A Jupyter Notebook with the analysis for a Whatsapp Chat using several techniques of data wrangling, EDA and Sentiment Analysis
Data is downloaded as a .txt file from Whatsapp App Without Media and loaded in the Jupyer Notebook
- Chat data is organized into three columns:
- Complete Date
- User
- Message
- A Regex Function is used for several operations and create a Message_Modified column:
- Lowercase the messages
- Delete messages with URL
- Remove numbers
- Remove messages with spaces
- Remove special characters
- Remove repeated letters
- An Emoji column is created to identify all the emojis used in messages
- Complete Date information is used to create the following columns.
- Date [YYYY-MM-DD]
- Month (Name)
- Day (Number 1-31)
- Day (Week Name)
- Hour This is what the final dataset looks like:
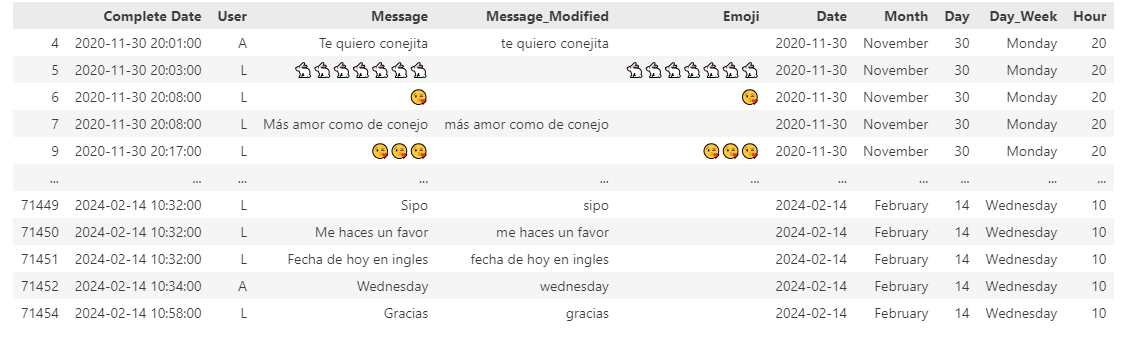
Several questions were answered using the dataset information.
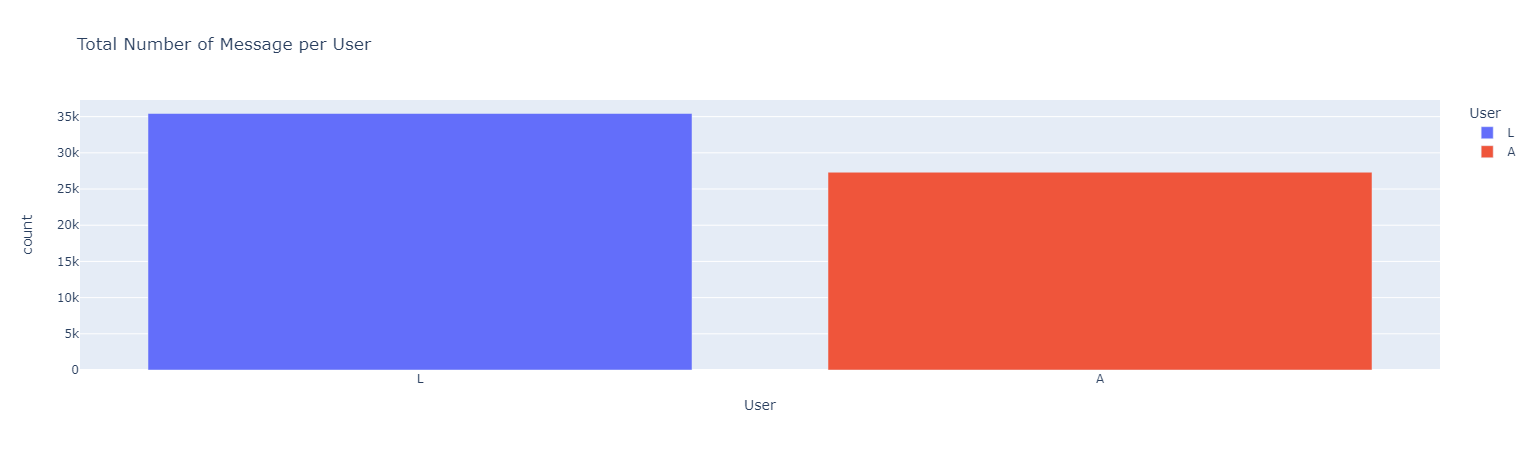
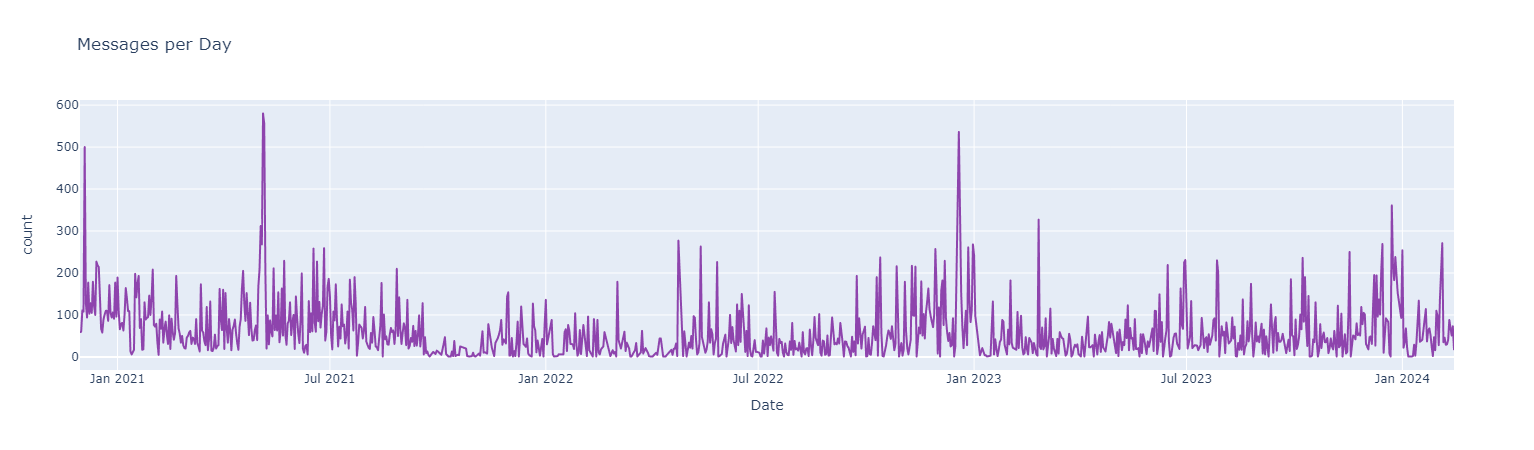
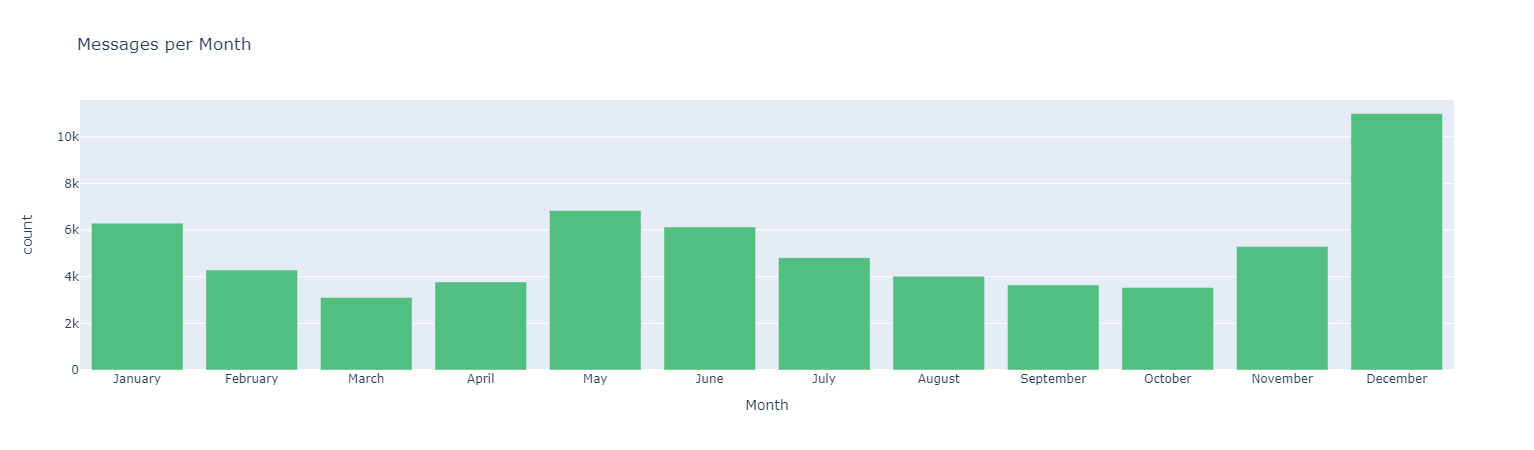
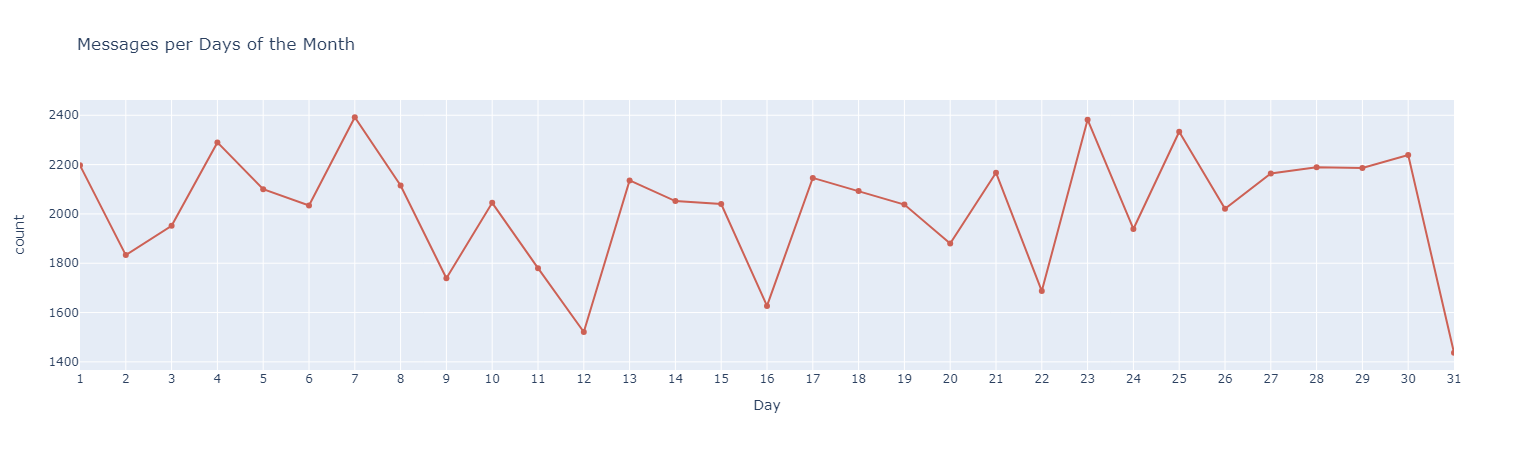
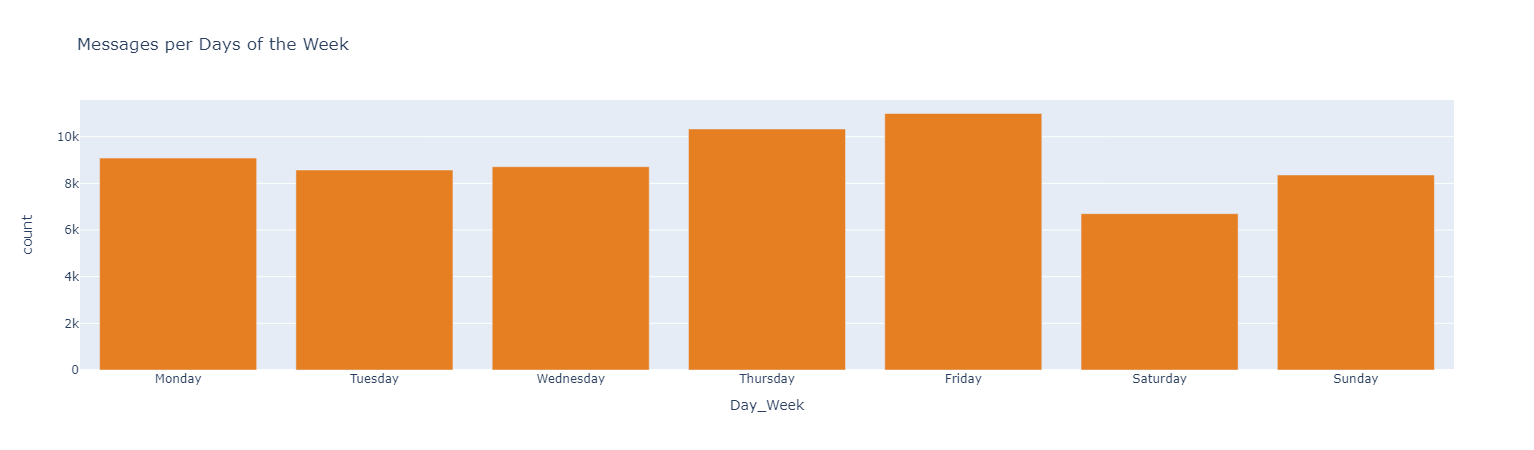
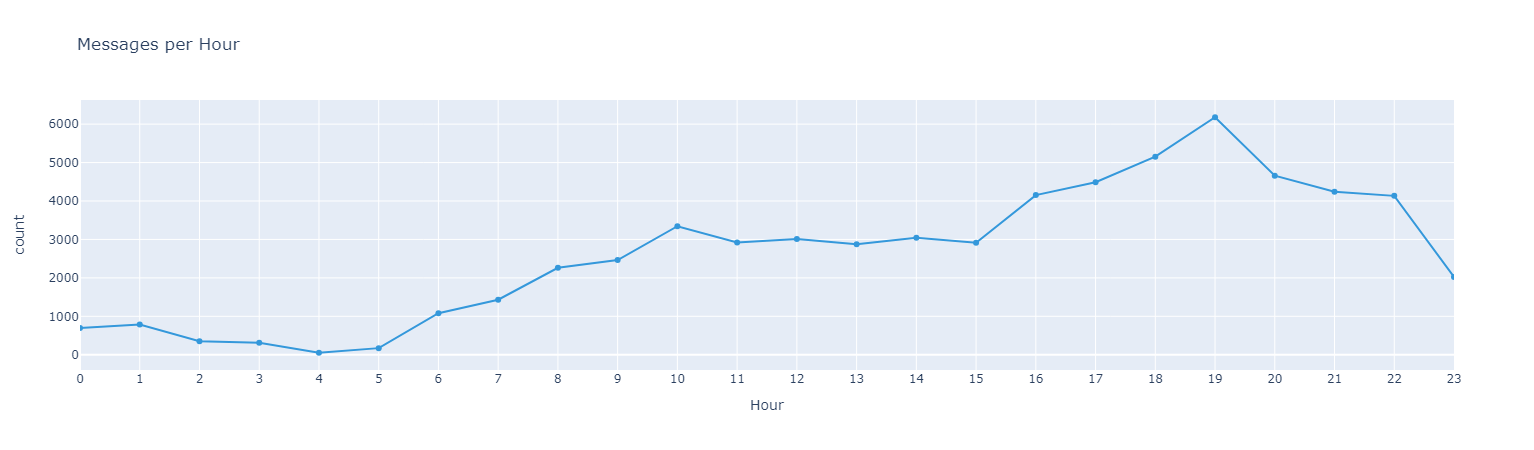
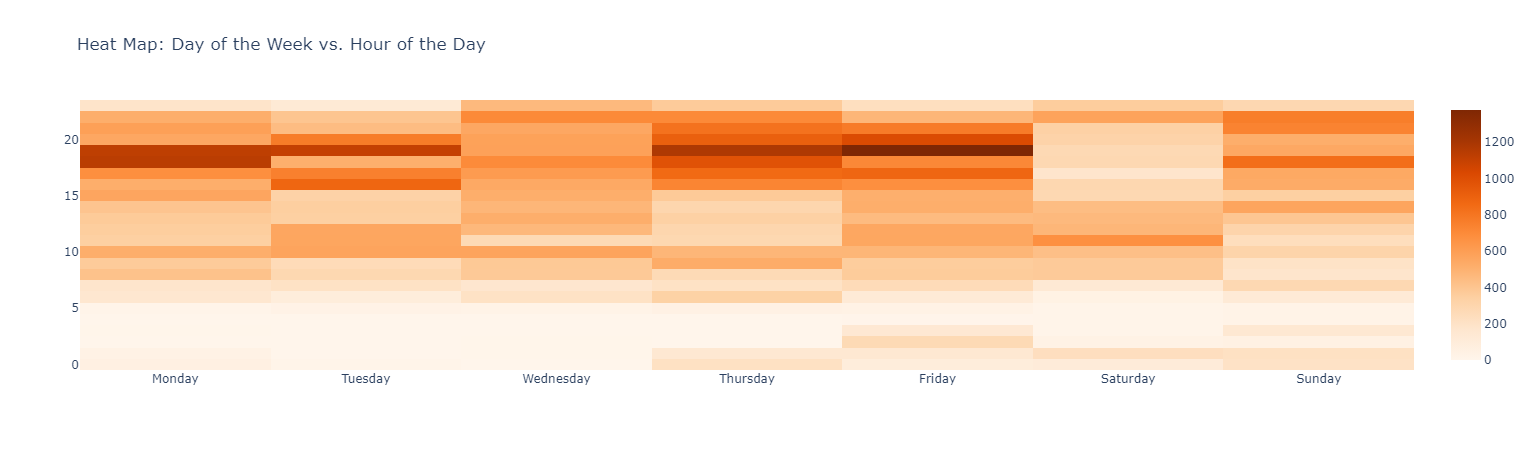
Top Emojis User A
[('😘', 7403), ('🥺', 1058), ('😬', 411), ('🤪', 277), ('❤', 266)]
Top Emojis User L
[('🥺', 1378), ('😘', 1111), ('🥰', 912), ('☺', 622), ('😊', 587)]
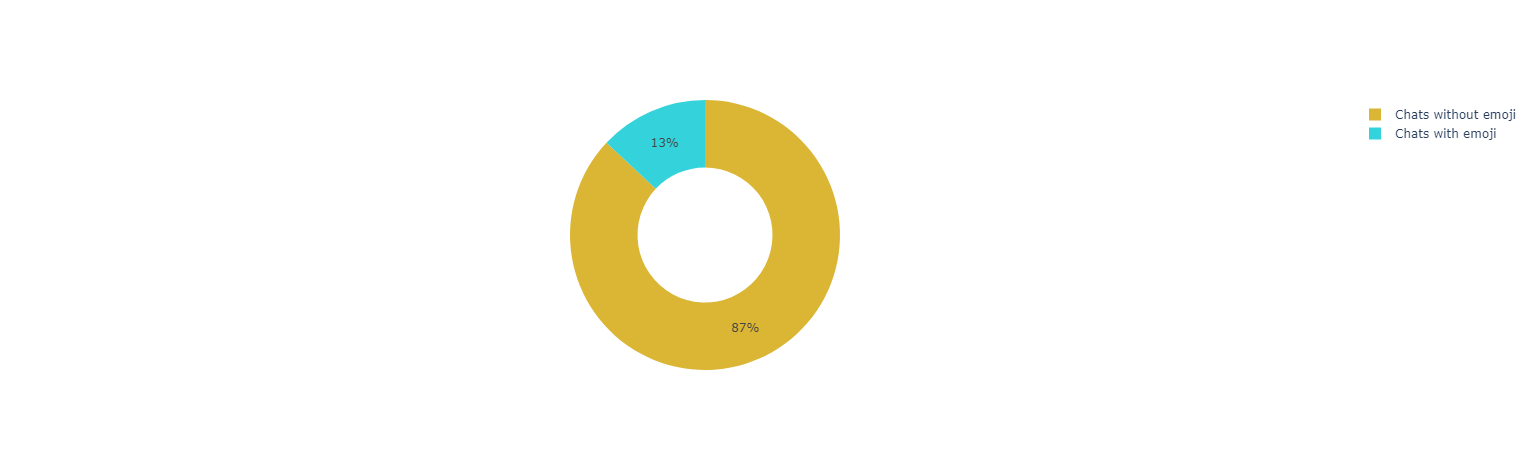
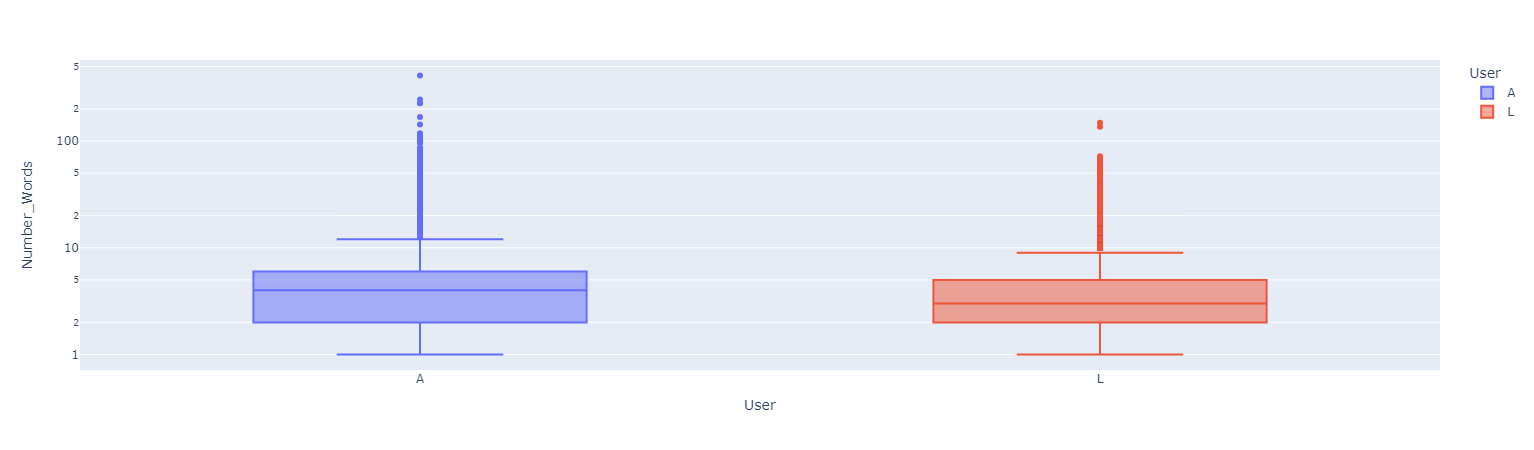
Both Users

Both Users with Spanish Stop Words

A User

L User

Sentiment score {Negative [0 : 0.33] | Neutral [0.33 : 0.66] ! Positive [0.66 : 1]}
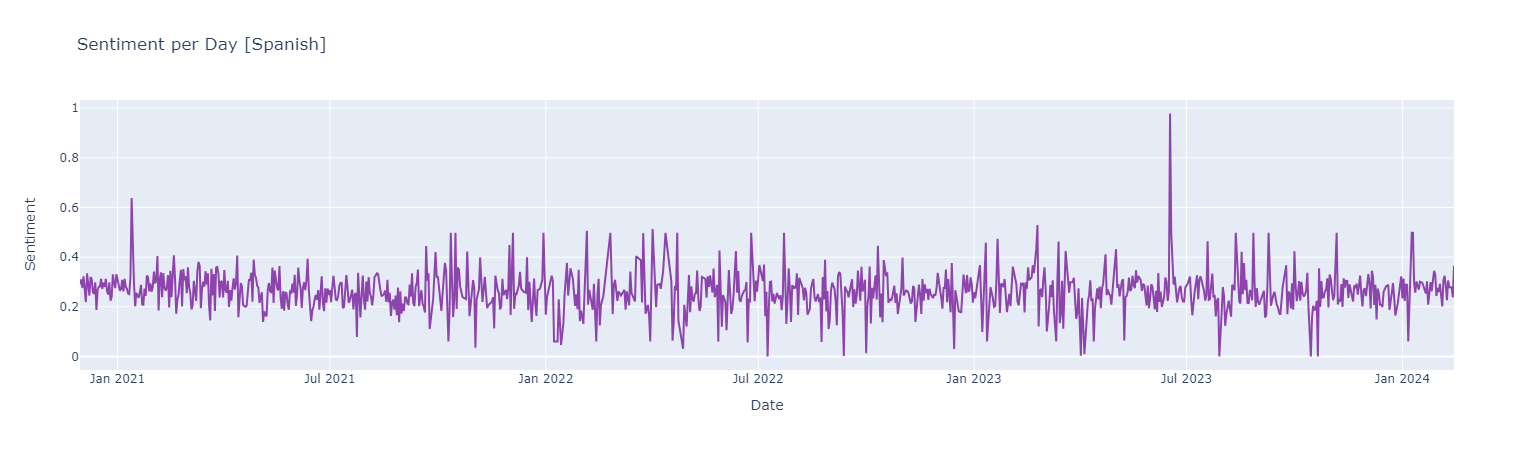
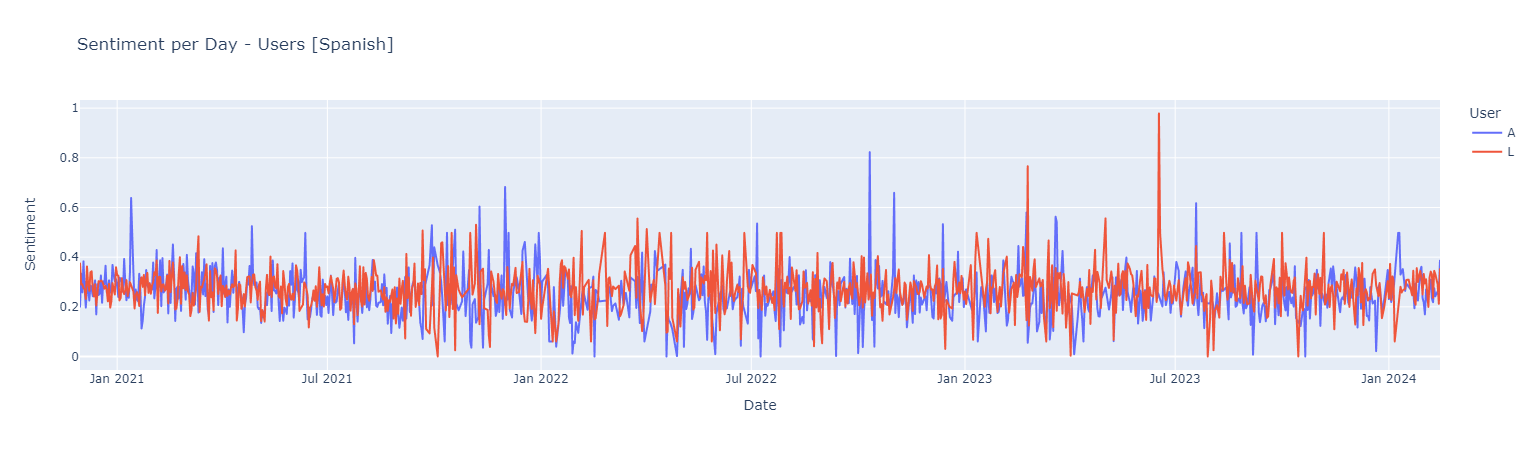
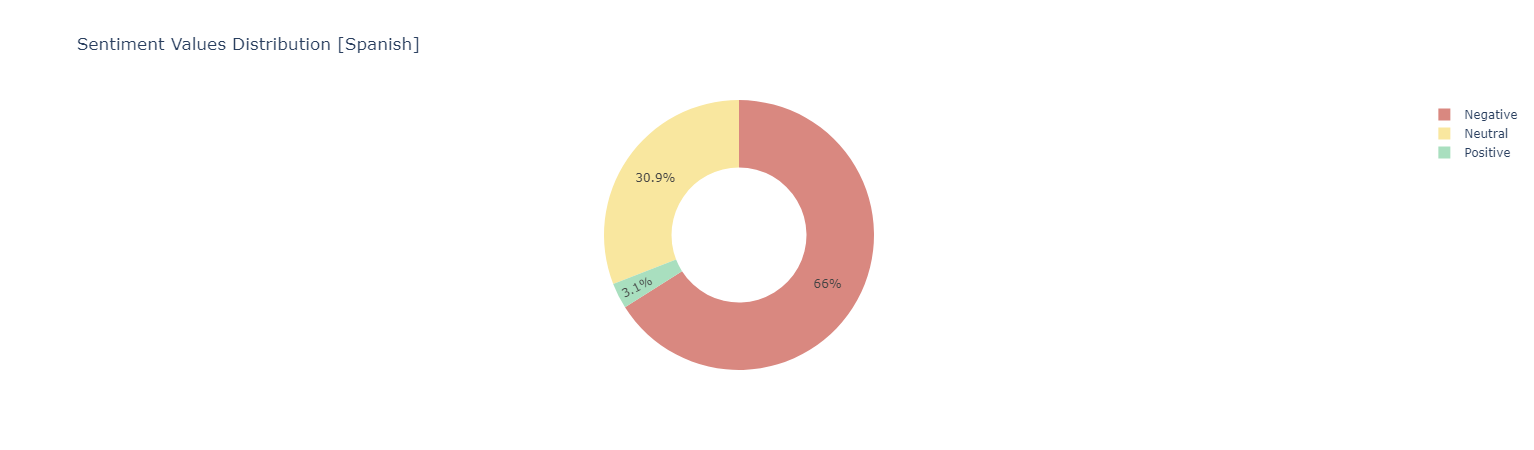
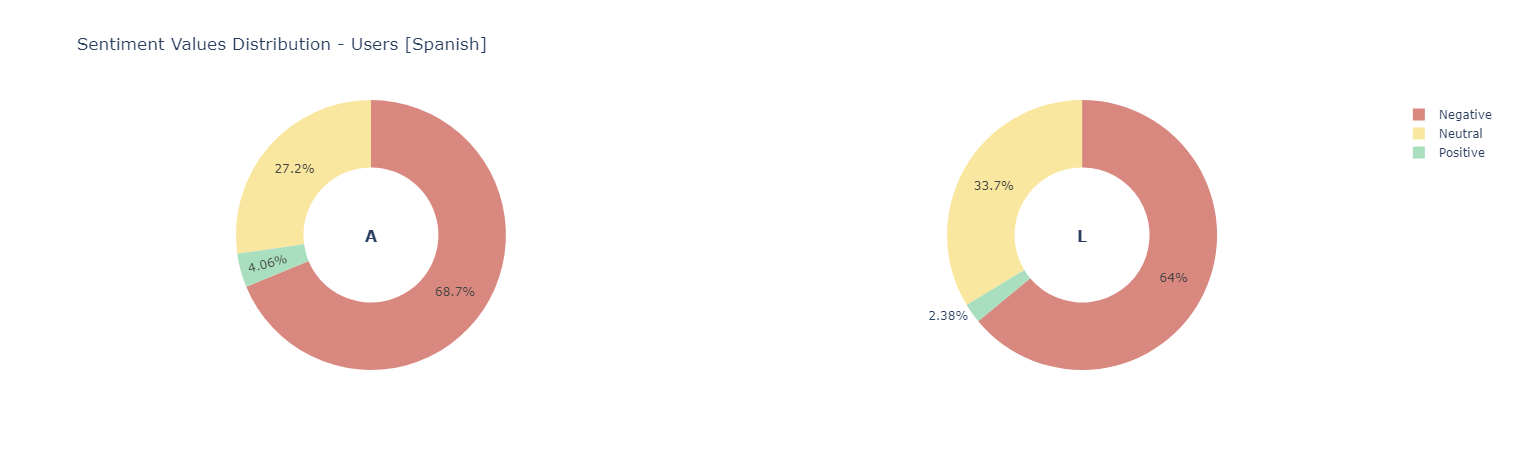
Positive Words

Negative Words

The Spanish Sentiment Analysis didn't get good results. Now we want to try to perform a Sentiment Analysis with the Messages Translations to English
![]()
Sentiment Analysis Using Text Blob
Sentiment score {Negative [-1 : -0.33] | Neutral [-0.33 : 0.33] ! Positive [0.33 : 1]}
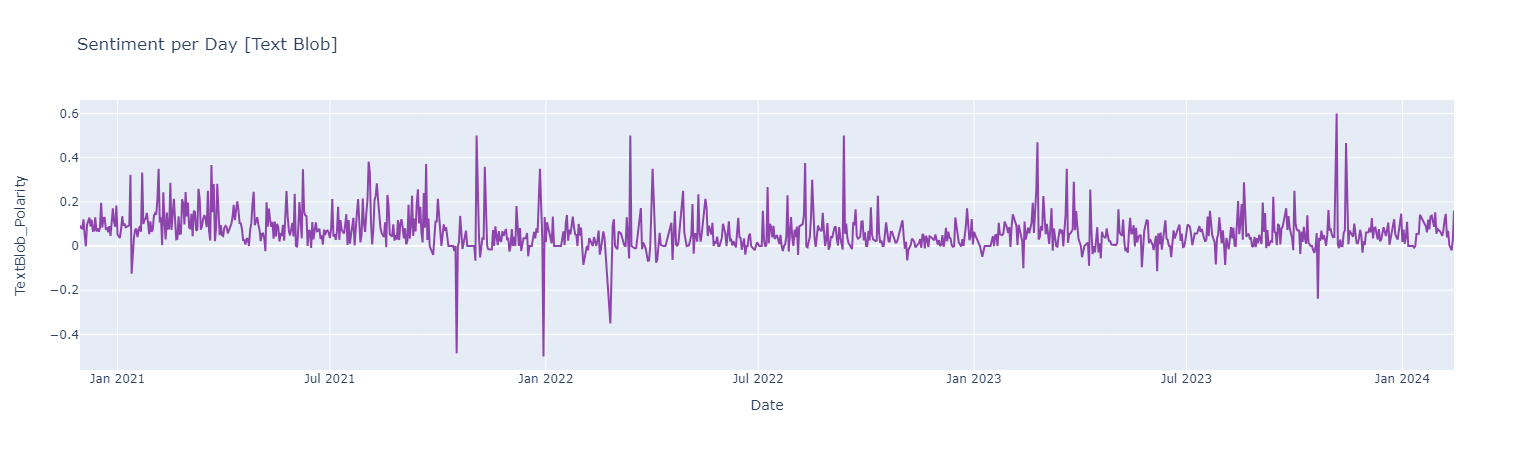
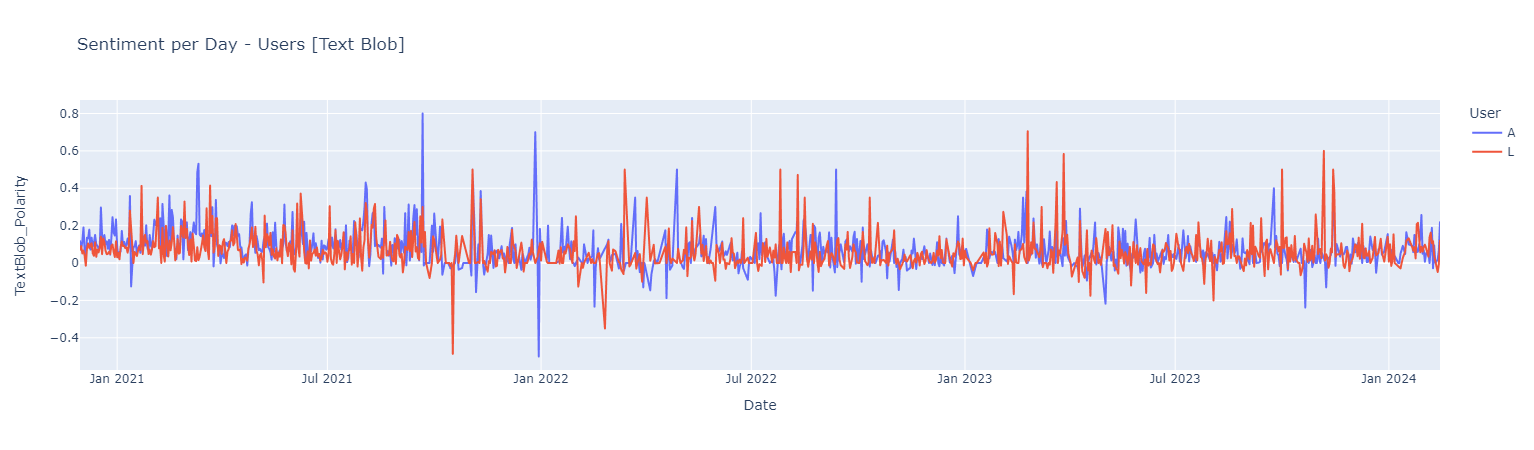
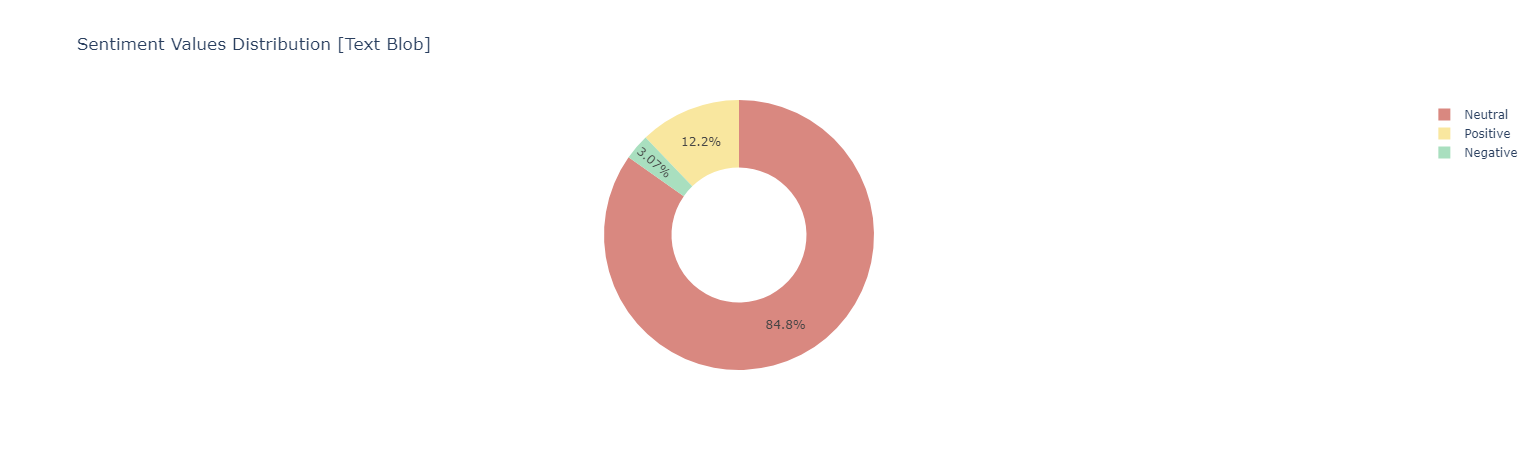

Positive Words

Negative Words

Sentiment Analysis Using NLTK
Sentiment score {Negative [0 : -0.05] | Neutral [-0.05 : 0.05] ! Positive [0.05 : 1]}
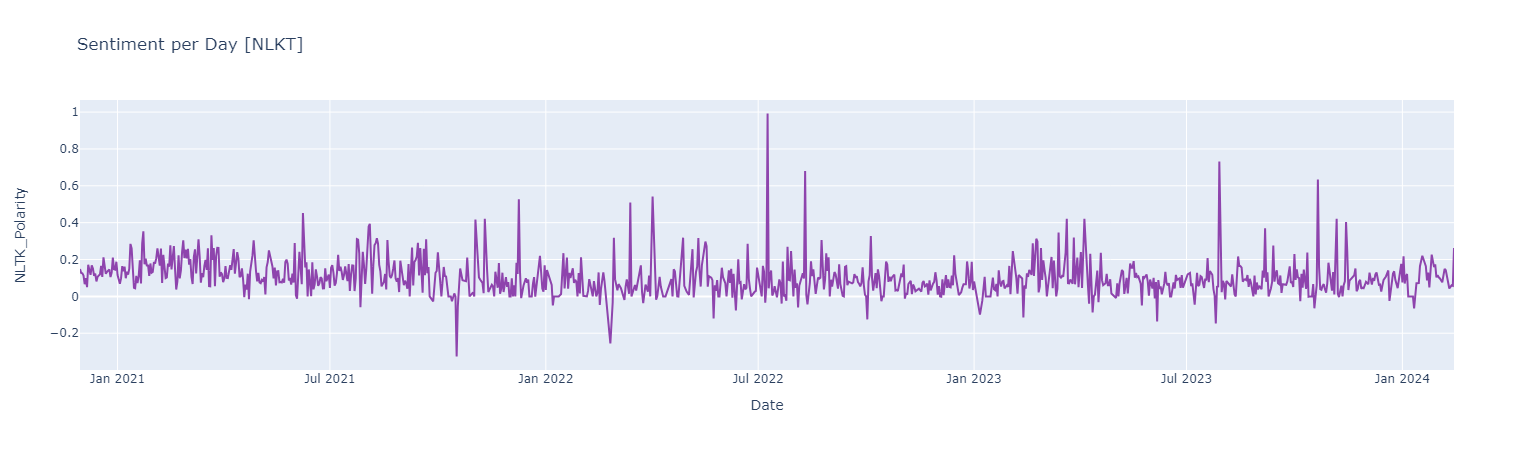
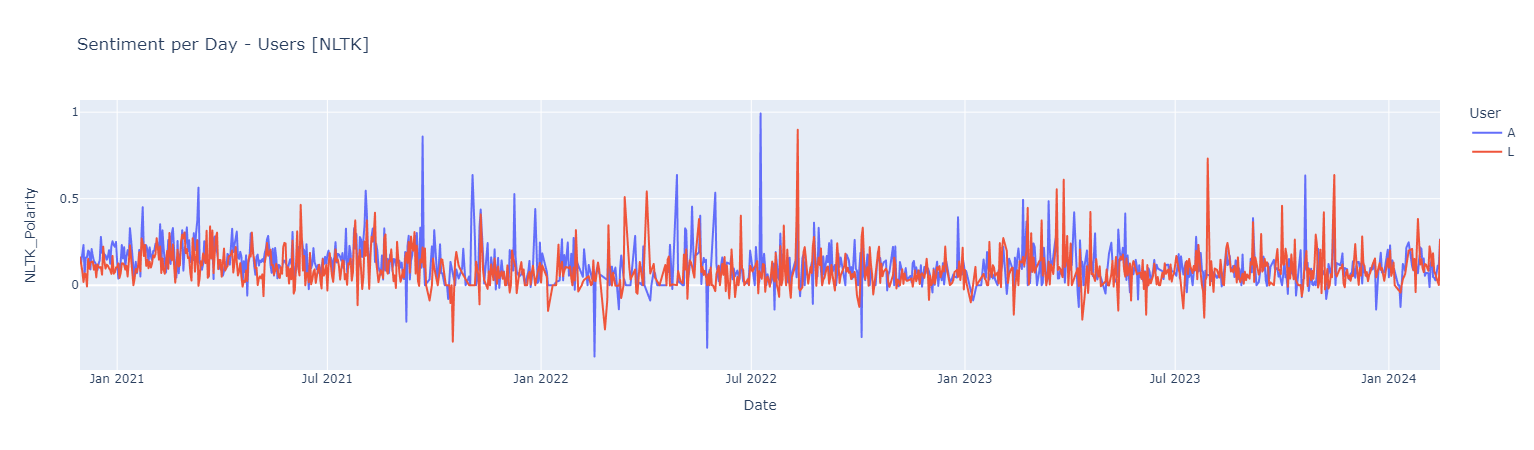
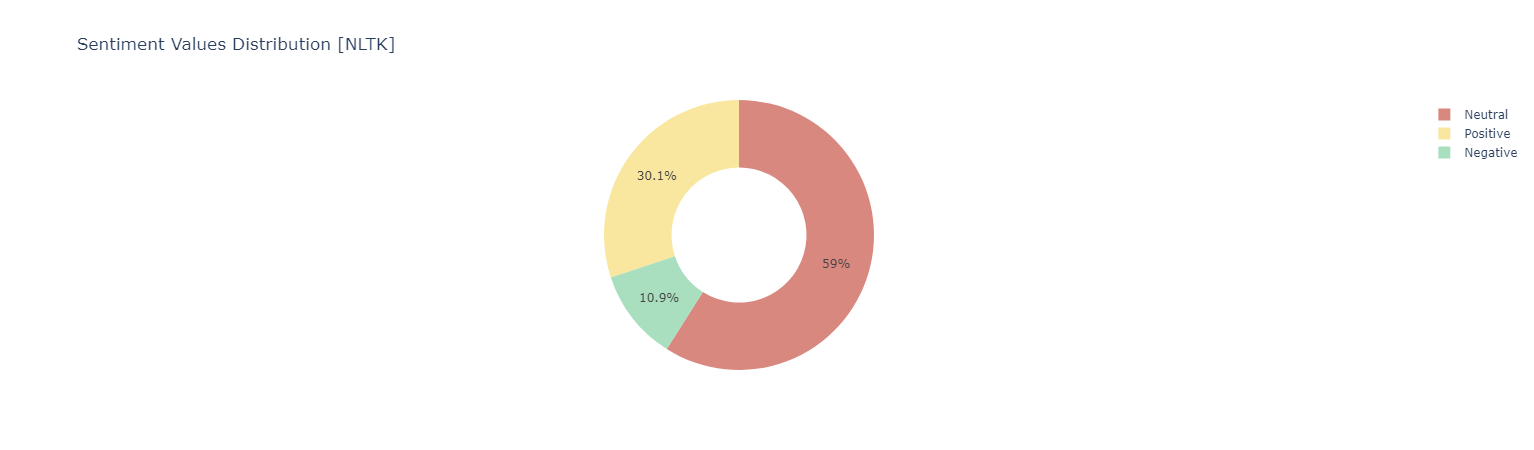

Positive Words
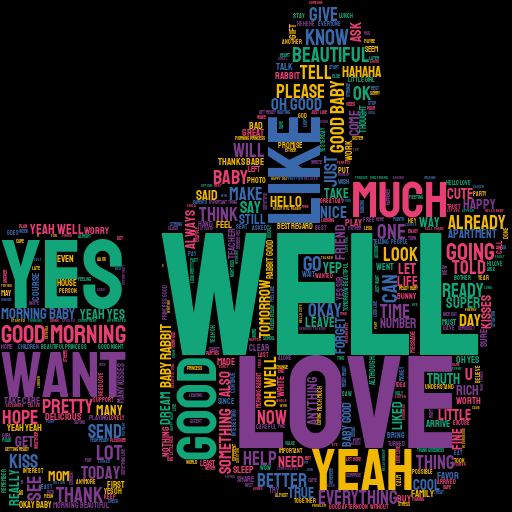
Negative Words
