GA process output #154
Labels
question
Further information is requested
Comments
|
You can use the callback functions to print something about the progress. Please check this example: https://pygad.readthedocs.io/en/latest/README_pygad_ReadTheDocs.html#life-cycle-of-pygad |
|
@ahmedfgad I think the workflow may be wrong. I have tested and show my point of view. |

|
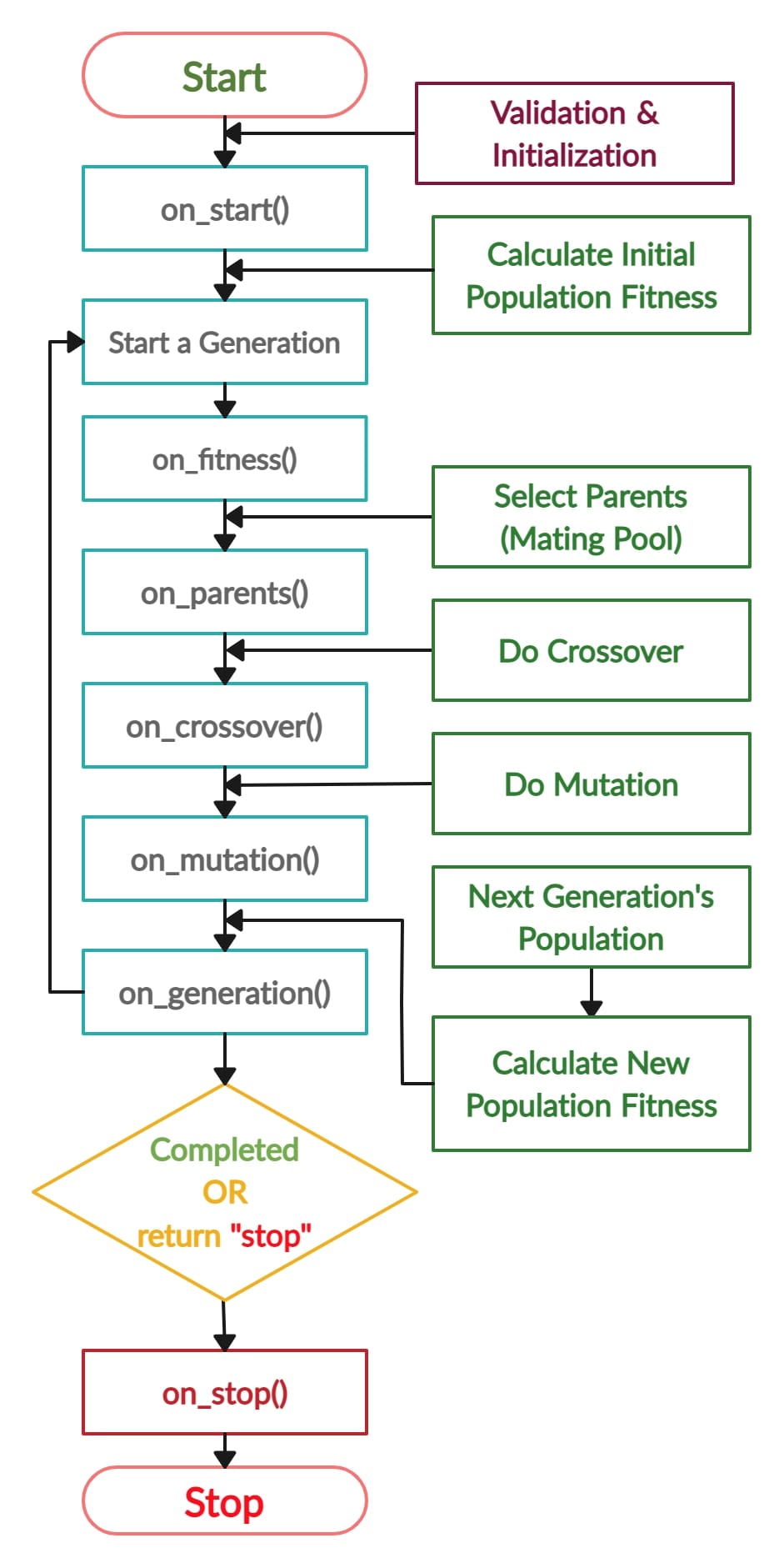
Yes you are right. The library went through some changes which affected some steps. This is the new lifecycle.
|
ahmedfgad
added a commit
that referenced
this issue
Feb 22, 2023
PyGAD 2.19.0 Release Notes 1. A new `summary()` method is supported to return a Keras-like summary of the PyGAD lifecycle. 2. A new optional parameter called `fitness_batch_size` is supported to calculate the fitness function in batches. If it is assigned the value `1` or `None` (default), then the normal flow is used where the fitness function is called for each individual solution. If the `fitness_batch_size` parameter is assigned a value satisfying this condition `1 < fitness_batch_size <= sol_per_pop`, then the solutions are grouped into batches of size `fitness_batch_size` and the fitness function is called once for each batch. In this case, the fitness function must return a list/tuple/numpy.ndarray with a length equal to the number of solutions passed. #136. 3. The `cloudpickle` library (https://github.com/cloudpipe/cloudpickle) is used instead of the `pickle` library to pickle the `pygad.GA` objects. This solves the issue of having to redefine the functions (e.g. fitness function). The `cloudpickle` library is added as a dependancy in the `requirements.txt` file. #159 4. Support of assigning methods to these parameters: `fitness_func`, `crossover_type`, `mutation_type`, `parent_selection_type`, `on_start`, `on_fitness`, `on_parents`, `on_crossover`, `on_mutation`, `on_generation`, and `on_stop`. #92 #138 5. Validating the output of the parent selection, crossover, and mutation functions. 6. The built-in parent selection operators return the parent's indices as a NumPy array. 7. The outputs of the parent selection, crossover, and mutation operators must be NumPy arrays. 8. Fix an issue when `allow_duplicate_genes=True`. #39 9. Fix an issue creating scatter plots of the solutions' fitness. 10. Sampling from a `set()` is no longer supported in Python 3.11. Instead, sampling happens from a `list()`. Thanks `Marco Brenna` for pointing to this issue. 11. The lifecycle is updated to reflect that the new population's fitness is calculated at the end of the lifecycle not at the beginning. #154 (comment) 12. There was an issue when `save_solutions=True` that causes the fitness function to be called for solutions already explored and have their fitness pre-calculated. #160 13. A new instance attribute named `last_generation_elitism_indices` added to hold the indices of the selected elitism. This attribute helps to re-use the fitness of the elitism instead of calling the fitness function. 14. Fewer calls to the `best_solution()` method which in turns saves some calls to the fitness function. 15. Some updates in the documentation to give more details about the `cal_pop_fitness()` method. #79 (comment)
# for free
to join this conversation on GitHub.
Already have an account?
# to comment
Is there a parameter or whatever it is for showing output for every step in process of GA?
The text was updated successfully, but these errors were encountered: