, reasoning, and prediction financial NLP tasks, enhancing training and performance to address the shortcomings in Chinese financial NLP. It simultaneously integrates a series of translated and original English datasets, enriching the breadth and depth of bilingual financial modeling. It offers unrestricted access to various model variants, a compilation of diverse cross-lingual and multi-modal instruction data, and an evaluation benchmark with expert annotations, encompassing 10 NLP tasks and 20 bilingual specific tasks. Our comprehensive evaluation emphasizes the advantages of combining these bilingual datasets, particularly in translation tasks and leveraging original English data, thereby enhancing language flexibility and analytical acumen in financial contexts.
- Bilingual Capability: ICE-INTENT, a component of ICE-PIXIU, excels in Chinese-English bilingual abilities, crucial for global financial data processing and analysis.
- Diverse Data: ICE-PIXIU combines various Chinese classification, extraction, reasoning, and prediction NLP tasks, strengthening training and performance to address shortcomings in Chinese financial NLP.
- Expert Prompts: ICE-PIXIU offers a set of diverse, high-quality, expert-annotated prompts and adopts similar fine-tuning instructions to enhance understanding of financial tasks.
- Multilingual: ICE-PIXIU extends its capabilities by incorporating translation tasks and English datasets, thereby strengthening its bilingual training and application.
- Cross-lingual Evaluation: ICE-PIXIU introduces ICE-FLARE, a rigorous cross-lingual evaluation benchmark ensuring consistent model performance across different language contexts.
- Openness: ICE-PIXIU adopts an open-access approach, offering resources to the research community to foster collaborative development in financial NLP.
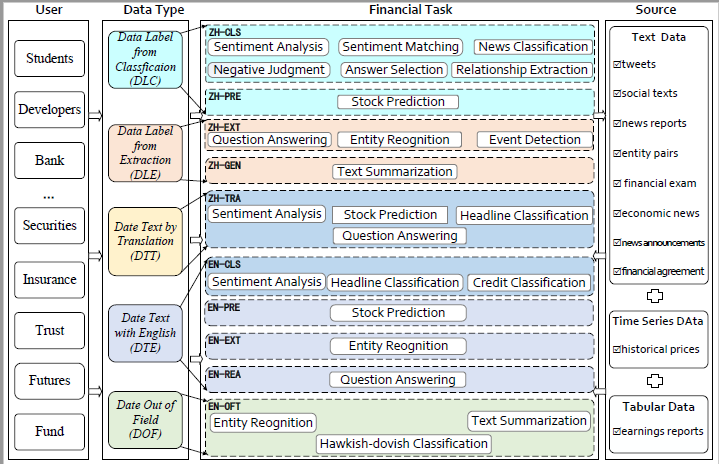
ICE-PIXIU provides services in various financial scenarios for different user groups with its unique data types, financial tasks, and data sources in Chinese and English bilingual domains.
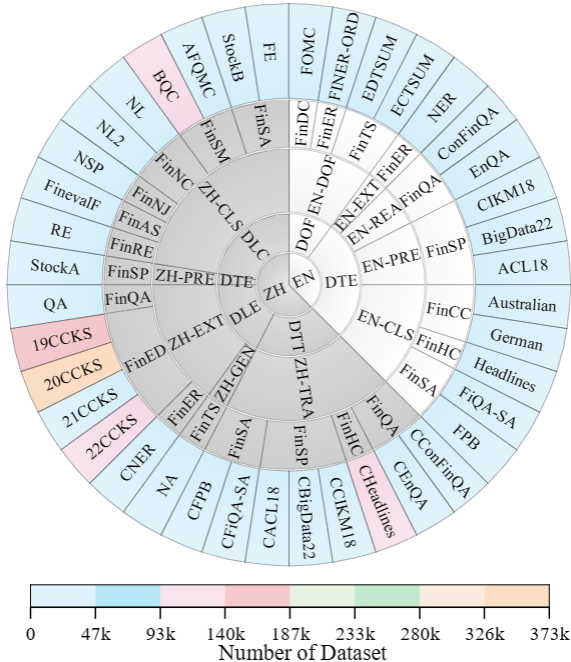
Sunburst chart describing the distribution of ICE-PIXIU across different language capabilities, data types, financial NLP tasks, specific financial tasks, and datasets
Evaluation Data
All our evaluation datasets can be found here.
Datasets (Evaluation Test)
Sentiment Analysis(FinSA)
- ICE-FLARE (zh-FE)
- ICE-FLARE (zh-stockB)
- ICE-FLARE (zh-FPB)
- ICE-FLARE (zh-Fiqasa)
- ICE-FLARE (en-FPB)
- ICE-FLARE (en-Fiqasa)
Semantic Matching(FinSM)
News Classification(FinNS)
Negative Judgment(FinNJ)
Answer Selection(FinAS)
Relationship Extraction(FinRE)
Headline Classification(FinHC)
Credit Classification(FinCC)
Hawkish-dovish Classification(FinDC)
Event Detection(FinED)
Entity Recognition(FinER)
Question Answering(FinQA)
- ICE-FLARE (zh-QA)
- ICE-FLARE (zh-EnQA)
- ICE-FLARE (zh-ConvFinQa)
- ICE-FLARE (en-EnQA)
- ICE-FLARE (en-ConvFinQa)
Stock Prediction(FinSF)
- ICE-FLARE (zh-stockA)
- ICE-FLARE (zh-BigData)
- ICE-FLARE (zh-ACL)
- ICE-FLARE (zh-CIKM)
- ICE-FLARE (en-BigData)
- ICE-FLARE (en-ACL)
- ICE-FLARE (en-CIKM)
Text Summarization(FinTS)
Adding Cross-Lingual Datasets
Data Summary Table: Detailed information on Chinese-English bilingual multi-task financial teaching and evaluation raw data, including language capability (Lang), data type (D_T), NLP task (NLP_T), specific task (S_T), dataset name, instruction data size, evaluation data size, data source, and license information.
| Lang | D_T | NLP_T | S_T | Dataset | Raw | Instruction | Evaluation | Data Source | License |
| ZH | DLC | ZH-CLS | FinSA | FE | 18,177 | 18,177 | 2,020 | social texts | Public |
| StockB | 9,812 | 9,812 | 1,962 | social texts | Apache-2.0 | ||||
| FinSM | BQC | 120,000 | 110,000 | 10,000 | bank service logs | Public | |||
| AFQMC | 38,650 | 38,650 | 4,316 | online chat service | Apache-2.0 | ||||
| FinNC | NL | 7,955 | 7,955 | 884 | news articles | Public | |||
| NL2 | 7,955 | 7,955 | 884 | news articles | Public | ||||
| FinNJ | NSP | 4,499 | 4,499 | 500 | social texts | Public | |||
| FinAS | FinevalF | 1,115 | 1,115 | 222 | financial exam | Apache-2.0 | |||
| FinRE | RE | 14,973 | 14,973 | 1,489 | news, entity pairs | Public | |||
| ZH-PRE | FinSP | StockA | 14,769 | 14,769 | 1,477 | news, historical prices | Public | ||
| DLE | ZH-EXT | FinQA | QA | 22,375 | 22,375 | 2,469 | QA pairs of news | Public | |
| FinER | CNER | 1,685 | 1,685 | 337 | financial reports | Public | |||
| FinED | 19CCKS | 156,834 | 14,674 | 2,936 | social texts | CC BY-SA 4.0 | |||
| 20CCKS | 372,810 | 45,796 | 9,159 | news, reports | CC BY-SA 4.0 | ||||
| 21CCKS | 8,000 | 7,000 | 1,400 | news, reports | CC BY-SA 4.0 | ||||
| 22CCKS | 109,555 | 59,143 | 11,829 | news, reports | CC BY-SA 4.0 | ||||
| ZH-GEN | FinTS | NA | 32,400 | 32,400 | 3,600 | news, announcements | Public | ||
| DTT | ZH-TRA | FinSA | CFPB | 4,845 | 4,838 | 970 | economic news | MIT license | |
| CFiQA-SA | 1,173 | 1,143 | 233 | news headlines, tweets | MIT license | ||||
| FinSP | CACL | 27,056 | 2,555 | 511 | tweets, historical prices | MIT license | |||
| CBigdata | 7,167 | 798 | 159 | tweets, historical prices | MIT license | ||||
| CCIKM | 4,970 | 431 | 86 | tweets, historical prices | MIT license | ||||
| FinHC | CHeadlines | 102,708 | 10,256 | 2,051 | news headlines | MIT license | |||
| FinQA | CEnQA | 8,281 | 668 | 133 | earnings reports | MIT license | |||
| CConvFinQA | 12,594 | 1,189 | 237 | earnings reports | MIT license | ||||
| EN | DTE | EN-CLS | FinSA | FPB | 4,845 | 4,845 | 970 | economic news | CC BY-SA 3.0 |
| FiQA-SA | 1,173 | 1,173 | 235 | news headlines, tweets | Public | ||||
| FinHC | Headlines | 11,412 | 102,708 | 20,547 | news headlines | CC BY-SA 3.0 | |||
| FinCC | German | 1,000 | 1,000 | 200 | credit records | CC BY-SA 4.0 | |||
| Australian | 690 | 690 | 139 | credit records | CC BY-SA 4.0 | ||||
| EN-PRE | FinSP | ACL18 | 27,053 | 27,053 | 3,720 | tweets, historical prices | MIT License | ||
| BigData22 | 7,164 | 7,164 | 1,472 | tweets, historical prices | Public | ||||
| CIKM18 | 4,967 | 4,967 | 1,143 | tweets, historical prices | Public | ||||
| EN-EXT | FinER | NER | 609 | 609 | 98 | financial agreements | CC BY-SA-3.0 | ||
| EN-REA | FinQA | EnQA | 8,281 | 8,281 | 1,147 | earnings reports | MIT License | ||
| ConvFinQA | 3,458 | 12,594 | 1,490 | earnings reports | MIT License | ||||
| DOF | EN-DOF | FinER | Finer-Ord | 1,075 | - | 1,075 | news articles | CC BY-SA 4.0 | |
| FinTS | ECTSUM | 495 | - | 495 | earning call transcripts | Public | |||
| EDTSUM | 2,000 | - | 2,000 | news articles | Public | ||||
| FinDC | FOMC | 496 | - | 496 | FOMC transcripts | CC BY-SA 4.0 |
- ICE-INTERN-7B (Instruction-tuned model with all DLC data)
- ICE-INTERN-7B (Instruction-tuned model with all DCL+DLE data)
- ICE-INTERN-7B (Instruction-tuned model with all DCL+DLE+DTT data)
- ICE-INTERN-7B (Instruction-tuned model with all instruction data)
During the fine-tuning process, we employed QLoRA, an efficient parameter tuning technique, using a uniform sequence length of 2048 tokens. The fine-tuning process utilized the AdamW optimizer with an initial learning rate of 5e-5 and a weight decay of 1e-5, along with a 1% total step warm-up. All models underwent one round of fine-tuning on eight A100 40GB GPUs with a batch size of 24, using consistent hyperparameter settings.
In order to conduct comparative analysis with other general large models (including Baichuan, ChatGPT, Qwen, etc.) and financial large models, we have selected a series of tasks and metrics that cover various aspects of financial natural language processing and financial forecasting.
| Data | Task | Raw | Data Types | Modalities | License | Paper |
|---|---|---|---|---|---|---|
| AFQMC | Semantic Matching | 38,650 | Question Data, Dialogue | Text | Apache-2.0 | [1] |
| corpus | Semantic Matching | 120,000 | Question Data, Dialogue | Text | Public | [2] |
| stockA | Stock Classification | 14,769 | News, Historical Prices | Text, Time Series | Public | [3] |
| Fineval | Multiple Choice | 1,115 | Financial Exams | Text | Apache-2.0 | [4] |
| NL | News Classification | 7,955 | News Reports | Text | Public | [5] |
| NL2 | News Classification | 7,955 | News Reports | Text | Public | [5] |
| NSP | Negative News Judgement | 4,499 | News, Social Media Text | Text | Public | [5] |
| RE | Relation Extraction | 14,973 | News, Entity Pair | Text | Public | [5] |
| FE | Sentiment Analysis | 18,177 | Financial Social Media Text | Text | Public | [5] |
| stockB | Sentiment Analysis | 9,812 | Financial Social Media Text | Text | Apache-2.0 | [6] |
| QA | Financial Q&A | 22,375 | Financial News Announcements | Text, Tables | Public | [5] |
| NA | Text Summarization | 32,400 | News Articles, Announcements | Text | Public | [5] |
| 19CCKS | Event Subject Extraction | 156,834 | News Reports | Text | CC BY-SA 4.0 | [7] |
| 20CCKS | Event Subject Extraction | 372,810 | News Reports | Text | CC BY-SA 4.0 | [8] |
| 21CCKS | Event Causal Relationship Extraction | 8,000 | News Reports | Text | CC BY-SA 4.0 | [9] |
| 22CCKS | Event Subject Extraction | 109,555 | News Reports | Text | CC BY-SA 4.0 | [10] |
| CNER | Named Entity Recognition | 1,685 | News Reports | Text | Public | [11] |
| CFPB | Sentiment Analysis | 4,845 | News | Text | MIT license | [12] |
| CFIQASA | Sentiment Analysis | 1,173 | News Headlines, Tweets | Text | MIT license | [12] |
| CHeadlines | News Headline Classification | 11,412 | News Headlines | Text | MIT license | [12] |
| CBigData | Stock Trend Prediction | 7,164 | Tweets, Historical Prices | Text, Time Series | MIT license | [12] |
| CACL | Stock Trend Prediction | 27,053 | Tweets, Historical Prices | Text, Time Series | MIT license | [12] |
| CCIKM | Stock Trend Prediction | 4,967 | Tweets, Historical Prices | Text, Time Series | MIT license | [12] |
| CFinQA | Financial Q&A | 14,900 | Earnings Reports | Text, Tables | MIT license | [12] |
| CConvFinQA | Multi-Turn Q&A | 48,364 | Earnings Reports | Text, Tables | MIT license | [12] |
- Xu L, Hu H, Zhang X, et al. CLUE: A Chinese language understanding evaluation benchmark[J]. arXiv preprint arXiv:2004.05986, 2020.
- Jing Chen, Qingcai Chen, Xin Liu, Haijun Yang, Daohe Lu, and Buzhou Tang. 2018. The BQ Corpus: A Large-scale Domain-specific Chinese Corpus For Sentence Semantic Equivalence Identification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4946–4951, Brussels, Belgium. Association for Computational Linguistics.
- Jinan Zou, Haiyao Cao, Lingqiao Liu, Yuhao Lin, Ehsan Abbasnejad, and Javen Qinfeng Shi. 2022. Astock: A New Dataset and Automated Stock Trading based on Stock-specific News Analyzing Model. In Proceedings of the Fourth Workshop on Financial Technology and Natural Language Processing (FinNLP), pages 178–186, Abu Dhabi, United Arab Emirates (Hybrid). Association for Computational Linguistics.
- Zhang L, Cai W, Liu Z, et al. FinEval: A Chinese Financial Domain Knowledge Evaluation Benchmark for Large Language Models[J]. arxiv preprint arxiv:2308.09975, 2023.
- Lu D, Liang J, Xu Y, et al. BBT-Fin: Comprehensive Construction of Chinese Financial Domain Pre-trained Language Model, Corpus and Benchmark[J]. arxiv preprint arxiv:2302.09432, 2023.
- https://huggingface.co/datasets/kuroneko5943/stock11
- https://www.biendata.xyz/competition/ccks_2019_4/
- https://www.biendata.xyz/competition/ccks_2020_4_1/
- https://www.biendata.xyz/competition/ccks_2021_task6_2/
- https://www.biendata.xyz/competition/ccks2022_eventext/
- Jia C, Shi Y, Yang Q, et al. Entity enhanced BERT pre-training for Chinese NER[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 6384-6396.
- Xie Q, Han W, Zhang X, et al. PIXIU: A Large Language Model, Instruction Data and Evaluation Benchmark for Finance[J]. arXiv preprint arXiv:2306.05443, 2023.
Benchmark Evaluation Environment Deployment
git clone https://github.com/chancefocus/PIXIU.git --recursive
cd PIXIU
pip install -r requirements.txt
cd PIXIU/src/financial-evaluation
pip install -e .[multilingual]sudo bash scripts/docker_run.shThe above command will start a Docker container. You can modify docker_run.sh according to your own environment. We provide the pre-compiled image by running sudo docker pull tothemoon/pixiu:latest.
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
--network host \
--env https_proxy=$https_proxy \
--env http_proxy=$http_proxy \
--env all_proxy=$all_proxy \
--env HF_HOME=$hf_home \
-it [--rm] \
--name pixiu \
-v $pixiu_path:$pixiu_path \
-v $hf_home:$hf_home \
-v $ssh_pub_key:/root/.ssh/authorized_keys \
-w $workdir \
$docker_user/pixiu:$tag \
[--sshd_port 2201 --cmd "echo 'Hello, world!' && /bin/bash"]Parameter Description:
[]indicates optional parametersHF_HOME: Hugging Face cache directorysshd_port: The SSHD port of the container. You can runssh -i private_key -p $sshd_port root@$ipto connect to the container. The default is 22001.--rm: Remove the container upon exit (i.e.,CTRL + D).
Before evaluation, please download the BART checkpoint to src/metrics/BARTScore/bart_score.pth.
To perform automatic evaluation, please follow the instructions below:
- Hugging Face Transformer
To evaluate models hosted on the Hugging Face Hub (e.g., ICE-INTERN-Full-7B), please use this command:
python eval.py \
--model "hf-causal-llama" \
--model_args "use_accelerate=True,pretrained=chancefocus/finma-7b-full,tokenizer=chancefocus/finma-7b-full,use_fast=False" \
--tasks "flare_ner,flare_sm_acl,flare_fpb"For more details, please refer to the lm_eval documentation.
- Commercial API
Please note that for tasks such as NER, automatic evaluation is based on specific patterns. This may not extract relevant information in zero-shot settings, resulting in performance that is relatively lower than previous human-annotated results.
export OPENAI_API_SECRET_KEY=YOUR_KEY_HERE
python eval.py \
--model gpt-4 \
--tasks flare_zh_fe,flare_cner,flare_sm_acl- Self-Hosted Evaluation
To run the inference backend, please execute the following command:
bash scripts/run_interface.sh| Task | Metric | Illustration |
|---|---|---|
| Classification | Accuracy | This metric represents the ratio of correctly predicted observations to the total observations. The calculation formula is (correct predictions + incorrect predictions) / total observations. |
| Classification | F1 Score | The F1 score represents the harmonic mean of precision and recall, achieving a balance between these two factors. It is particularly useful when one factor is more important than the other. The score ranges from 0 to 1, where 1 indicates perfect precision and recall, and 0 indicates the worst case. Additionally, we provide "weighted" and "macro" versions of the F1 score. |
| Classification | Missing Ratio | This metric calculates the proportion of responses that did not return any option among the given options in the task. |
| Classification | Matthews Correlation Coefficient (MCC) | MCC is a metric for assessing the quality of binary classification, with scores ranging from -1 to +1. A score of +1 indicates perfect prediction, 0 indicates no better than random chance, and -1 indicates completely opposite predictions. |
| Sequence Labeling | F1 Score | In "sequence labeling" tasks, we use the F1 score calculated by the "seqeval" library, which is a robust entity-level evaluation metric. This metric requires a complete match of entity spans and types between predicted entities and ground truth entities for correct evaluation. True positives (TP) represent correctly predicted entities, false positives (FP) represent incorrectly predicted entities or spans/types that do not match, and false negatives (FN) represent entities missed from the ground truth. These quantities are then used to calculate precision, recall, and F1 score, where the F1 score represents the harmonic mean of precision and recall. |
| Sequence Labeling | Label F1 Score | This metric evaluates model performance solely based on the correctness of predicted labels, without considering entity spans. |
| Relation Extraction | Precision | Precision measures the proportion of correctly predicted relations among all predicted relations. It is calculated as the number of true positives (TP) divided by the total of true positives and false positives (FP). |
| Relation Extraction | Recall | Recall measures the proportion of correctly predicted relations among all actual relations. It is calculated as the number of true positives (TP) divided by the total of true positives and false negatives (FN). |
| Relation Extraction | F1 Score | The F1 score is the harmonic mean of precision and recall, achieving a balance between these two metrics. The F1 score is best at 1 (both precision and recall are perfect) and worst at 0. |
| Extractive and Abstractive Summarization | Rouge-L | This metric assesses the longest common subsequence (LCS) between the system and the reference summary. The LCS naturally considers structural similarity at the sentence level and automatically identifies the longest co-occurring n-gram. |
| Extractive and Abstractive Summarization | Rouge-N | It measures the overlap of N-grams (a continuous sequence of N items in the given text sample) between the system-generated summary and the reference summary. "N" can be 1, 2, or more; ROUGE-1 and ROUGE-2 are typically used to evaluate unigram overlap and bigram overlap, respectively. |
| Question Answering | EMACC | EMACC evaluates the exact match between the model-generated answer and the reference answer. In other words, a model-generated answer is considered correct only if it matches the reference answer exactly. |
For specific financial tasks such as Question Answering (FinQA), Text Summarization (FinTS), Relation Extraction (FinRE), Event Detection (FinED), Entity Recognition (FinER), and News Classification (FinNC), various LLM input and response examples are provided.
| Task | Query | Baichuan-7B | GPT-4 | ICE-INTERN-full-7B |
|---|---|---|---|---|
| FinQA | 浦东建设公告,公司子公司上海市浦东新区建设(集团)有限公司、上海浦兴路桥建设工程有限公司中标多项重大工程项目,中标金额总计为10.94亿元。请问中标事件对应的主体有哪些? | 浦东建设、浦兴路桥、浦东建设(集团) | 中标事件对应的主体有上海市浦东新区建设(集团)有限公司 | 上海市浦东新区建设(集团)有限公司,上海浦兴路桥建设工程有限公司 |
| FinTS | 市场普遍预期日本央行将维持其超宽松货币政策不变,但知情人士表示,周二将公布的经济展望报告中,可能上调4月起财政年度的通胀预估。能源和原材料成本的上涨已将批发价格推高至40年来的最高水平,企业已开始将上涨的成本转嫁给消费者。近期通胀温和上升,主要是投入成本上升和日元疲软推动的,而不是强劲的国内需求。日本央行行长黑田东彦曾表示,物价上涨应该伴随着工资的强劲增长。请对上述金融报道进行总结,给出具有中心主旨的摘要,回答要求尽量简短。 | 日本央行行长黑田东彦曾表示,物价上涨应该伴随着工资的强劲增长。 | 日本央行预计将上调4月起的通胀预估,尽管市场普遍预期货币政策将保持超宽松。成本上涨推高批发价格,企业已将涨成本转嫁给消费者,但通胀主要由投入成本上升和日元疲软推动,而非国内需求强劲。 | 知情人士:日本央行可能上调4月起财政年度的通胀预估。 |
| FinRE | 新希望集团销售额约为上市公司倍有余,由于背靠农业帝国“希望系”, 资本市场一直预期集团能够向新希望股份注入农业资产, 如果集团资产整合启动, 新希望股份的股。请分析上述涉及实体对(新希望股份,新希望集团)的关系。 | 被收购 | 被注资 | 自己 |
| FinED | 大智慧(601519)信披违规遭调查“互联网+”炒作或终结金鹰等多家基金公司高管离职 基民担忧业绩波动。请分析上述金融报道中的事件类型及及其事件主体,并以‘事件类型,事件主体’的格式输出。 | 套现约1.5亿元 | 交易违规, 大智慧 | 信批违规, 大智慧 |
| FinER | 本公司非执行董事孙月英女士不再担任中国远洋海运集团有限公司总会计师和中远财务有限责任公司董事长。请给出上述金融报道中存在的个人(’PER’)、组 织(’ORG’)或地点(’LOC’)的特定命 名实体,回答应遵循的格式’实体名称, 实体类型’。 | 中国远洋海运集团有限公司,ORG | 中远海运发展股份有限公司, ORG | 孙月英, PER;中国远洋海运集团有限公司, ORG;中远财务有限责任公司, ORG |
| FinNC | WTI原油涨幅回升至0.5%,现报75.58美元/桶。请对该金融报道进行分类,具体属于['中国','外国','国际','公司','行业','大盘','经济','政策','政治','期货','债券','房地产','外汇','虚拟货币','新冠','能源']中的哪些类别? | 国际,能源 | 国际期货 |
If you use ICE-PIXIU in your project, please cite our article.
ICE-PIXIU is licensed under the [MIT] license. For details, please refer to the MIT file.