Final project repo for UCLA CS 267A
scratch_pad.ipynb (colab) # use this notebook to test functions collaboratively
gnn_tutorial.ipynb (colab) # use this notebook for examples of GNN applications
pyro_stocks.ipynb (colab) # use this notebook to check out stock modeling with Pyro
The current Wiki & Industry relation matrices from TRSR must be extracted with the following command within the data directory:
tar zxvf relation.tar.gz
Directory after extraction (including the correlational tensors from this repo):
data
relation
correlations_trained
NASDAQ
...1215 files uploaded
NYSE
...1215 files not uploaded (too big)
sector_industry
NASDAQ_industry_ticker.json
NYSE_industry_ticker.json
NASDAQ_industry_relation.npy
NYSE_industry_relation.npy
wikidata
NASDAQ_wiki_relation.npy
NYSE_wiki_relation.npy
NYSE_connections.json
NASDAQ_connections.json
selected_wiki_connections.csv
In order to initialize our temporal relational tensors, you'll need to execute this command from the training directory, passing either "NYSE" or "NASDAQ" as an argument:
python init_temporal_correlations.py -market_name "NASDAQ"
NOTE: This will take a long time to execute and will result in massive tensors (~8hrs + 10GB for NASDAQ, ~24hrs + 29GB for NYSE).
| index | num_companies | num_timesteps (T) |
|---|---|---|
| NASDAQ | 1026 | 1245 |
| NYSE | 1737 | 1245 |
The pretrained weights were too large to store in this repository, but they can be accessed here.
Extract the file into the data directory:
tar zxvf pretrain.tar.gz
Directory after extraction:
data
pretrain
NASDAQ_rank_lstm_seq-16_unit-64_2.csv.npy
NYSE_rank_lstm_seq-8_unit-32_0.csv.npy
Below are the commands used to generate the results for this project.
python pytorch_relational_rank_model.py -m "NASDAQ" -ep 100 -up 0 -rn "sector_industry"
python pytorch_relational_rank_model.py -m "NASDAQ" -ep 100 -up 0 -rn "wikidata"
python pytorch_relational_rank_model.py -m "NASDAQ" -ep 100 -up 0 -rn "correlational"
python pytorch_relational_rank_model.py -m "NYSE" -ep 100 -up 0 -u 32 -rn "sector_industry"
python pytorch_relational_rank_model.py -m "NYSE" -ep 100 -up 0 -u 32 -rn "wikidata"
python pytorch_relational_rank_model.py -m "NYSE" -ep 100 -up 0 -u 32 -rn "correlational"
Note that training works using rolling windows --- train_size=200, val_size=20, test_size=20 --- and the number of windows is dynamically calculated by num_steps \ train_size. This results in each timestep being included in no more than 1 sliding window for ep=100 epochs each.
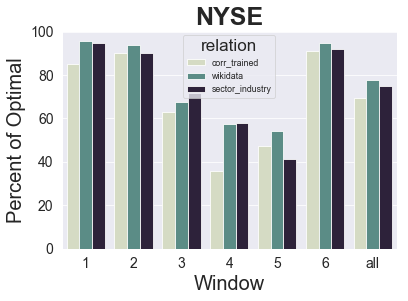
NOTE: In our original paper, the NYSE sector_industry training only completed 2 windows. The results_analysis.ipynb now contains the results which include the complete training and shows significantly improved stock prediction performance.
The results indicate that our correlational approach --- which only makes use of the stock data itself, no webscraped relational feature vectors --- can effectively approximate the relationships between companies and their stock price movements. All approaches outperform a simple buy-hold strategy that invests in the entire index by identifying top performing stocks that are approximately 35% of optimal for NASDAQ and 75% of optimal for NYSE. Optimal means that the model picked the top performing stock to invest in at every possible timestep, so the results are highly encouraging for all relational approaches and especially ours as it requires no extensive data collection efforts from various external sources.