A PyTorch implement of TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes (ECCV 2018) by Megvii
- Paper link: arXiv:1807.01544
- Github: princewang1994/TextSnake.pytorch
- Blog: TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes

Comparison of different representations for text instances. (a) Axis-aligned rectangle. (b) Rotated rectangle. (c) Quadrangle. (d) TextSnake. Obviously, the proposed TextSnake representation is able to effectively and precisely describe the geometric properties, such as location, scale, and bending of curved text with perspective distortion, while the other representations (axis-aligned rectangle, rotated rectangle or quadrangle) struggle with giving accurate predictions in such cases.
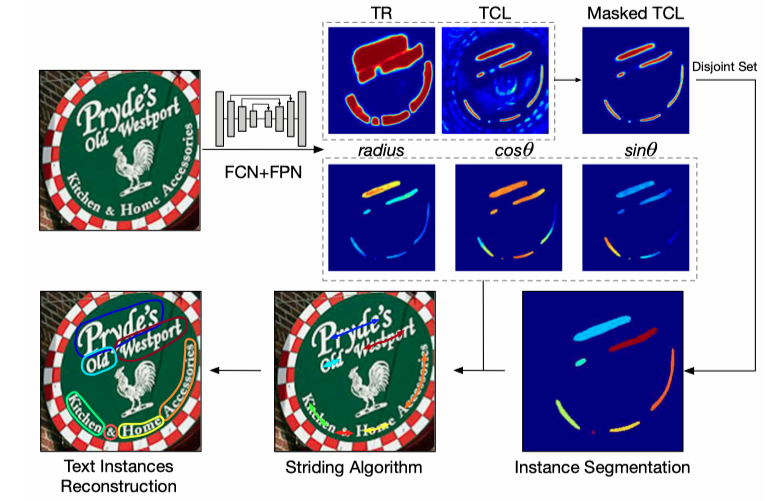
Textsnake elements:
- center point
- tangent line
- text region
Generally, this code has following features:
- include complete training and inference code
- pure python version without extra compiling
- compatible with laste PyTorch version (write with pytroch 0.4.0)
- support TotalText and SynthText dataset
This repo includes the training code and inference demo of TextSnake, training and infercence can be simplely run with a few code.
To run this repo successfully, it is highly recommanded with:
- Linux (Ubuntu 16.04)
- Python3.6
- Anaconda3
- NVIDIA GPU(with 8G or larger GPU memory for training, 2G for inference)
(I haven't test it on other Python version.)
- clone this repository
git clone https://github.com/princewang1994/TextSnake.pytorch.git- python package can be installed with
pip
$ cd $TEXTSNAKE_ROOT
$ pip install -r requirements.txtTotal-Text: follow the dataset/total_text/README.mdSynthText: follow the datset/synth-text/README.md
$ CUDA_VISIBLE_DEVICES=$GPUID python train.py synthtext_pretrain --dataset synth-text --viz --max_epoch 1 --batch_size 8Training model with given experiment name $EXPNAME
training from scratch:
$ EXPNAME=example
$ CUDA_VISIBLE_DEVICES=$GPUID python train.py $EXPNAME --viztraining with pretrained model(improved performance much)
$ EXPNAME=example
$ CUDA_VISIBLE_DEVICES=$GPUID python train.py example --viz --batch_size 8 --resume save/synthtext_pretrain/textsnake_vgg_0.pthoptions:
exp_name: experiment name, used to identify different training processes--viz: visualization toggle, output pictures are saved to./visby default
other options can be show by run python train.py -h
Runing following command can generate demo on TotalText dataset (300 pictures), the result are save to ./vis by default
$ EXPNAME=example
$ CUDA_VISIBLE_DEVICES=$GPUID python eval_textsnake.py $EXPNAME --checkepoch 190options:
exp_name: experiment name, used to identify different training process
other options can be show by run python train.py -h
Total-Text metric is included in dataset/total_text/Evaluation_Protocol/Python_scripts/Deteval.py, you should first modify the input_dir in Deteval.py and run following command for computing DetEval:
$ python dataset/total_text/Evaluation_Protocol/Python_scripts/Deteval.py $EXPNAME --tr 0.8 --tp 0.4or
$ python dataset/total_text/Evaluation_Protocol/Python_scripts/Deteval.py $EXPNAME --tr 0.7 --tp 0.6it will output metrics reports.
- SynthText pretrained model: synthtext_fixlr/textsnake_vgg_0.pth (extract code:
xmoh) - Total-Text pretrained model: finetune_larger_tcl/textsnake_vgg_180.pth (extract code:
dms6) - Google Drive: TextSnake_pretrain
Download from links above and place pth file to the corresponding path(save/XXX/textsnake_vgg_XX.pth).
Following table reports DetEval metrics when we set vgg as the backbone(can be reproduced by using pertained model in Pretrained Model section):
| tr=0.7 / tp=0.6(P|R|F1) | tr=0.8 / tp=0.4(P|R|F1) | FPS(On single 1080Ti) | |
|---|---|---|---|
| expand / no merge | 0.652 | 0.549 | 0.596 | 0.874 | 0.711 | 0.784 | 12.07 |
| expand / merge | 0.698 | 0.578 | 0.633 | 0.859 | 0.660 | 0.746 | 8.38 |
| no expand / no merge | 0.753 | 0.693 | 0.722 | 0.695 | 0.628 | 0.660 | 9.94 |
| no expand / merge | 0.747 | 0.677 | 0.710 | 0.691 | 0.602 | 0.643 | 11.05 |
| reported on paper | - | 0.827 | 0.745 | 0.784 |
* expand denotes expanding radius by 0.3 times while post-processing
* merge denotes that merging overlapped instance while post-processing
You can also run prediction on your own dataset without annotations:
- Download pretrained model and place
.pthfile tosave/pretrained/textsnake_vgg_180.pth - Run pure inference script as following:
$ EXPNAME=pretrained
$ CUDA_VISIBLE_DEVICES=$GPUID python demo.py $EXPNAME --checkepoch 180 --img_root /path/to/imagepredicted result will be saved in output/$EXPNAME and visualization in vis/${EXPNAME}_deploy
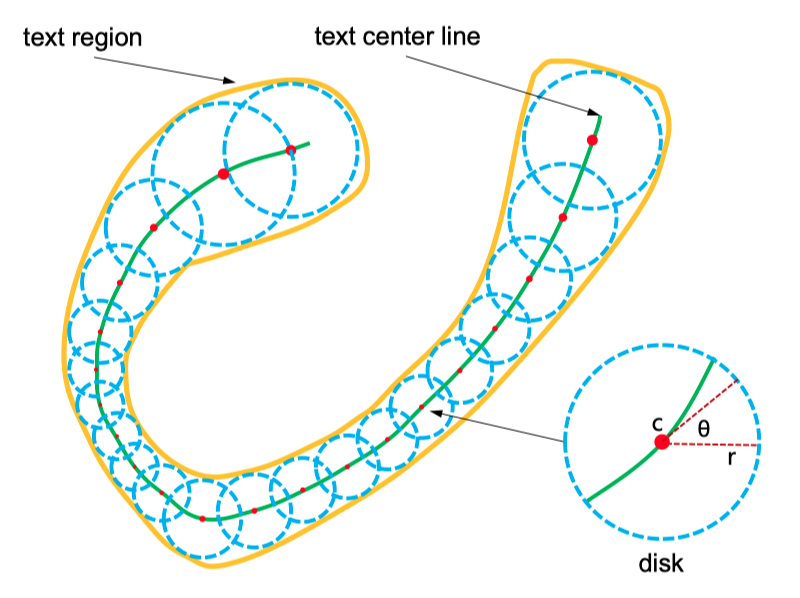
- left: prediction/ground true
- middle: text region(TR)
- right: text center line(TCL)




- Pretraining with SynthText
- Metric computing
- Pretrained model upload
- Pure inference script
- More dataset suport: [ICDAR15, CTW1500]
- Various backbone experiments
This project is licensed under the MIT License - see the LICENSE.md file for details
- This project is writen by Prince Wang, part of codes refer to songdejia/EAST
- Thanks techkang for your great help!