This is a Machine Learning [optimization and operationalization] capstone project [showcasing the know-how by determining deployments targets, enabling foresights, baselining performance metrics, scaning logs and benchmarking], which was part of the ML Engineer for Microsoft Azure Nanodegree Scholarship (preparing for Microsoft [Designing and Implementing a Data Science Solution on Azure] Exam DP-100).
The business goal/objective was binary classification inferencing [for decision intel foresights] on the detection of [non benign] infilteration traffic while passively scaning a true real-world data (PCAPs) of daily network flows. ... more on the CIC [IDS2017] dataset's official poster.
Rather than its score-matching [yet slower] VotingEnsemble, the best performing model was an Azure AutoML [SparseNormalizer & XGBoostClassifier] algorithm (in contrast to the HyperDrive run's best model); using such AutoML to train the best ML model before its OpenAPI endpoint gets deployed for production-ready consumption.
OPTIONAL: no special installation steps were required to set up this project in AzureML.
Having had already experimented with the outdated [non real-world] DARPA/KDDCup99/NSL-KDD[2009]; the current IDS data being used is a prepped [dropping headers and two 'infinity' columns] subset of the IDS2017 dataset [which was generated by Iman Sharafaldin, Arash Habibi Lashkari, and Ali A. Ghorbani; of the Canadian Institute for Cybersecurity (CIC), University of New Brunswick (UNB)] includes seven common updated family of [Intrusion Traffic] attacks that meet real worlds criteria and is publicly available.
Given that the IDS2017 dataset consists of labeled network flows [including full packet payloads in pcap format]; and using both the AutoML and Hyperparameter Tuning, the task is to resemble an IDS (Intrusion Detection System) in solving the Intrusion Anomaly Detection with the IDS2017 dataset, particulary its narrowed scope of [Infiltration] features, as follows:
-
Infiltration – Dropbox download - Meta exploit Win Vista (14:19 and 14:20-14:21 p.m.) and (14:33 -14:35)
- Attacker:
Kali, 205.174.165.73 - Victim:
Windows Vista, 192.168.10.8
- Attacker:
-
Infiltration – Cool disk – MAC (14:53 p.m. – 15:00 p.m.)
- Attacker:
Kali, 205.174.165.73 - Victim:
MAC, 192.168.10.25
- Attacker:
-
Infiltration – Dropbox download - Win Vista (15:04 – 15:45 p.m.)
- First Step:
- Attacker:
Kali, 205.174.165.73 - Victim:
Windows Vista, 192.168.10.8
- Attacker:
- Second Step (Portscan + Nmap):
- Attacker:
Vista, 192.168.10.8 - Victim:
All other clients
- Attacker:
- First Step:
For accessing the data in the Azure ML workspace, the downloaded compressed orignal folder was extracted into a public Azure storage blob container; and its web URL was used to import the CSV tabular CSV [into both the default datastore and dataset] as follows:
Dataset.Tabular.from_delimited_files(https://workspace1st4305015718.blob.core.windows.net/public/IDS2017InfilterationFeaturized.csv)
Noting that below headers 1st row was intentionally dropped pre-training:
[' Destination Port', ' Flow Duration', ' Total Fwd Packets', ' Total Backward Packets', 'Total Length of Fwd Packets', ' Total Length of Bwd Packets', ' Fwd Packet Length Max', ' Fwd Packet Length Min', ' Fwd Packet Length Mean', ' Fwd Packet Length Std', 'Bwd Packet Length Max', ' Bwd Packet Length Min', ' Bwd Packet Length Mean', ' Bwd Packet Length Std', 'Flow Bytes/s', ' Flow Packets/s', ' Flow IAT Mean', ' Flow IAT Std', ' Flow IAT Max', ' Flow IAT Min', 'Fwd IAT Total', ' Fwd IAT Mean', ' Fwd IAT Std', ' Fwd IAT Max', ' Fwd IAT Min', 'Bwd IAT Total', ' Bwd IAT Mean', ' Bwd IAT Std', ' Bwd IAT Max', ' Bwd IAT Min', 'Fwd PSH Flags', ' Bwd PSH Flags', ' Fwd URG Flags', ' Bwd URG Flags', ' Fwd Header Length', ' Bwd Header Length', 'Fwd Packets/s', ' Bwd Packets/s', ' Min Packet Length', ' Max Packet Length', ' Packet Length Mean', ' Packet Length Std', ' Packet Length Variance', 'FIN Flag Count', ' SYN Flag Count', ' RST Flag Count', ' PSH Flag Count', ' ACK Flag Count', ' URG Flag Count', ' CWE Flag Count', ' ECE Flag Count', ' Down/Up Ratio', ' Average Packet Size', ' Avg Fwd Segment Size', ' Avg Bwd Segment Size', ' Fwd Header Length.1', 'Fwd Avg Bytes/Bulk', ' Fwd Avg Packets/Bulk', ' Fwd Avg Bulk Rate', ' Bwd Avg Bytes/Bulk', ' Bwd Avg Packets/Bulk', 'Bwd Avg Bulk Rate', 'Subflow Fwd Packets', ' Subflow Fwd Bytes', ' Subflow Bwd Packets', ' Subflow Bwd Bytes', 'Init_Win_bytes_forward', ' Init_Win_bytes_backward', ' act_data_pkt_fwd', ' min_seg_size_forward', 'Active Mean', ' Active Std', ' Active Max', ' Active Min', 'Idle Mean', ' Idle Std', ' Idle Max', ' Idle Min', ' Label']
-
Kind of model chosen for the Hyperparameter Tuning experiment:
- Logistic regression was the algorithm chosen as a linear model for such classification [rather than regression, despite its name]; due to its robustness and the fact that the critical requirement of regularization is applied by default via lowering the C parameter to an optimal 1.
-
Below is a high level overview of the types of parameters and their ranges used for the hyperparameter search:
- The early_termination_policy was a BanditPolicy with these parameters:
(evaluation_interval = 2, slack_factor = 0.1, delay_evaluation=0)- The param_sampling was a RandomParameterSampling with two parameters:
({"--C": uniform(0.2, 0.9), "--max_iter": choice(10,15,20)})- The estimator was the "deprecated" SKLearn with these parameters:
(source_directory= script_folder, compute_target=compute_target, entry_script="train.py")- The HyperDriveConfig [that used the estimator, hyperparameter sampler, and policy] was as follows:
(estimator=est, hyperparameter_sampling=ps, policy=policy, primary_metric_name='accuracy', primary_metric_goal=PrimaryMetricGoal.MAXIMIZE, max_total_runs=10, max_concurrent_runs=2)
-
Best HyperDrive run's best model had scored a %99.98 Accuracy, with confusion_matrix of [[28857, 0], [0, 4]], an almost full mark on recall and precsion [considering the log_loss of 1.0978e-4], alas only on the training [non test-validated] data.
-
parameters of the hyper-tuned model:
- The
(best_run.get_details()['runDefinition']['arguments'])were as follows:
['--C', '0.674092700168093', '--max_iter', '15'] - The
-
Such model could be improved via changing the
primary_metric_name='Accuracy'into an averaged metric along with an overall F1 score [given its current status of imbalanced data] and considering the use of SGDClassifier with ‘log’ loss [faster than a “saga” solver with L1/elasticnet penalty].- Screenshot of the [Hyperparameter Tuning]
RunDetailswidget:
- Screenshot of the [Hyperparameter Tuning]
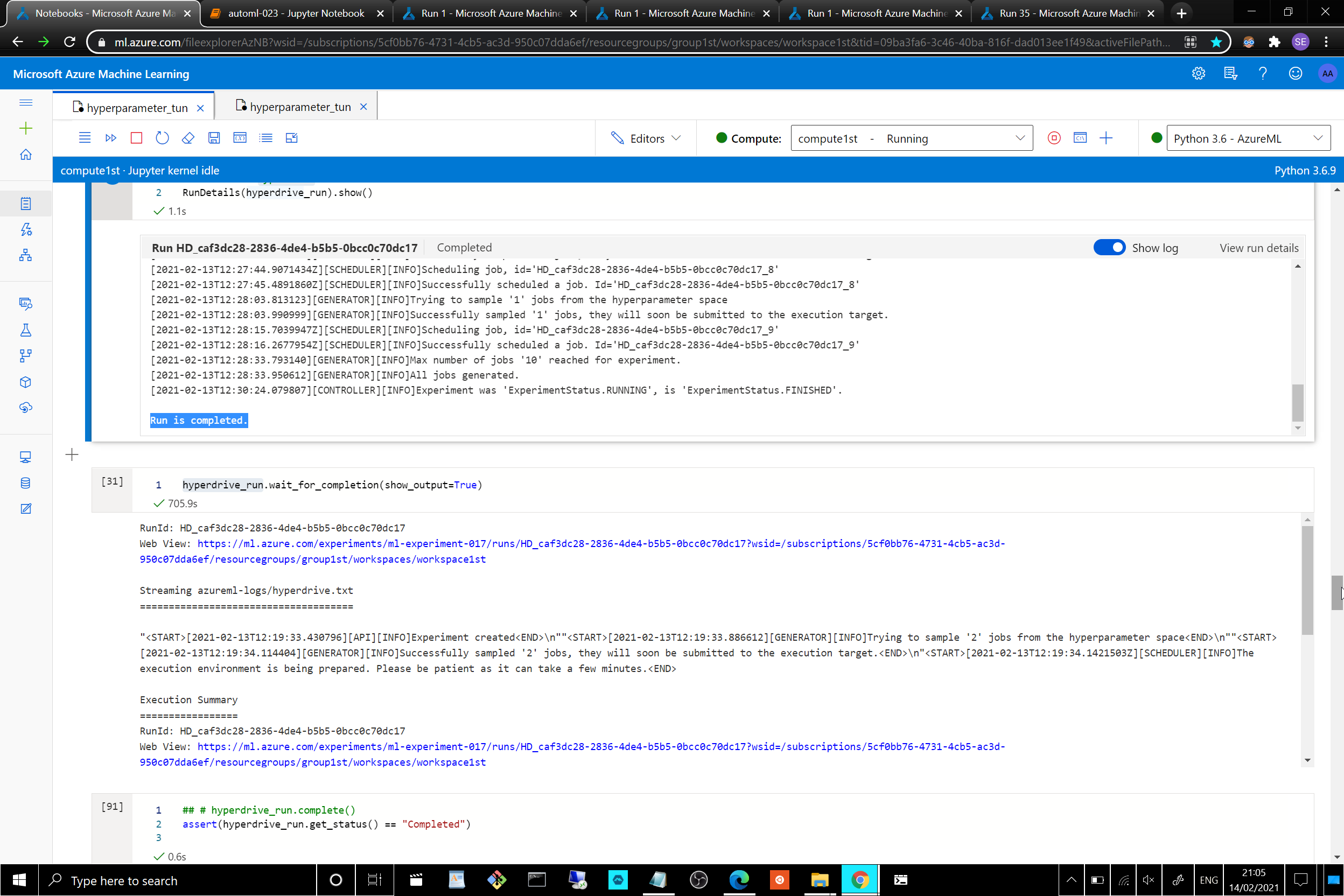
- Screenshot of the best [Hyperparameter Tuning] model trained with it's parameters:
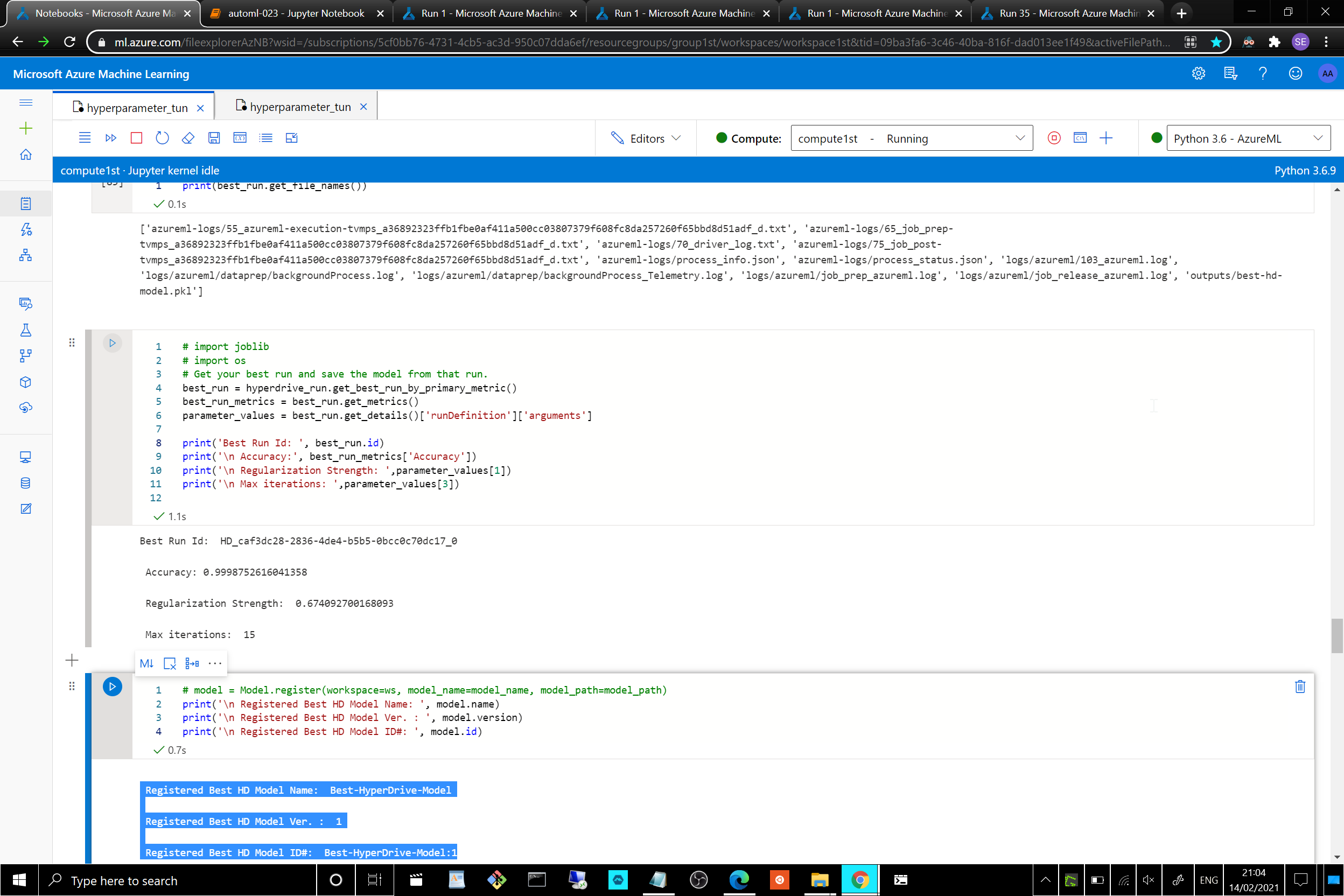
-
1st, below steps were processed:
- Generated features for the dataset.DatasetFeaturization.
- Completed Dataset Featurization [fitting featurizers and featurizing the dataset].
- Performed class balancing sweeping (DatasetBalancing).
-
Then, excuted the experiment used
automlsettings, as in the below high level overview:
automl_settings = { "experiment_timeout_minutes": 25, "max_concurrent_iterations": 5, 'model_explainability': True, "primary_metric": 'accuracy' # 'normalized_root_mean_squared_error' # 'precision_score_weighted, accuracy, AUC_weighted, norm_macro_recall, average_precision_score }
- and while more on the
automlconfiguration is documented @ aka.ms/AutoMLConfig; below is a high level overview of the experiment usedautomlconfiguration:
automl_config = AutoMLConfig(compute_target=compute_target, task = "classification", training_data = dataset, label_column_name = label_column_name, path = project_folder, enable_early_stopping = True, # featurization= 'auto', # Default # enable_onnx_compatible_models=True, debug_log = "automl_errors.log", **automl_settings )
- Thus, the final json string was as follows:
AMLSettingsJsonString': '{"path":null,"name":"ml-experiment-025","subscription_id":"5cf0bb76-4731-4cb5-ac3d-950c07dda6ef","resource_group":"group1st","workspace_name":"workspace1st","region":"uksouth","compute_target":"cpu-cluster","spark_service":null,"azure_service":"remote","many_models":false,"pipeline_fetch_max_batch_size":1,"iterations":1000,"primary_metric":"accuracy","task_type":"classification","data_script":null,"validation_size":0.0,"n_cross_validations":null,"y_min":null,"y_max":null,"num_classes":null,"featurization":"auto","_ignore_package_version_incompatibilities":false,"is_timeseries":false,"max_cores_per_iteration":1,"max_concurrent_iterations":5,"iteration_timeout_minutes":null,"mem_in_mb":null,"enforce_time_on_windows":false,"experiment_timeout_minutes":25,"experiment_exit_score":null,"whitelist_models":null,"blacklist_algos":["TensorFlowLinearClassifier","TensorFlowDNN"],"supported_models":["LightGBM","LinearSVM","TensorFlowDNN","SVM","GradientBoosting","ExtremeRandomTrees","TensorFlowLinearClassifier","KNN","SGD","BernoulliNaiveBayes","XGBoostClassifier","MultinomialNaiveBayes","LogisticRegression","RandomForest","AveragedPerceptronClassifier","DecisionTree"],"private_models":[],"auto_blacklist":true,"blacklist_samples_reached":false,"exclude_nan_labels":true,"verbosity":20,"_debug_log":"azureml_automl.log","show_warnings":false,"model_explainability":true,"service_url":null,"sdk_url":null,"sdk_packages":null,"enable_onnx_compatible_models":false,"enable_split_onnx_featurizer_estimator_models":false,"vm_type":"STANDARD_DS12_V2","telemetry_verbosity":20,"send_telemetry":true,"enable_dnn":false,"scenario":"SDK-1.13.0","environment_label":null,"force_text_dnn":false,"enable_feature_sweeping":true,"enable_early_stopping":true,"early_stopping_n_iters":10,"metrics":null,"enable_ensembling":true,"enable_stack_ensembling":true,"ensemble_iterations":15,"enable_tf":false,"enable_subsampling":null,"subsample_seed":null,"enable_nimbusml":false,"enable_streaming":false,"force_streaming":false,"track_child_runs":true,"allowed_private_models":[],"label_column_name":"Column39","weight_column_name":null,"cv_split_column_names":null,"enable_local_managed":false,"_local_managed_run_id":null,"cost_mode":1,"lag_length":0,"metric_operation":"maximize","preprocess":true}
- Auto ML achieved full precision and recall marks [with zero false negatives] on the training data; on the other hand unfortunately, [out of 57681 'benign' packets] one adversarial packet (once in a while) manages to infiltrate such IDS firewall's novel MLSecOps model on the test validation, as in the below confusion matrix (with a Log Loss = 1.3600e-4):
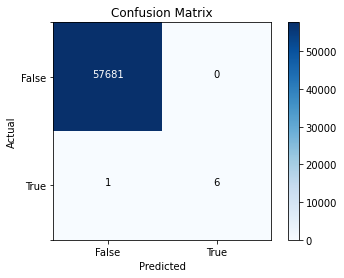
precision_score_weighted [0.9997228285361334] recall_score_micro [0.9998614046637331] balanced_accuracy [0.5] precision_score_macro [0.49993070233186654] AUC_micro [0.9999999387723731] f1_score_micro [0.9998614046637331] log_loss [0.0008936553391131103] accuracy [0.9998614046637331] matthews_correlation [0.0] average_precision_score_macro [0.6579545286446318] AUC_macro [0.999848390338566] AUC_weighted [0.999848390338566] norm_macro_recall [0.0] average_precision_score_weighted [0.9999051545752498] precision_score_micro [0.9998614046637331] recall_score_weighted [0.9998614046637331] weighted_accuracy [0.9999999807860075] f1_score_weighted [0.9997921117980992] average_precision_score_micro [0.9999999135797512] f1_score_macro [0.49996534876468346]
- However, final metrics associated with the deployed Auto ML model were:
f1_score_macro 1.0 recall_score_micro 1.0 matthews_correlation 1.0 recall_score_macro 1.0 AUC_macro 1.0 AUC_micro 1.0 weighted_accuracy 1.0 average_precision_score_micro 1.0 log_loss 9.3142013956508e-05 recall_score_weighted 1.0 precision_score_macro 1.0 precision_score_weighted 1.0 norm_macro_recall 1.0 f1_score_weighted 1.0 average_precision_score_macro 1.0 balanced_accuracy 1.0 AUC_weighted 1.0 f1_score_micro 1.0 accuracy 1.0 average_precision_score_weighted 1.0 precision_score_micro 1.0 confusion_matrix aml://artifactId/ExperimentRun/dcid.AutoML_532e1f2e-40f2-44cf-845f-4ff45db1a7c8_6/confusion_matrix accuracy_table aml://artifactId/ExperimentRun/dcid.AutoML_532e1f2e-40f2-44cf-845f-4ff45db1a7c8_6/accuracy_table
ITERATION PIPELINE DURATION METRIC BEST
12 SparseNormalizer LightGBM 0:01:18 1.0000 1.0000
35 SparseNormalizer XGBoostClassifier 0:01:30 1.0000 1.0000
Noting that: ITERATION is the iteration being evaluated, PIPELINE: is a summary description of the pipeline being evaluated, DURATION: is the time taken for the current iteration, METRIC: is the result of computing score on the fitted pipeline.
- The parameters of the 'faster' model:
('LightGBMClassifier', LightGBMClassifier(boosting_type='goss', class_weight=None, colsample_bytree=0.6933333333333332, importance_type='split', learning_rate=0.021060526315789474, max_bin=200, max_depth=8, min_child_samples=3585, min_child_weight=1, min_split_gain=0.10526315789473684, n_estimators=800, num_leaves=32, objective=None, reg_alpha=0.9473684210526315, reg_lambda=0.6842105263157894, silent=True, subsample=1, subsample_for_bin=200000, subsample_freq=0, verbose=-10))
- Thus, the best fitted model pipeline is as follows:
Pipeline(memory=None, steps=[('datatransformer', DataTransformer(enable_dnn=None, enable_feature_sweeping=None, feature_sweeping_config=None, feature_sweeping_timeout=None, featurization_config=None, force_text_dnn=None, is_cross_validation=None, is_onnx_compatible=None, logger=None, observer=None, task=None, working_dir=None)), ('SparseNormalizer', <azureml.auto... colsample_bytree=0.5, eta=0.1, gamma=0, learning_rate=0.1, max_delta_step=0, max_depth=6, max_leaves=15, min_child_weight=1, missing=nan, n_estimators=100, n_jobs=1, nthread=None, objective='reg:logistic', random_state=0, reg_alpha=0, reg_lambda=2.0833333333333335, scale_pos_weight=1, seed=None, silent=None, subsample=1, tree_method='auto', verbose=-10, verbosity=0))], verbose=False)
-
Both best AutoML [SparseNormalizer & LightGBM / XGBoostClassifier] algorithms have scored a 100% Accuracy; notwithstanding that, such imbalanced data can lead to a falsely perceived positive effect of a model's accuracy; thus, planning to use SMOTENN featurization to double check the F1 score [given that inputs were analyzed, and no high cardinality features were detected; and despite using a validation dataset to improve model performance and avoid an overfit].
- Screenshot of the [Auto ML]
RunDetailswidget:
- Screenshot of the [Auto ML]
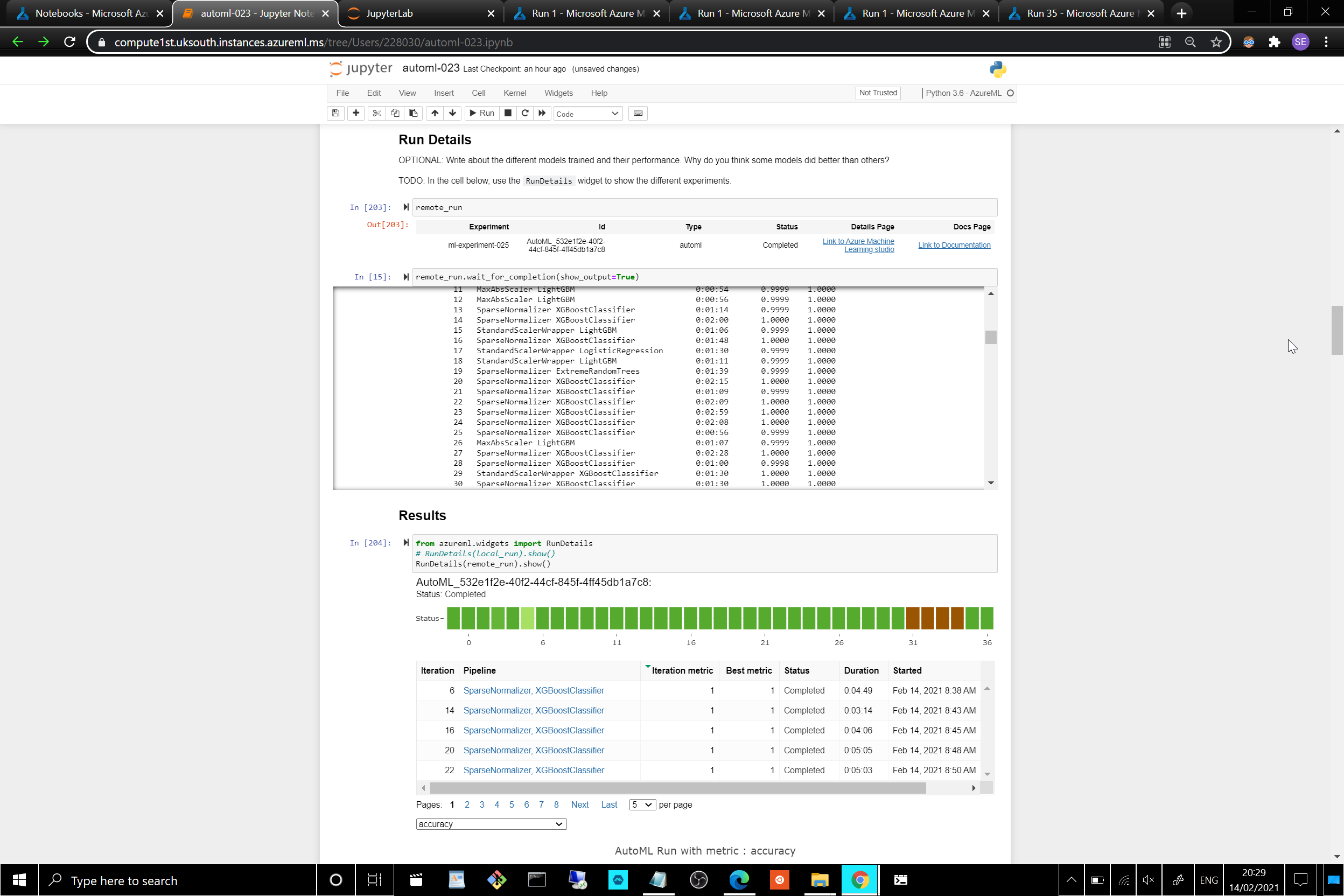
- Screenshot of the best [Auto ML] model trained with it's parameters:

Below are the screeshots for the AutoML [Fitted and Later Deployed] Best Model's Run ID:
![AutoML[Fitted-Best-Model]Run-ID-Screenshot-in-Notebook](/c6ai/Capstone/blob/main/images/AutoML%5BDeployed-Best-Model%5DRun-ID-Screenshot-in-Notebook.png?raw=true)
![AutoML[Fitted-Best-Model]Run-ID-Screenshot-in-Studio](/c6ai/Capstone/blob/main/images/AutoML%5BDeployed-Best-Model%5DRun-ID-Screenshot-in-Studio.png?raw=true)
- Below is a high level overview of the deployed fitted model:
('LightGBMClassifier', LightGBMClassifier(boosting_type='goss', class_weight=None, colsample_bytree=0.6933333333333332, importance_type='split', learning_rate=0.021060526315789474, max_bin=200, max_depth=8, min_child_samples=3585, min_child_weight=1, min_split_gain=0.10526315789473684, n_estimators=800, num_leaves=32, objective=None, reg_alpha=0.9473684210526315, reg_lambda=0.6842105263157894, silent=True, subsample=1, subsample_for_bin=200000, subsample_freq=0, verbose=-10))
-
Instructions on how to query the endpoint with a sample input:
http://c76e1449-ef84-4a53-9904-61ce2f8aa744.uksouth.azurecontainer.io/swagger.jsonhttp://c76e1449-ef84-4a53-9904-61ce2f8aa744.uksouth.azurecontainer.io/score- Above [endpoint 'score
andswagger.json`] APIs are up and running; nontheless, the below code was used to live-test the RESTful API within the notebook:
test_samples = X_test_df[26840:26842].to_json(orient='records')result = service.run(input_data = test_samples)residual = result - y_test_dfurl = aci_service.scoring_uriapi_key = ''headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)}resp = requests.post(aci_service.scoring_uri, test_samples, headers = headers)resp.text- Which returned back the anticipated foresights accurately as follows:
'{"predictions": [0, 1]}' - Above [endpoint 'score

- Screenshot showing the model endpoint as active/healthy:

Below recording's link was the demo of showcasing the project in action, demonstrating the key steps; in addition to the required screenshots to demonstrate [along with the above screencasts] the completed project [overall end-to-end workflow's] critical stages' criteria that meet specifications of its various main steps [a working model; a demo of the deployed model, and a demo of a sample request sent to the endpoint and its response]:
- Screencast Recording Documentation Demo in less than 5 minutes:
https://vimeo.com/512406014/26be4aa61b
- Publishing of the pipeline [as a service] was activated for remotely triggering experiment runs [for the sake of full automation with planned PowerApps/PowerBI Logic App and/or even grid triggers].
- Exporting the model for supportting ONNX to be deployed to a DLT connected Dapp device.
- Enabling logging and integrating App Insights with Sentinel and/or CASB [with events grid for the deployed app].
Above are some of the standout suggestions that were attempted before but were currently excluded.
-
Potential future improvements could be identified as:
- Retraining Hyperparameter Tuning with HyperDrive using Bayesian and/or 'Entire Grid' sampling.
- Extending AutoML config to include more parameters.
- Documenting XAI and [operationalizing] model [explanation] as a web service, using the [interpretability package] to explain ML models & predictions.
- Completing the optional items about load-testing the endpoint.
- Using a Parallel Run Step in a pipeline. - Testing a local container with a downloaded model.