CVE-Search (name still in alpha), is a Machine Learning tool focused on the detection of exploits or proofs of concept in social networks such as Twitter, Github. It is also capable of doing related searches on Google, Yandex, DuckDuckGo on CVEs and detecting if the content may be a functional exploit, a proof of concept or simply information about the vulnerability.

# Run the application
$ git clone https://github.com/alexfrancow/CVE-Search && cd CVE-Search
$ pip3 install -r requirements.txt
$ docker pull postgres
$ docker run --name some-postgres -e POSTGRES_PASSWORD=1234 -p 5432:5432 -e POSTGRES_DB=cve_search_db -e POSTGRES_USER=alexfranco postgres
$ nano config.ini # PSQL config
$ python3 run.py
# Manual PSQL interaction
$ apt install postgresql-client
$ psql -U alexfranco -h localhost -p 5432 cve_search_db
# Dataset download
$ pip3 install twint
$ pip3 install --user --upgrade git+https://github.com/twintproject/twint.git@origin/master#egg=twint
$ twint -s "cve-" --since 2019-01-01 -o cves-2019-2020.csv --csv --stats --filter-retweets# PSQL table creation
import psycopg2
commands = ('''Create Table IF NOT EXISTS CVES(CVE_id TEXT PRIMARY KEY, Description TEXT, Publised_Date TEXT);''',
'''Create Table IF NOT EXISTS TwitterTweets(Tweet_Id BIGINT PRIMARY KEY,
CVE_id TEXT,
Tweet TEXT,
Datestamp TEXT,
Retweet_Count INT,
Replies_Count INT,
Likes_Count INT,
URLs TEXT,
Username TEXT,
CONSTRAINT fk_cves
FOREIGN KEY(CVE_id)
REFERENCES CVES(CVE_id)
ON DELETE CASCADE);''')
conn = psycopg2.connect(
dbname = "cve_search_db",
user = "alexfranco",
host = "192.168.1.63",
port = 5432,
password = "1234"
)
cursor = conn.cursor()
for command in commands:
print(command)
cursor.execute(command)
conn.commit()
cursor.close()
conn.close()
⚠️ At the moment this algorithm is not being used due to false positives and low precision.
In the same way that the binary classification (binary classification) implies predicting if something is of one of two classes (for example, "black" or "white", "dead" or "alive", etc.), multiclass problems (Multi -class classification) involve classifying something into one of the N classes (for example, "red", "White" or "blue", etc.)
Common examples include the classification of images (it is a cat, dog, human, etc.) or the recognition of handwritten digits (classifying an image of a handwritten number into a digit from 0 to 9). The scikit learn library offers a series of algorithms for Multi-Class classification, some such as:
K-nearest-neighbours (KNN).
Random Forest
With these algorithms based on features like the: Number of likes/rts/replies, tweet length, urls, photos, videos, hashtags we can predict which tweet contains an Exploit or PoC.

Text classification is the task of assigning one or more categories to a given piece of text from a larger set of possible categories. In the email spam–identifier example, we have two categories—spam and non-spam—and each incoming email is assigned to one of these categories. This task of categorizing texts based on some properties has a wide range of applications across diverse domains, such as social media, e-commerce, healthcare, law, and marketing, to name a few. Even though the purpose and application of text classification may vary from domain to domain, the underlying abstract problem remains the same. This invariance of the core problem and its applications in a myriad of domains makes text classification by far the most widely used NLP task in industry and the most researched in academia. The pipeline that has been used is the following:

I've used multinominalNB instead of logistic regression
Using the MultinomialNB algorithm we obtained a precision score of 0.77, here is the confusion matrix (1 - exploit, 0 - non-exploit).

Naive Bayes methods are a set of supervised learning algorithms based on applying Bayes’ theorem with the “naive” assumption of conditional independence between every pair of features given the value of the class variable.

https://www.mygreatlearning.com/blog/multinomial-naive-bayes-explained/
This is the dataset used to train the algorithms, as you can see, a supervised dataset has been used, that is, the tweet has been checked and it has been manually marked if it was an exploit.
id exploit tweet
X 0 YOU GUYS. https://t.co/k03JDnECK9
X 0 Apache releases an update to patch a potential remote code execution #vulnerability (CVE-2020-17530) affecting Apache Struts 2.0.0 - 2.5.25. Read more: https://t.co/fQeH2h8ODX https://t.co/7q9U9DwrF8
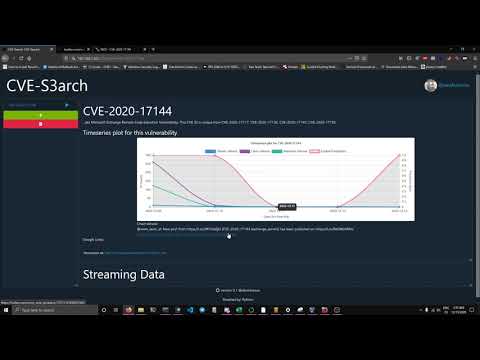
X 1 GitHub - Airboi/CVE-2020-17144-EXP: Exchange2010 authorized RCE - https://t.co/LwJhryuUSo
X 0 Well. Vasilis took his first unassisted step tonight. He also clearly demonstrated he knows how doors work AND learned how to escape the family room baby blockade we made to contain him by watching Hercules do it.........So. Basically my life is over. 😂 https://t.co/xwhWwSQPK6
NLP (Natural Language Processing) to detect exploits on Twitter based on text classification
Natural Language Processing, usually shortened as NLP, is a branch of artificial intelligence that deals with the interaction between computers and humans using the natural language.
The ultimate objective of NLP is to read, decipher, understand, and make sense of the human languages in a manner that is valuable. Most NLP techniques rely on machine learning to derive meaning from human languages.
With NLP we can classify web pages into "Just Information Page" or "Exploit Page!".


Could not find the Guest token in HTML
pip3 uninstall twint
pip3 install --user --upgrade git+https://github.com/twintproject/twint.git@origin/master#egg=twint