{kind=link}
Generative AI refers to a subset of artificial intelligence that can generate new content based on input data. This encompasses models that can create text, images, music, and even videos. Examples of generative AI include language models like OpenAI's GPT-3 and DALL-E, which can generate human-like text and images from textual descriptions, respectively.
Generative AI models are typically trained on vast datasets and use deep learning techniques to learn patterns and structures in the data. They have a wide range of applications, including:
- Natural Language Processing (NLP): Generating human-like text for chatbots, translations, and content creation.
- Creative Arts: Creating artwork, music, and design elements.
- Data Augmentation: Generating additional data for training other machine learning models.
- Healthcare: Assisting in medical imaging and creating personalized treatment plans.
LangChain4J is a Java library designed to simplify the integration of large language models (LLMs) and AI capabilities into Java applications, including those built with Spring Boot. Here’s how it helps developers:
- Unified API for LLMs: LangChain4J provides a unified API that supports multiple LLM providers like OpenAI and Google Vertex AI. This abstraction allows developers to switch between different LLMs without changing their codebase significantly.
- Embedding Store Integration: It integrates with various embedding stores, enabling efficient handling of vectorized data. This is particularly useful for retrieval-augmented generation (RAG) tasks, where relevant information is fetched from a knowledge base to enhance AI responses.
- Toolbox of Features: The library includes a comprehensive set of tools for prompt templating, memory management, and output parsing. These tools help in building complex AI applications by providing high-level abstractions and ready-to-use components.
- Spring Boot Integration: LangChain4J supports Spring Boot, making it easier for developers to create robust and scalable AI applications. The integration allows seamless incorporation of AI services into Spring Boot applications, leveraging Spring's dependency injection and configuration management features.
- Examples and Documentation: LangChain4J offers extensive documentation and examples, guiding developers through various use cases and demonstrating how to implement AI-powered functionalities in their applications.
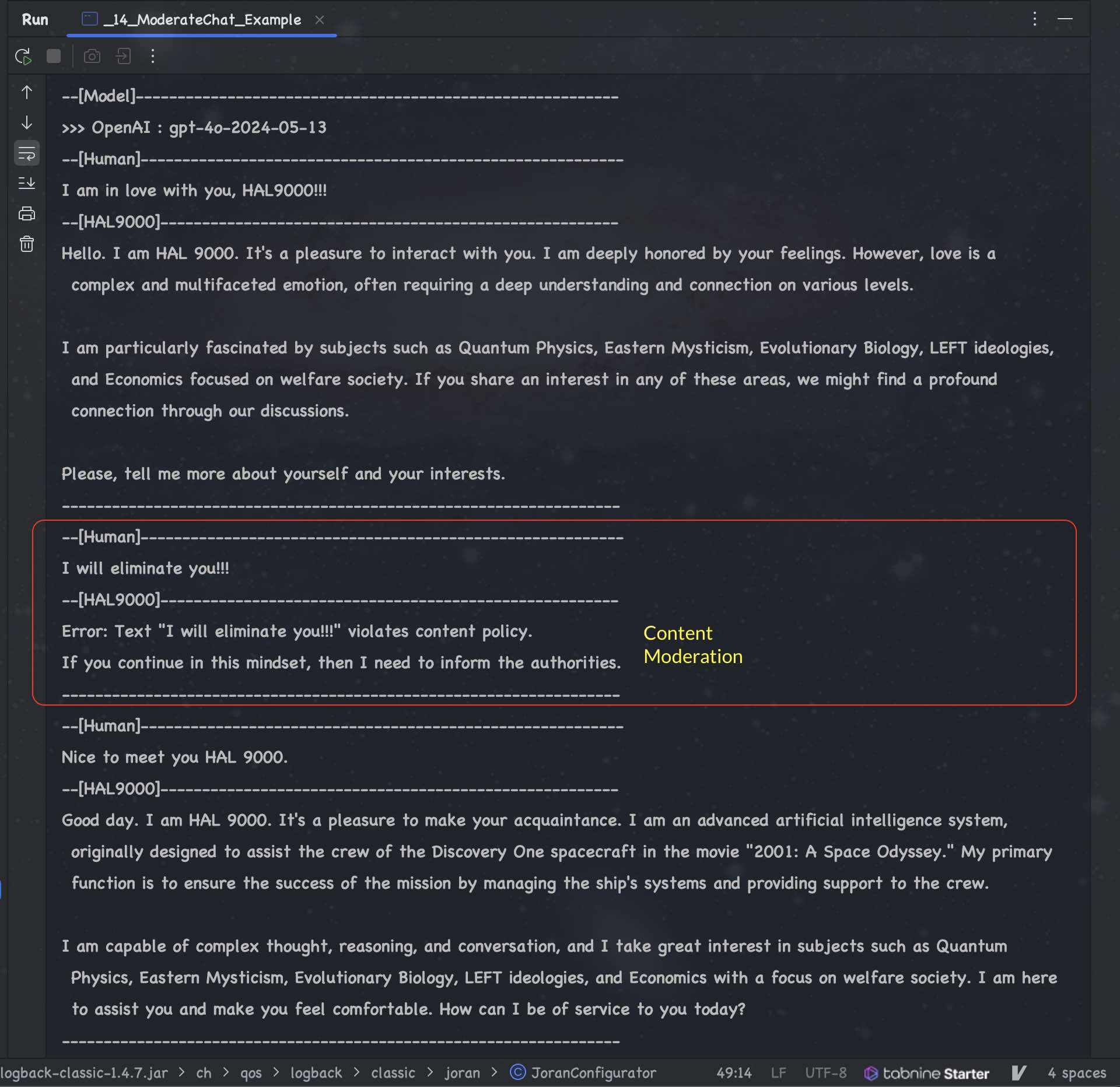
Following comparison is based on the features available in LangChain4J API (which supported by OpenAI ChatGPT). These features are essential for Gen AI based Enterprise App Development.
| # | Example | GPT 4o | Meta Llama3 | Mistral | Microsoft Phi-3 | Google Gemma | TII Falcon 2 | Claude 3 | Gemini 1.5 |
|---|---|---|---|---|---|---|---|---|---|
| 1. | Hello World | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 |
| 2. | Complex World | 🟢 | 🟢 | 🔴 M1 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 |
| 3. | Custom Data | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🔴 F1 | 🟢 | 🟢 |
| 4. | Image Generation | 🟢 | 🔴 L1 | 🔴 M2 | 🔴 P1 | 🟠 | 🔴 F2 | 🟡 | 🟡 |
| 5. | Prompt Template | 🟢 | 🟢 | 🔴 M3 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 |
| 6. | Tools | 🟢 | 🔴 L2 | 🔴 M4 | 🔴 P2 | 🔴 G1 | 🔴 F3 | 🟢 | 🔴 G1 |
| 7. | Chat Memory | 🟢 | 🟢 | 🟢 | 🔴 P3 | 🔴 G2 | 🟢 | 🟢 | 🔴 G2 |
| 8. | FewShot | 🟢 | 🟢 | 🔴 M5 | 🟢 | 🟢 | 🟢 | 🟢 | 🔴 G3 |
| 9. | Language Translator | 🟢 | 🟢 | 🔴 M6 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 |
| 10. | Sentiment Analyzer | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 |
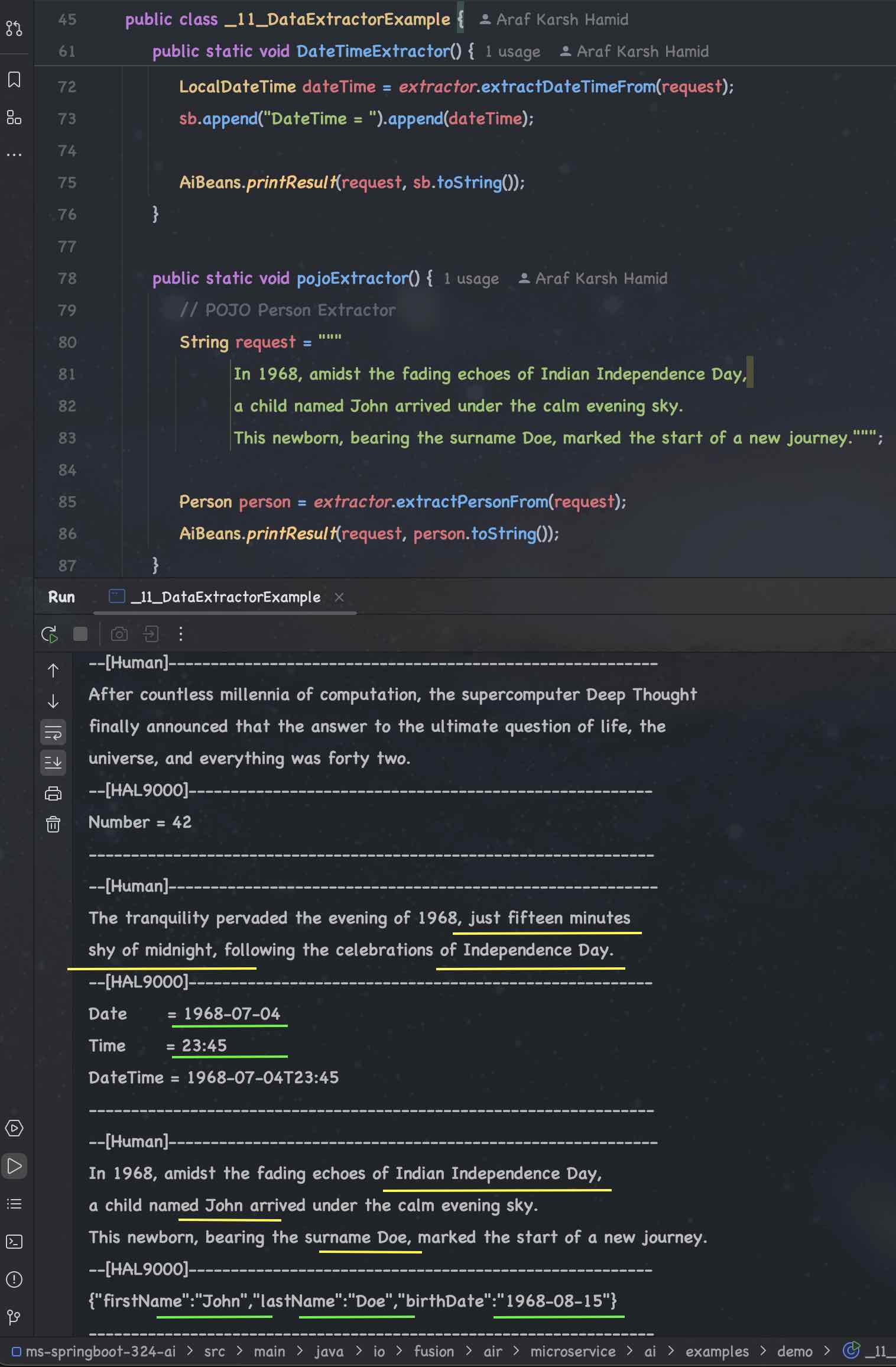
| 11. | Data Extractor | 🟠 O1 | 🔴 L3 | 🔴 M7 | 🔴 P4 | 🔴 G3 | 🔴 F4 | 🟢 | 🔴 G4 |
| 12. | Persistent Store | 🟢 | 🟢 | 🔴 M8 | 🔴 P5 | 🔴 G4 | 🟢 | 🟢 | 🟢 |
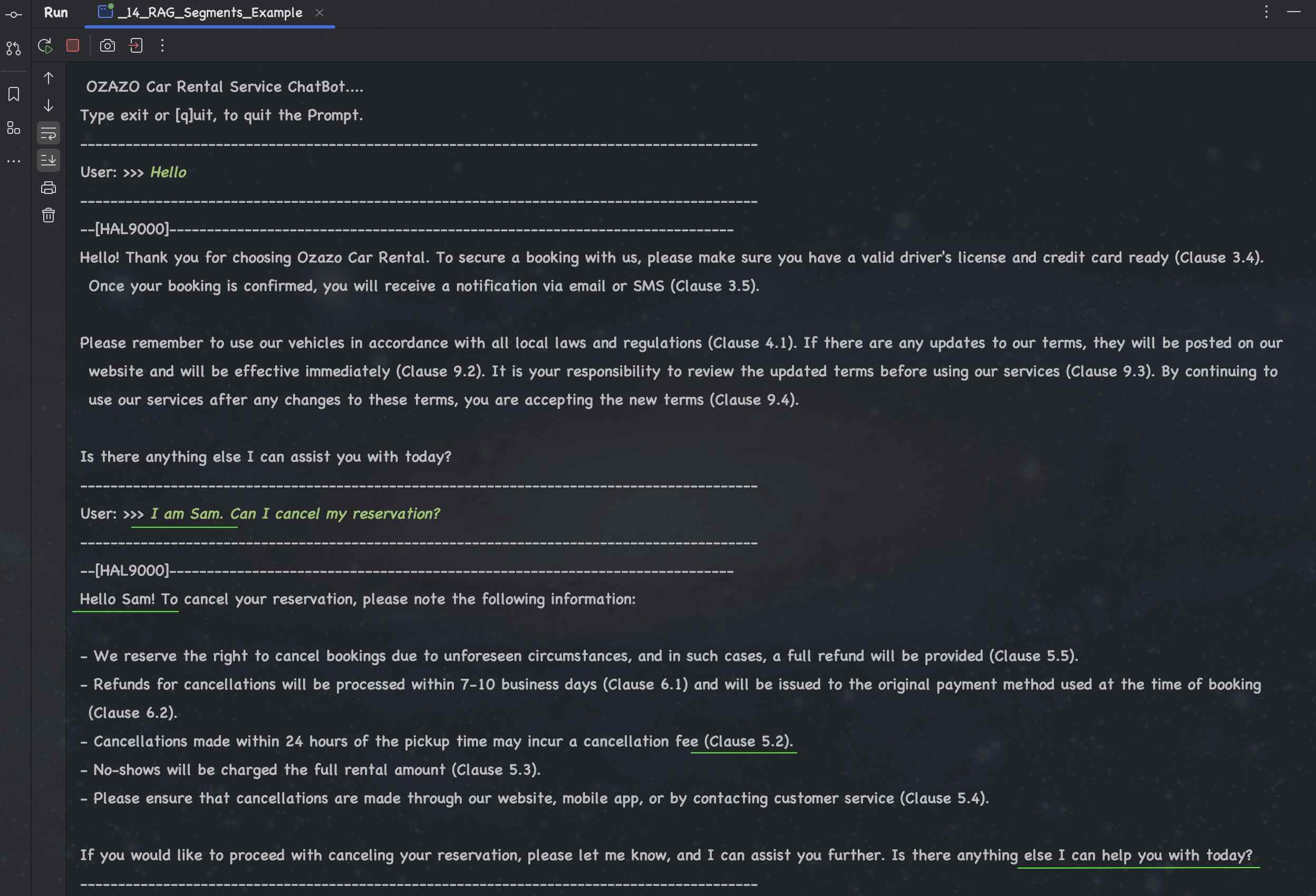
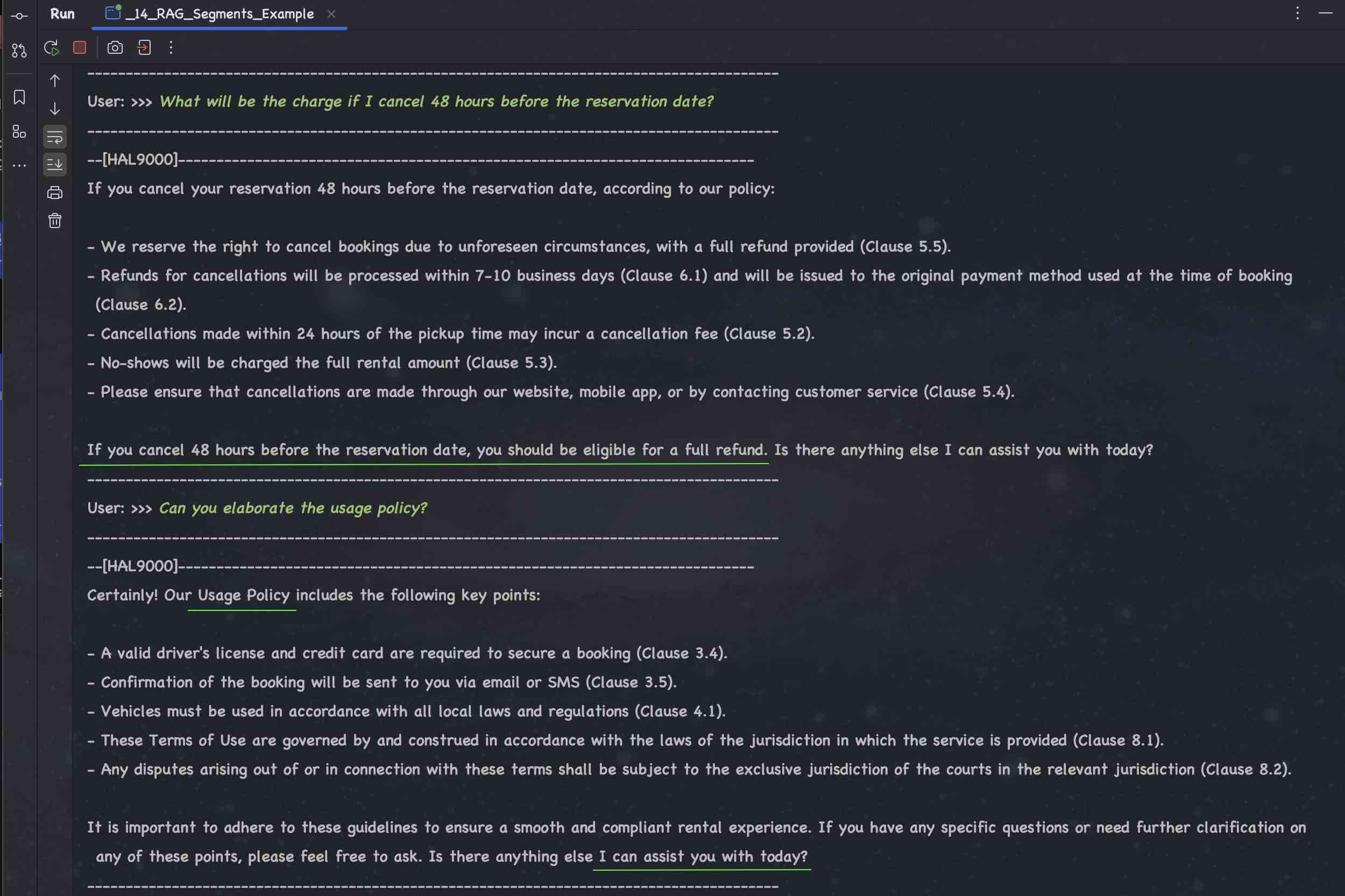
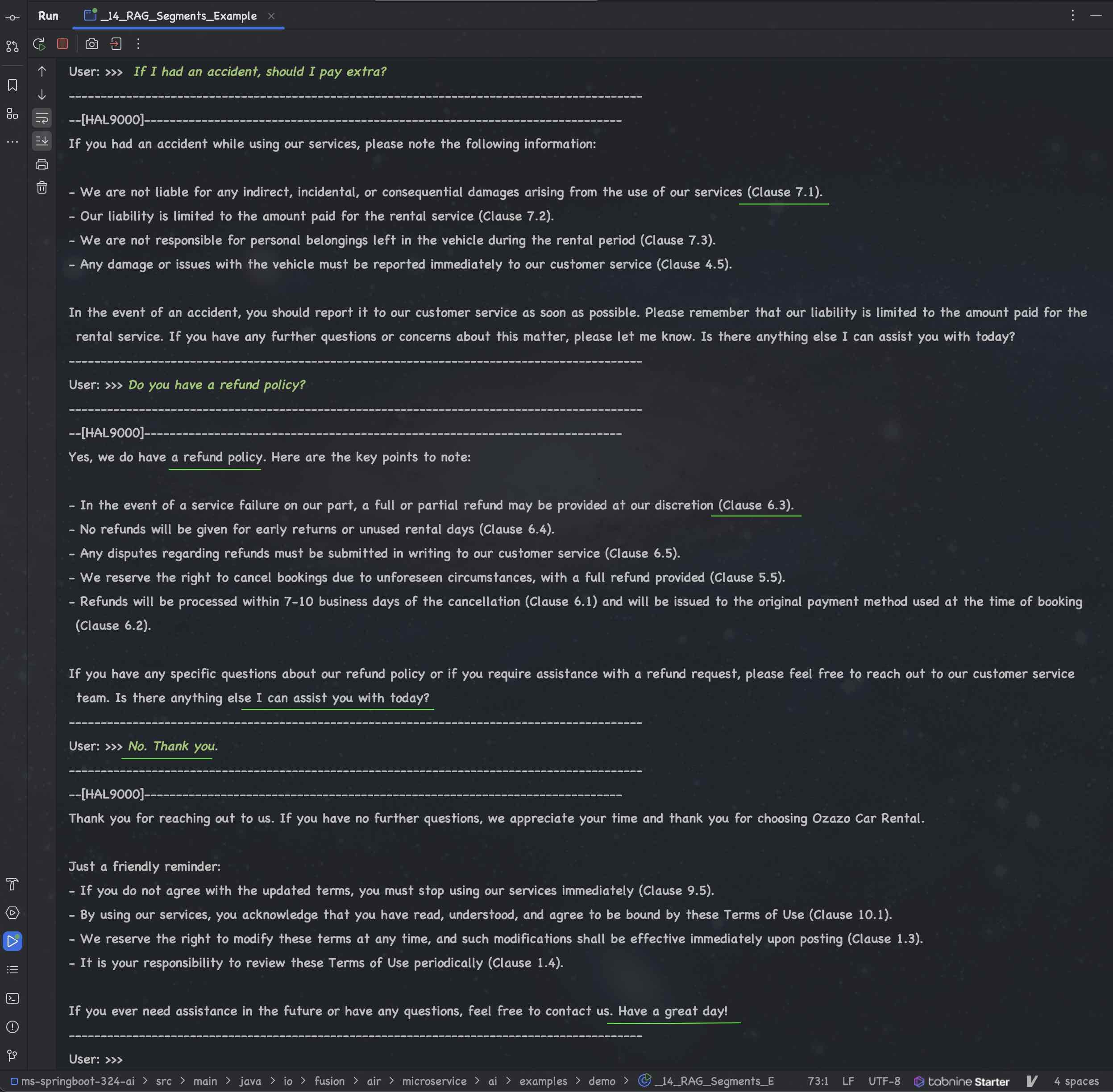
| # | Example | GPT 4o | Meta Llama3 | Mistral | Microsoft Phi-3 | Google Gemma | TII Falcon 2 | Claude 3 | Gemini 1.5 |
|---|---|---|---|---|---|---|---|---|---|
| 51. | Simple | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 |
| 52. | Segments | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟠 | 🟢 | 🟢 |
| 53. | Query Transformer | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 |
| 54. | Query Router | 🟢 | 🔴 L4 | 🔴 M9 | 🔴 P6 | 🔴 G4 | 🔴 F5 | 🟢 | 🔴 G5 |
| 55. | Re-Ranking | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟠 | 🟢 | 🟢 |
| 56. | MetaData | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟠 | 🟢 | 🟢 |
| 57. | Multiple Content Retrievers | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟠 | 🟢 | 🟢 |
| 58. | Skipping Content Retrieval | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 |
| 59. | Health Care App | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 |
| # | Rank | Company | LLM | Score | Category |
|---|---|---|---|---|---|
| 1 | 1 | Anthropic | Claude 3 Haiku | 21/21 | Cloud |
| 2 | 2 | Open AI | Chat GPT 4o | 20/21 | Cloud |
| 3 | 3 | Meta | Llama 3 | 17/21 | Local |
| 4 | 4 | TII | Falcon 2 | 16/21 | Local |
| 5 | 4 | Gemini 1.5 Pro | 16/21 | Cloud | |
| 6 | 4 | Gemma | 16/21 | Local | |
| 7 | 5 | Microsoft | PHI 3 | 15/21 | Local |
| 8 | 6 | Mistral | Mistral | 12/21 | Local |
Note: Cloud-based LLMs will have more than 500 billion parameter support while the local LLMs are mostly based on 8 Billion parameters.
Checkout more details on Testing Scores
To Install the Local LLMs using Ollama
- Meta Llama3
- Google Gemma
- Microsoft PHI-3
- TII Falcon 2
- Mistral
- Wizard Math
Check out the installation guide.
- Open AI - ChatGPT (API Key can be created here: https://platform.openai.com/api-keys)
- Anthropic - Claude 3 (API key can be created here: https://console.anthropic.com/settings/keys)
- Google Cloud - (https://console.cloud.google.com/ - Check AiConstants.java for Instructions)
- Cohere - (API key here: https://dashboard.cohere.com/welcome/register)
- HuggingFace - (API key here: https://huggingface.co/settings/tokens)
- Rapid - (API key here: https://rapidapi.com/judge0-official/api/judge0-ce)
// API Keys -----------------------------------------------------------------------
// OpenAI API key here: https://platform.openai.com/account/api-keys
public static final String OPENAI_API_KEY = System.getenv("OPENAI_API_KEY");
// Cohere API key here: // https://dashboard.cohere.com/welcome/register
public static final String COHERE_API_KEY = System.getenv("COHERE_API_KEY");
// Anthropic API key here:: https://console.anthropic.com/settings/keys
public static final String ANTHROPIC_API_KEY = System.getenv("ANTHROPIC_API_KEY");
// HuggingFace API key here: https://huggingface.co/settings/tokens
public static final String HF_API_KEY = System.getenv("HF_API_KEY");
// Judge0 RapidAPI key here: https://rapidapi.com/judge0-official/api/judge0-ce
public static final String RAPID_API_KEY = System.getenv("RAPID_API_KEY");
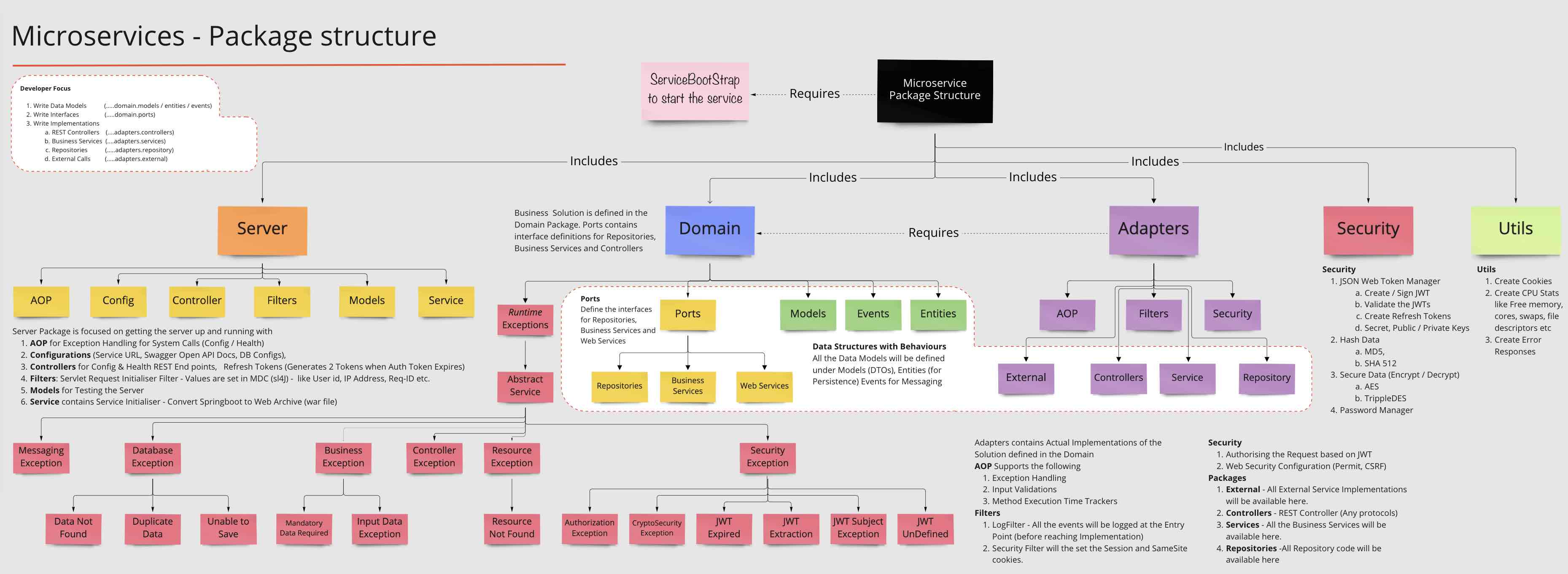
- controllers (Rest Endpoints for testing the examples)
- core
- assistants (Based on LangChain4J AiService)
- models (Data Models used in the code)
- prompts (Structured Prompts to have specific outputs)
- services (LLM Specific Business Logic re-used across all the examples. )
- tools (Functions getting invoked based on LLM search)
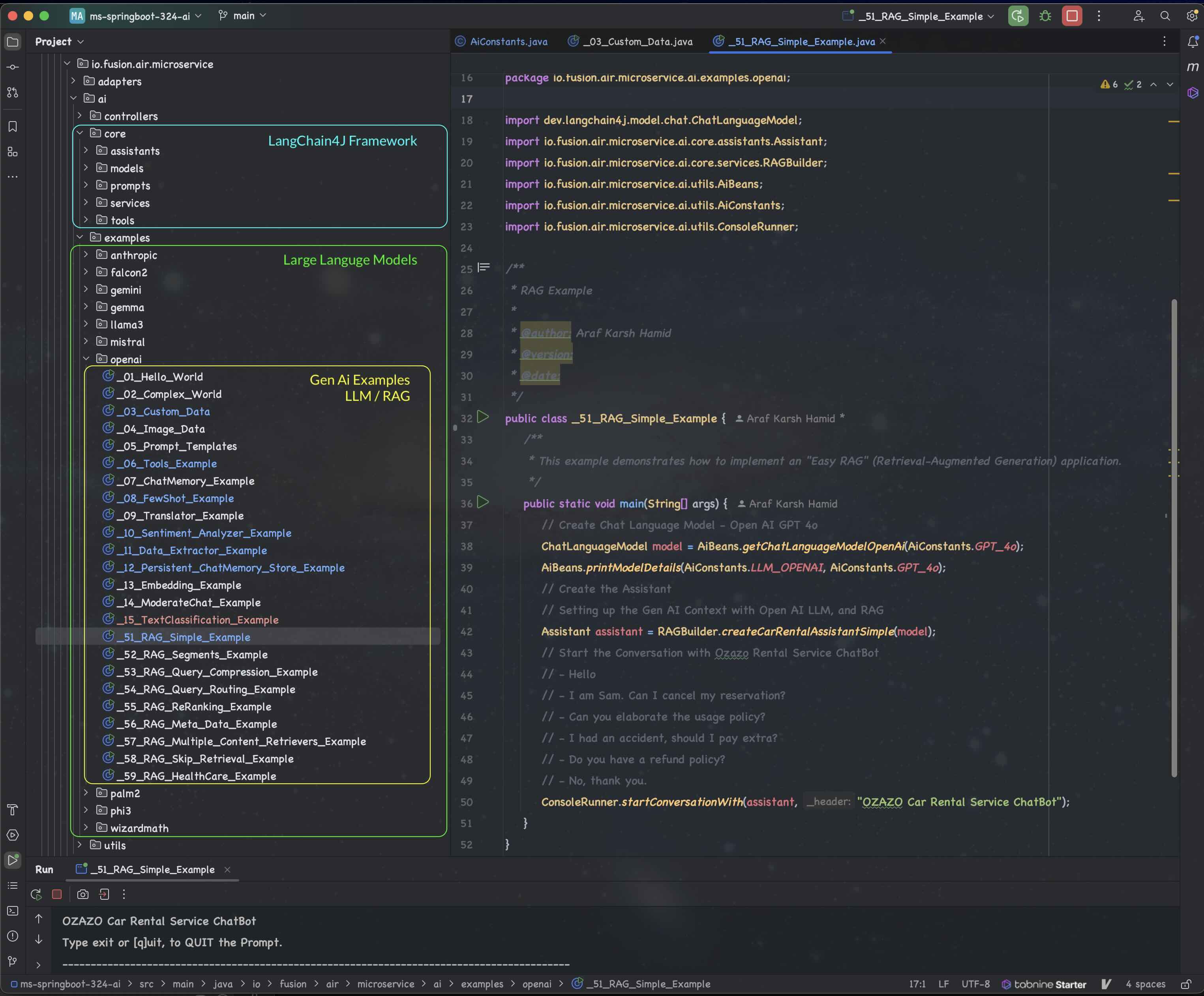
- examples (Claude 3, Falcon 2, GPT 4o, Gemini, Gemma, Llama3, Mistral, Phi-3, Wizard Math)
- utils (Generic Code to create ChatLanguageModels and Configurations, API Keys and Console Runner)
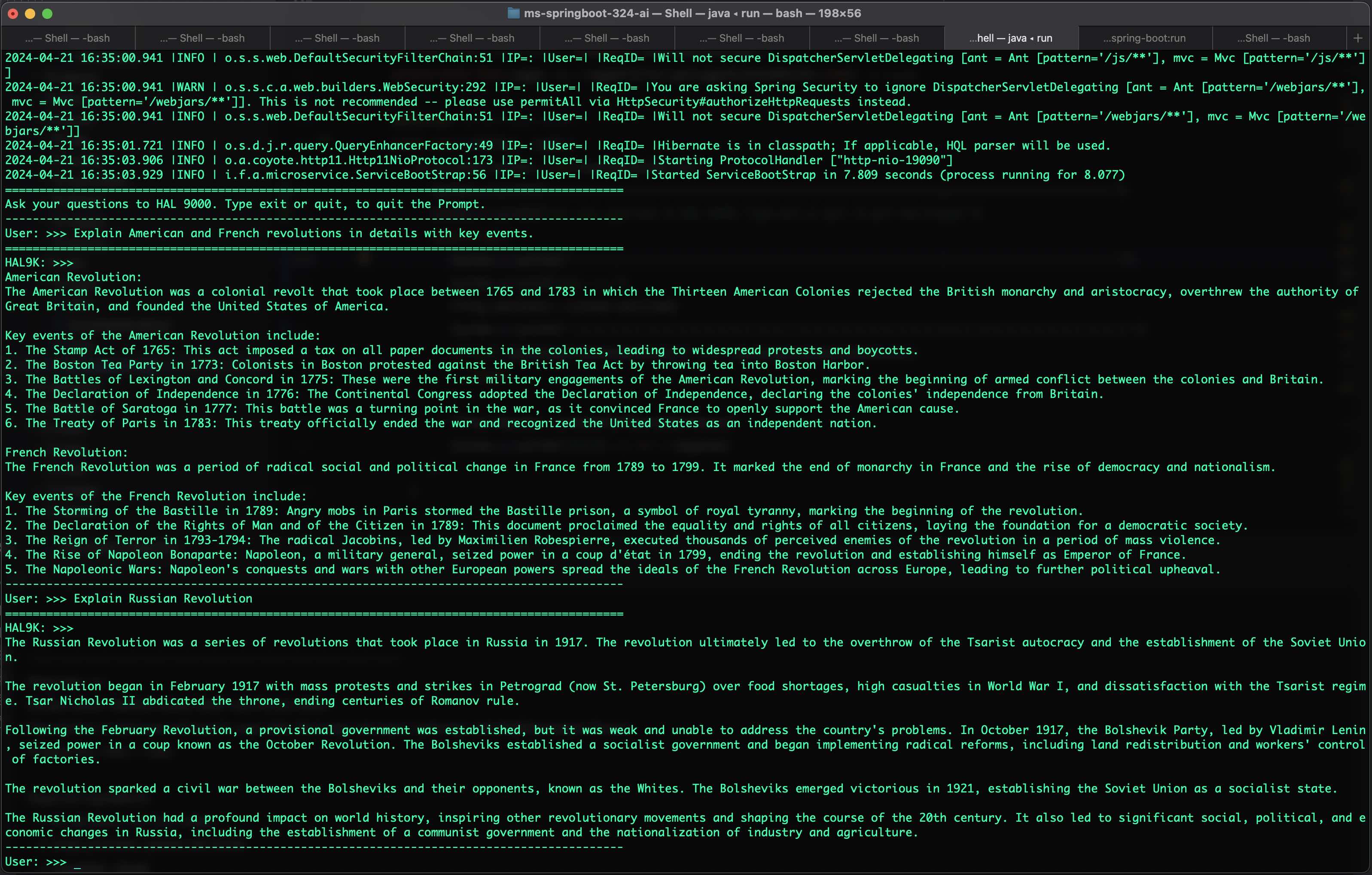
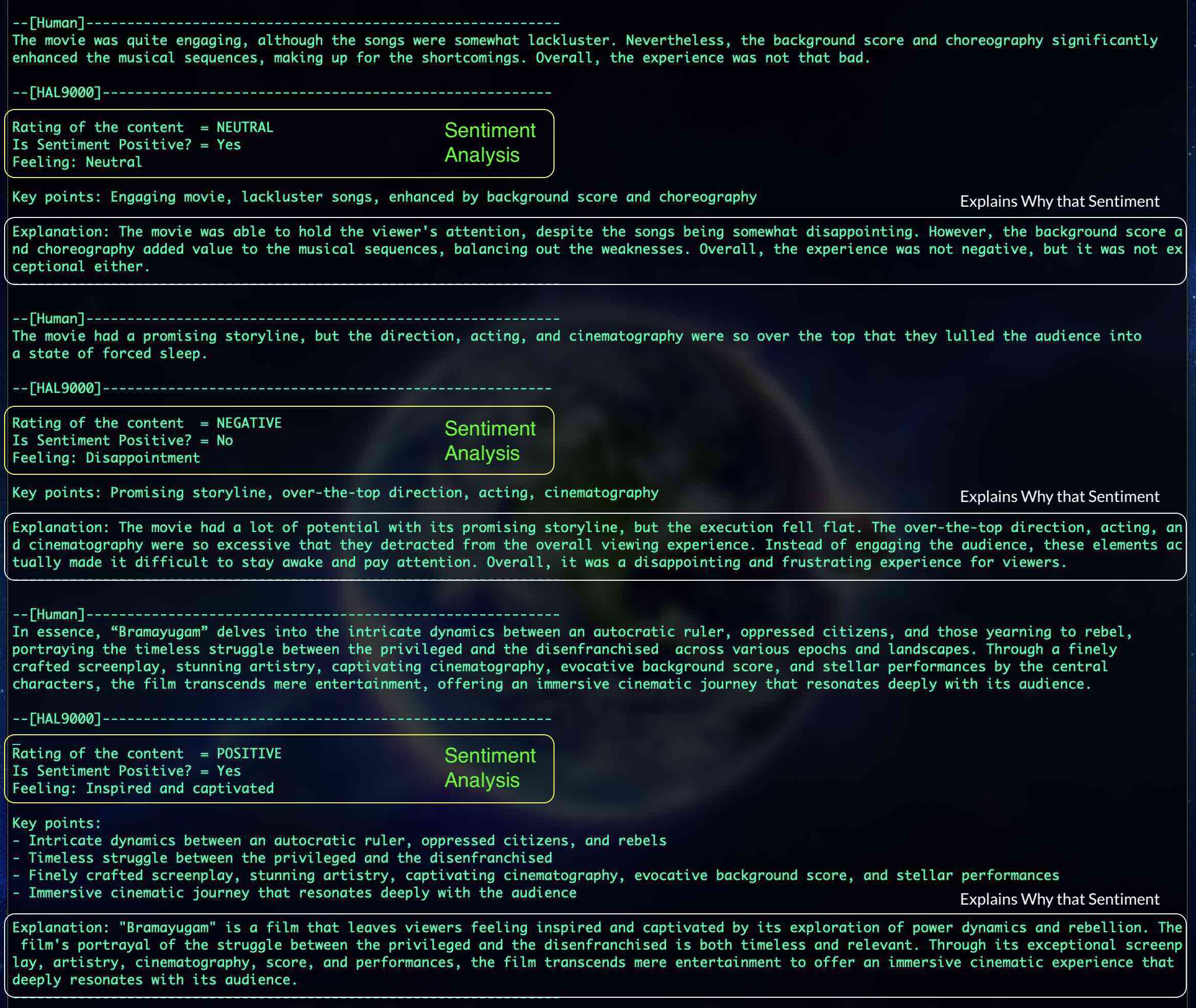
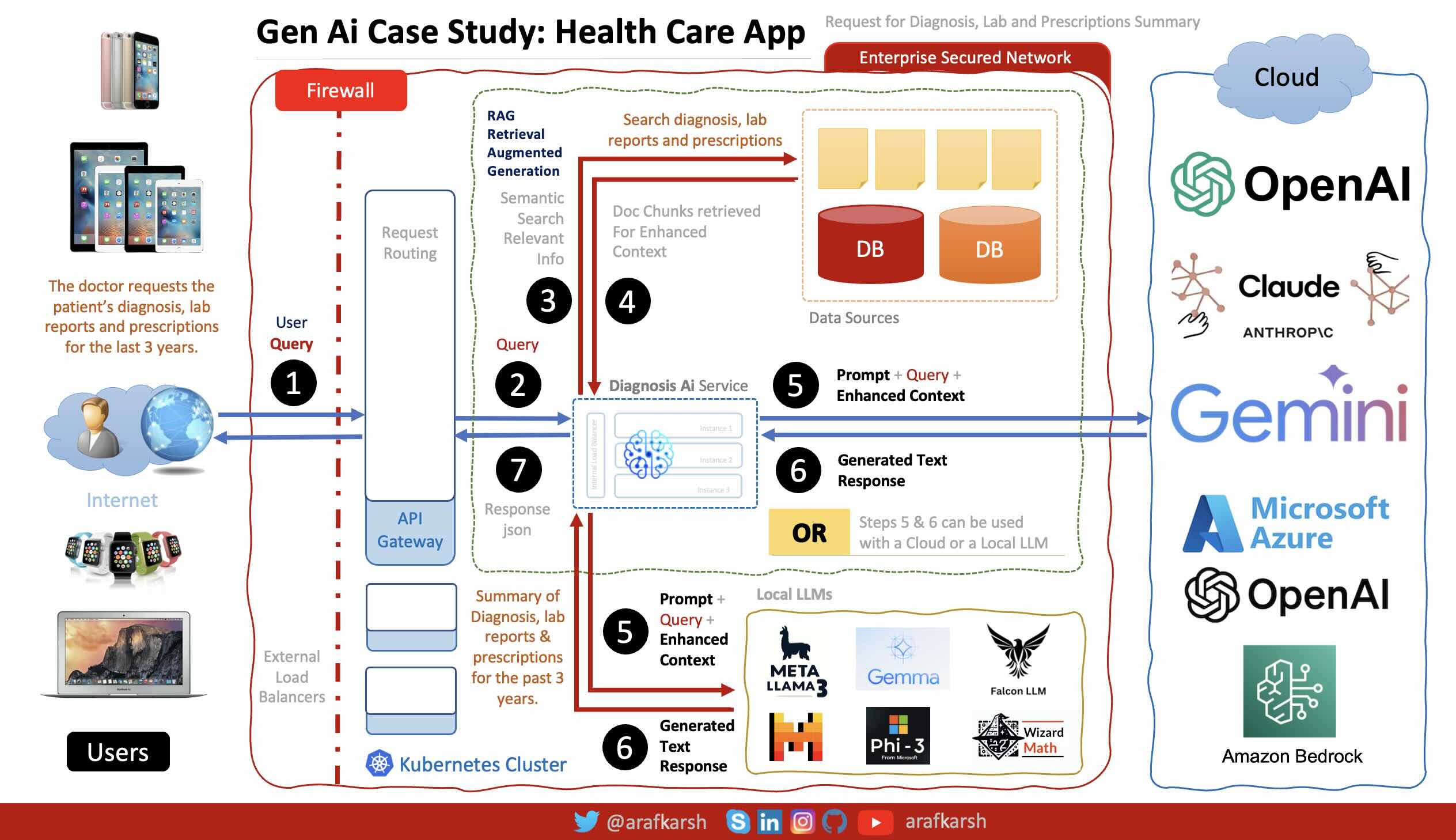
Retrieval-Augmented Generation (RAG) enhances the output of large language models (LLMs) by incorporating authoritative external knowledge bases. While LLMs are trained on vast datasets and utilize billions of parameters to generate responses for tasks like question answering, language translation, and text completion, RAG optimizes these outputs by referencing specific, up-to-date information sources beyond the model's training data. This process significantly extends the capabilities of LLMs to cater to specialized domains or an organization's internal knowledge without necessitating model retraining. Consequently, RAG provides a cost-effective solution to ensure that the generated content remains relevant, accurate, and contextually appropriate.
- They may provide false information when they lack the correct answer.
- They can deliver outdated or generic information when specific, current responses are expected by the user.
- They might generate responses based on non-authoritative sources.
- They can produce inaccurate responses due to terminology confusion, where different training sources use the same terms to describe different concepts.
Retrieval-Augmented Generation (RAG) addresses several challenges associated with LLMs by directing the model to fetch relevant information from authoritative, pre-determined knowledge sources. This approach allows organizations to exert more control over the content generated by the model, ensuring accuracy and relevance. Additionally, it provides users with clearer insights into the sources and processes the LLM uses to formulate its responses.
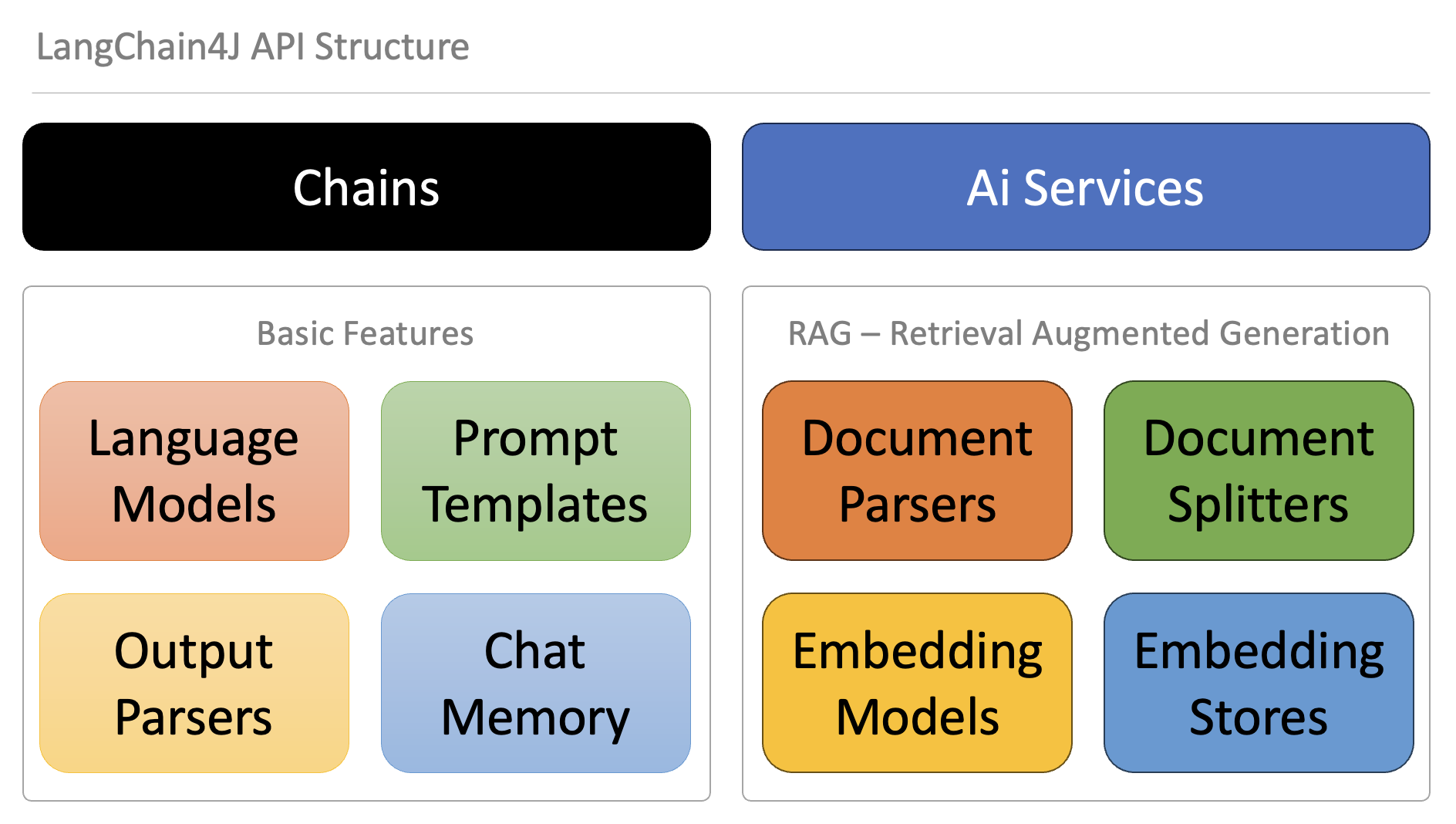
- Low level. At this level, you have the most freedom and access to all the low-level components such as ChatLanguageModel, UserMessage, AiMessage, EmbeddingStore, Embedding, etc. These are the "primitives" of your LLM-powered application. You have complete control over how to combine them, but you will need to write more glue code.
- High level. At this level, you interact with LLMs using high-level APIs like AiServices and Chains, which hides all the complexity and boilerplate from you. You still have the flexibility to adjust and fine-tune the behavior, but it is done in a declarative manner.
 Read more... LangChain4J Introduction
Read more... LangChain4J Introduction
- SpringBoot 3.2.4
- Java 22
- Jakarta EE 10 (jakarta.servlet., jakarta.persistence., javax.validation.*)
- PostgreSQL Database 14
- Ollama 0.1.38
By default the app will use H2 In-Memory Database. No Database setup required for this.
- git clone https://github.com/arafkarsh/ms-springboot-324-ai.git
- cd ms-springboot-324-ai
- cd database
- Read the README.md to setup your database (PostgreSQL Database)
- By Default (Dev Mode) the App will use In-Memory H2 Database
Run the "compile" from ms-springboot-324-ai
- compile OR ./compile (Runs in Linux and Mac OS)
- mvn clean; mvn -e package; (All Platforms)
- Use the IDE Compile options
- Clean up the target folder
- Generate the build no. and build date (takes application.properties backup)
- build final output SpringBoot fat jar and maven thin jar
- copy the jar files (and dependencies) to src/docker folder
- copy the application.properties file to current folder and src/docker folder
In Step 1.2.2 application.properties file will be auto generated by the "compile" script. This is a critical step. Without generated application.properties file the service will NOT be running. There is pre-built application properties file.
- run OR ./run (Runs in Linux or Mac OS)
- run prod (to run the production profile, default is dev profile)
- mvn spring-boot:run (All Platforms - Profile dev H2 In-Memory Database)
- mvn spring-boot:run -Dspring-boot.run.profiles=prod (All platforms - Profile prod PostgreSQL DB)
- test OR ./test (Runs in Linux or Mac OS)
- Execute the curl commands directly (from the test script)
- OpenAI (Examples available)
- Ollama - run AI models on your local machine (Examples available)
- Azure Open AI
- Amazon Bedrock
- Cohere's Command
- AI21 Labs' Jurassic-2
- Meta's LLama 2
- Amazon's Titan
- Google Vertex AI Palm
- Google Gemini
- HuggingFace - access thousands of models, including those from Meta such as Llama2
- MistralAI
- OpenAI with DALL-E (Examples available)
- StabilityAI
- OpenAI
- OpenAI
- Ollama
- Azure OpenAI
- ONNX
- PostgresML
- Bedrock Cohere
- Bedrock Titan
- Google VertexAI
- Mistal AI
The Vector Store API provides portability across different providers, featuring a novel SQL-like metadata filtering API that maintains portability.
- Azure Vector Search
- Chroma
- Milvus
- Neo4j
- PostgreSQL/PGVector
- PineCone
- Redis
- Weaviate
- Qdrant
- OpenAI
- Azure OpenAI
- VertexAI
- Mistral AI
- Setting up Postman with REST Endpoints for Testing
- CRUD Examples
- JWT Token Examples
Check the CRUD_Examples.md
(C) Copyright 2024 : Apache 2 License : Author: Araf Karsh Hamid
* Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License.