Official PyTorch implementation for the following paper:
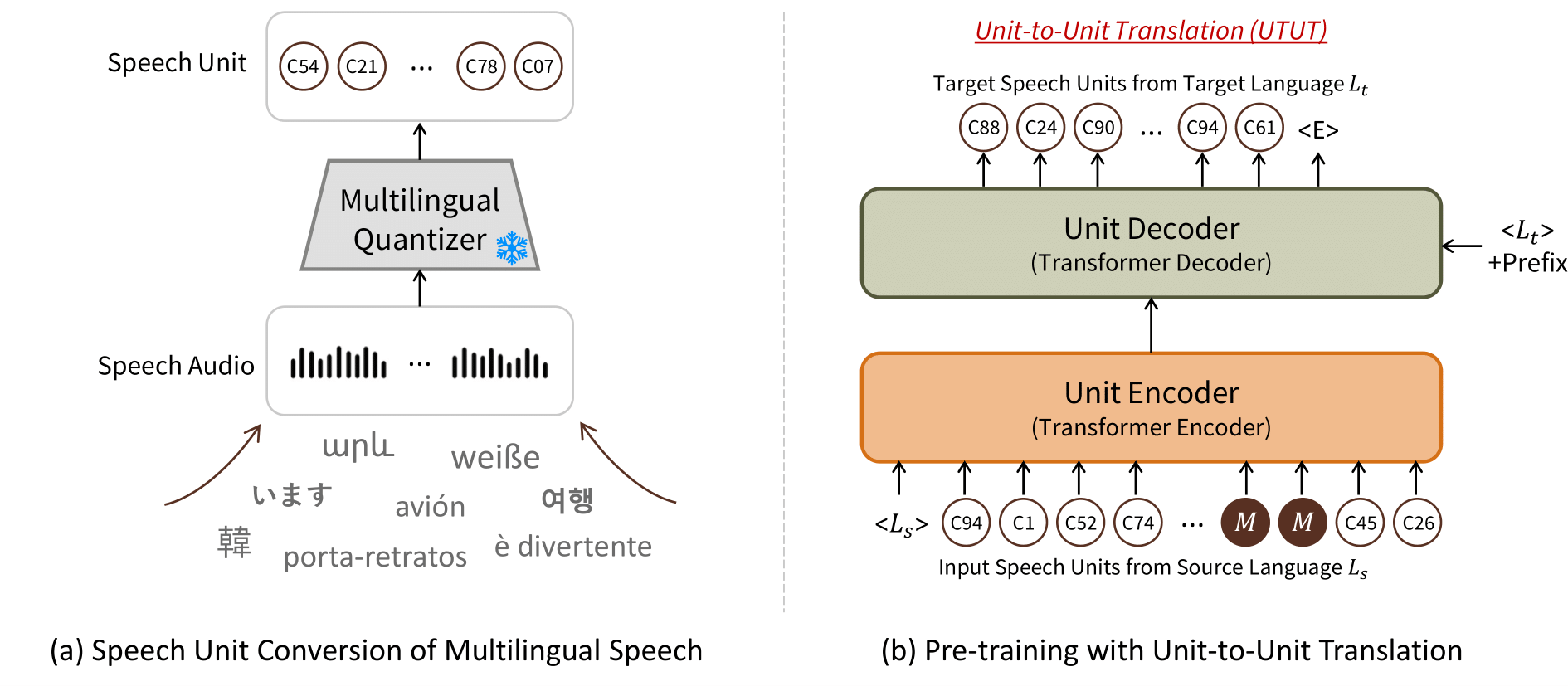
Textless Unit-to-Unit training for Many-to-Many Multilingual Speech-to-Speech Translation
Minsu Kim*, Jeongsoo Choi*, Dahun Kim, Yong Man Ro
IEEE/ACM Transactions on Audio, Speech, and Language Processing
[Paper] [Demo]
Python >=3.7,<3.11
git clone -b main --single-branch https://github.com/choijeongsoo/utut
cd utut
git submodule init
git submodule update
pip install -e fairseq
pip install -r requirements.txt
apt-get install espeak
-
mHuBERT Base, layer 11, km 1000
reference: textless_s2st_real_data
-
Pre-trained Model
Task Pretraining Data Model STS VoxPopuli (from year 2013), mTEDx download TTS VoxPopuli (from year 2013), mTEDx download TTST VoxPopuli (from year 2013), mTEDx download
-
En (English), Es (Spanish), and Fr (French)
reference: textless_s2st_real_data
-
It (Italian), De (German), and Nl (Dutch)
Unit config Unit size Vocoder language Dataset Model mHuBERT, layer 11 1000 It M-AILABS (male) ckpt, config mHuBERT, layer 11 1000 De CSS10 ckpt, config mHuBERT, layer 11 1000 Nl CSS10 ckpt, config
UTUT is pre-trained on Voxpopuli and mTEDx, where a large portion of data is from European Parliament events.
Before utilizing the pre-trained model, please consider the data domain where you want to apply it.
$ cd utut
$ PYTHONPATH=fairseq python inference_sts.py \
--in-wav-path samples/en/1.wav samples/en/2.wav samples/en/3.wav \
--out-wav-path samples/es/1.wav samples/es/2.wav samples/es/3.wav \
--src-lang en --tgt-lang es \
--mhubert-path /path/to/mhubert_base_vp_en_es_fr_it3.pt \
--kmeans-path /path/to/mhubert_base_vp_en_es_fr_it3_L11_km1000.bin \
--utut-path /path/to/utut_sts.pt \
--vocoder-path /path/to/vocoder_es.pt \
--vocoder-cfg-path /path/to/config_es.json
$ cd utut
$ PYTHONPATH=fairseq python inference_tts.py \
--in-txt-path samples/en/a.txt samples/en/b.txt samples/en/c.txt \
--out-wav-path samples/en/a.wav samples/en/b.wav samples/en/c.wav \
--src-lang en --tgt-lang en \
--utut-path /path/to/utut_tts.pt \
--vocoder-path /path/to/vocoder_en.pt \
--vocoder-cfg-path /path/to/config_en.json
$ cd utut
$ PYTHONPATH=fairseq python inference_tts.py \
--in-txt-path samples/en/a.txt samples/en/b.txt samples/en/c.txt \
--out-wav-path samples/es/a.wav samples/es/b.wav samples/es/c.wav \
--src-lang en --tgt-lang es \
--utut-path /path/to/utut_ttst.pt \
--vocoder-path /path/to/vocoder_es.pt \
--vocoder-cfg-path /path/to/config_es.json
19 source languages: en (English), es (Spanish), fr (French), it (Italian), pt (Portuguese), el (Greek), ru (Russian), cs (Czech), da (Danish), de (German), fi (Finnish), hr (Croatian), hu (Hungarian), lt (Lithuanian), nl (Dutch), pl (Polish), ro (Romanian), sk (Slovak), and sl (Slovene)
6 target languages: en (English), es (Spanish), fr (French), it (Italian), de (German), and nl (Dutch)
This repository is built upon Fairseq and speech-resynthesis. We appreciate the open source of the projects.
If our work is useful for your research, please cite the following paper:
@article{kim2024textless,
title={Textless Unit-to-Unit training for Many-to-Many Multilingual Speech-to-Speech Translation},
author={Kim, Minsu and Choi, Jeongsoo and Kim, Dahun and Ro, Yong Man},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
year={2024}
}
@inproceedings{choi2024av2av,
title={AV2AV: Direct Audio-Visual Speech to Audio-Visual Speech Translation with Unified Audio-Visual Speech Representation},
author={Choi, Jeongsoo and Park, Se Jin and Kim, Minsu and Ro, Yong Man},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}