


Table of Contents (click to expand)
Documentation is available here
Stable versions are available at PyPI
Slides are available here
日本語はこちら
SCOPE-RL is an open-source Python Software for implementing the end-to-end procedure regarding offline Reinforcement Learning (offline RL), from data collection to offline policy learning, off-policy performance evaluation, and policy selection. Our software includes a series of modules to implement synthetic dataset generation, dataset preprocessing, estimators for Off-Policy Evaluation (OPE), and Off-Policy Selection (OPS) methods.
This software is also compatible with d3rlpy, which implements a range of online and offline RL methods. SCOPE-RL enables an easy, transparent, and reliable experiment in offline RL research on any environment with OpenAI Gym and Gymnasium-like interface. It also facilitates the implementation of offline RL in practice on a variety of customized datasets and real-world datasets.
In particular, SCOPE-RL enables and facilitates evaluation and algorithm comparison related to the following research topics:
-
Offline Reinforcement Learning: Offline RL aims at learning a new policy from only offline logged data collected by a behavior policy. SCOPE-RL enables flexible experiments using customized datasets collected by various behavior policies and environments.
-
Off-Policy Evaluation: OPE aims at evaluating the performance of a counterfactual policy using only offline logged data. SCOPE-RL supports many OPE estimators and streamlines the experimental procedure to evaluate and compare OPE estimators. Moreover, we also implement advanced OPE methods, such as estimators based on state-action density estimation and cumulative distribution estimation.
-
Off-Policy Selection: OPS aims at identifying the best-performing policy from a pool of several candidate policies using offline logged data. SCOPE-RL supports some basic OPS methods and provides several metrics to evaluate the OPS accuracy.
This software is inspired by Open Bandit Pipeline, which is a library for OPE in contextual bandits. However, SCOPE-RL also implements a set of OPE estimators and tools to facilitate experiments about OPE for the contextual bandit setup by itself as well as those for RL.
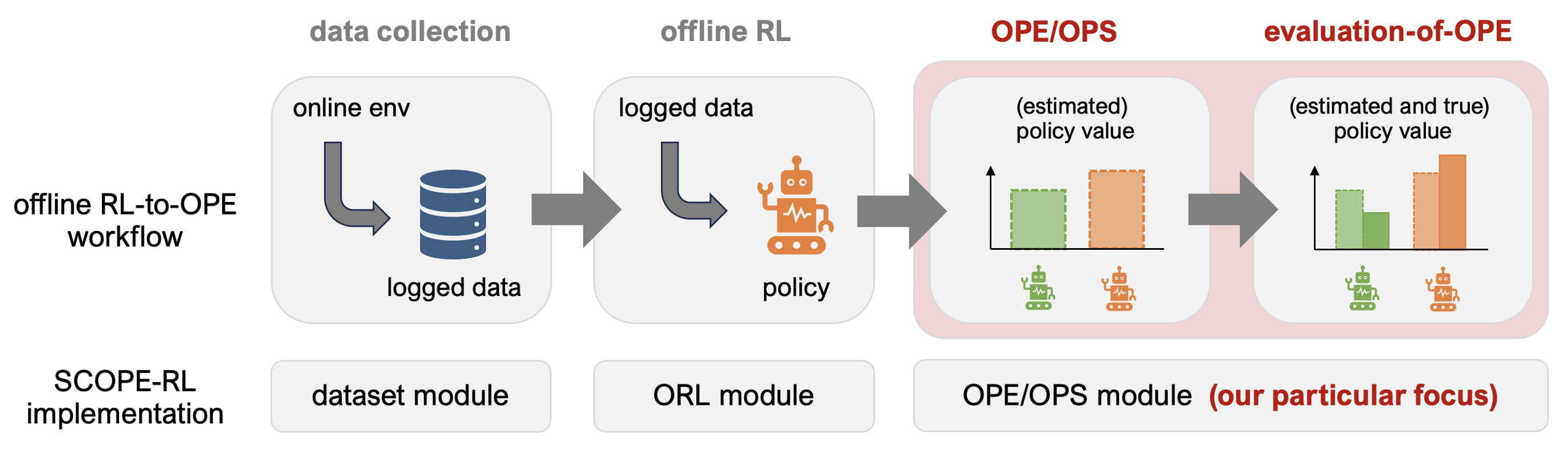
End-to-end workflow of offline RL and OPE with SCOPE-RL
SCOPE-RL mainly consists of the following three modules.
- dataset module: This module provides tools to generate synthetic data from any environment on top of OpenAI Gym and Gymnasium-like interface. It also provides tools to pre-process the logged data.
- policy module: This module provides a wrapper class for d3rlpy to enable flexible data collection.
- ope module: This module provides a generic abstract class to implement OPE estimators. It also provides some tools useful for performing OPS.
Behavior Policy (click to expand)
- Discrete
- Epsilon Greedy
- Softmax
- Continuous
- Gaussian
- Truncated Gaussian
OPE Estimators (click to expand)
- Expected Reward Estimation
- Basic Estimators
- Direct Method (Fitted Q Evaluation)
- Trajectory-wise Importance Sampling
- Per-Decision Importance Sampling
- Doubly Robust
- Self-Normalized Trajectory-wise Importance Sampling
- Self-Normalized Per-Decision Importance Sampling
- Self-Normalized Doubly Robust
- State Marginal Estimators
- State-Action Marginal Estimators
- Double Reinforcement Learning
- Weight and Value Learning Methods
- Augmented Lagrangian Method (BestDICE, DualDICE, GradientDICE, GenDICE, MQL/MWL)
- Minimax Q-Learning and Weight Learning (MQL/MWL)
- Basic Estimators
- Confidence Interval Estimation
- Bootstrap
- Hoeffding
- (Empirical) Bernstein
- Student T-test
- Cumulative Distribution Function Estimation
- Direct Method (Fitted Q Evaluation)
- Trajectory-wise Importance Sampling
- Trajectory-wise Doubly Robust
- Self-Normalized Trajectory-wise Importance Sampling
- Self-Normalized Trajectory-wise Doubly Robust
OPS Criteria (click to expand)
- Policy Value
- Policy Value Lower Bound
- Lower Quartile
- Conditional Value at Risk (CVaR)
Evaluation Metrics of OPS (click to expand)
- Mean Squared Error
- Spearman's Rank Correlation Coefficient
- Regret
- Type I and Type II Error Rates
- {Best/Worst/Mean/Std} performances of top-k policies
- Safety violation rate of top-k policies
- SharpeRatio@k
Note that in addition to the above OPE and OPS methods, researchers can easily implement and compare their own estimators through a generic abstract class implemented in SCOPE-RL. Moreover, practitioners can apply the above methods to their real-world data to evaluate and choose counterfactual policies for their own practical situations.
The distinctive features of OPE/OPS modules of SCOPE-RL are summarized as follows.
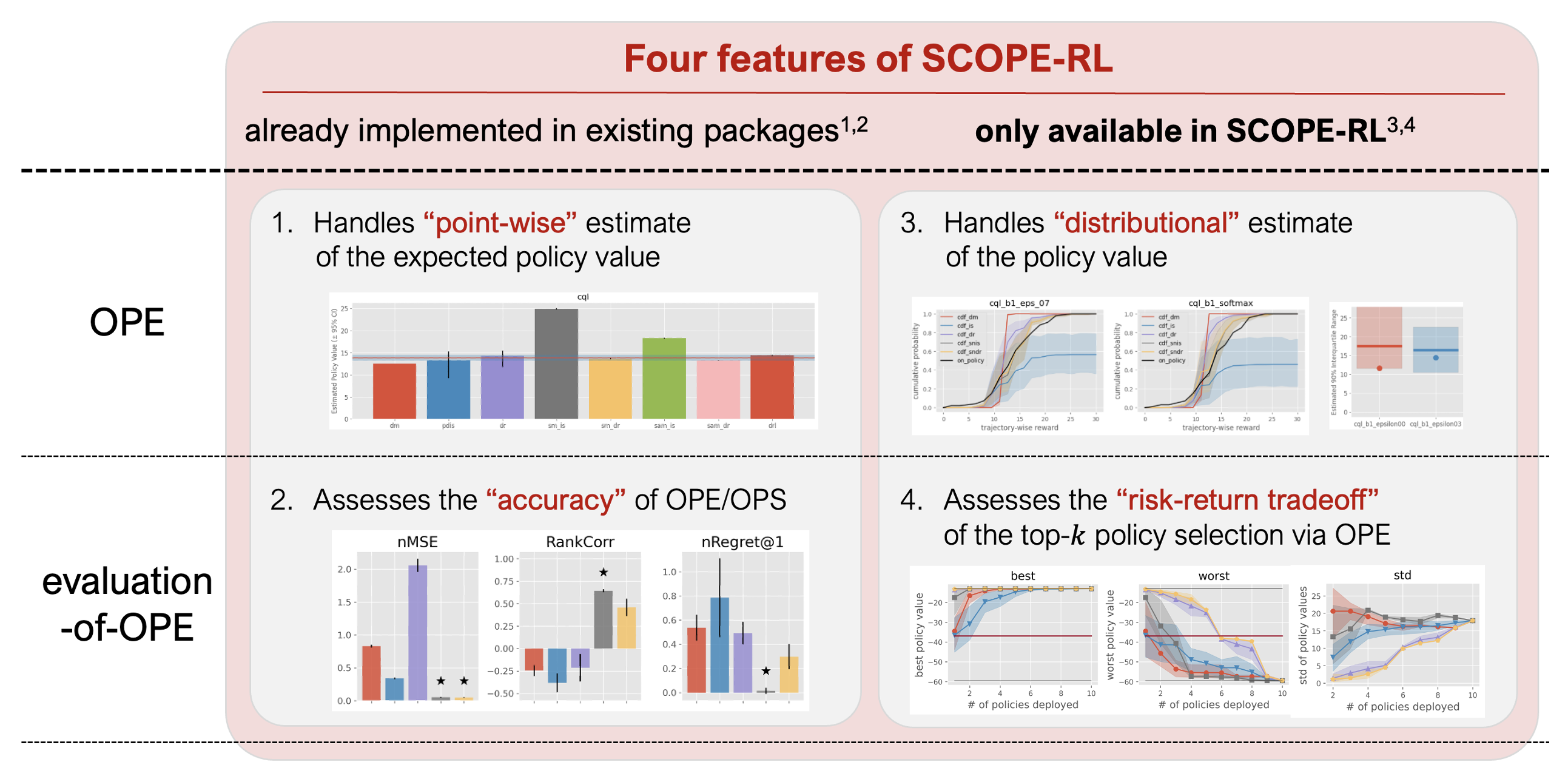
Four distinctive features of OPE/OPS implementation of SCOPE-RL
To provide an example of performing a customized experiment imitating a practical setup, we also provide RTBGym and RecGym, RL environments for Real-Time Bidding (RTB) and Recommender Systems.
You can install SCOPE-RL using Python's package manager pip.
pip install scope-rl
You can also install SCOPE-RL from the source.
git clone https://github.com/hakuhodo-technologies/scope-rl
cd scope-rl
python setup.py installSCOPE-RL supports Python 3.9 or newer. See requirements.txt for other requirements. Please also refer to issue #17 when you encounter some dependency conflicts.
Here, we provide an example workflow to perform offline RL, OPE, and OPS using SCOPE-RL on RTBGym.
Let's start by generating some synthetic logged data useful for performing offline RL.
# implement a data collection procedure on the RTBGym environment
# import SCOPE-RL modules
from scope_rl.dataset import SyntheticDataset
from scope_rl.policy import EpsilonGreedyHead
# import d3rlpy algorithms
from d3rlpy.algos import DoubleDQNConfig
from d3rlpy.dataset import create_fifo_replay_buffer
from d3rlpy.algos import ConstantEpsilonGreedy
# import rtbgym and gym
import rtbgym
import gym
import torch
# random state
random_state = 12345
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# (0) Setup environment
env = gym.make("RTBEnv-discrete-v0")
# (1) Learn a baseline policy in an online environment (using d3rlpy)
# initialize the algorithm
ddqn = DoubleDQNConfig().create(device=device)
# train an online policy
# this takes about 5min to compute
ddqn.fit_online(
env,
buffer=create_fifo_replay_buffer(limit=10000, env=env),
explorer=ConstantEpsilonGreedy(epsilon=0.3),
n_steps=100000,
n_steps_per_epoch=1000,
update_start_step=1000,
)
# (2) Generate a logged dataset
# convert the ddqn policy into a stochastic behavior policy
behavior_policy = EpsilonGreedyHead(
ddqn,
n_actions=env.action_space.n,
epsilon=0.3,
name="ddqn_epsilon_0.3",
random_state=random_state,
)
# initialize the dataset class
dataset = SyntheticDataset(
env=env,
max_episode_steps=env.step_per_episode,
)
# the behavior policy collects some logged data
train_logged_dataset = dataset.obtain_episodes(
behavior_policies=behavior_policy,
n_trajectories=10000,
random_state=random_state,
)
test_logged_dataset = dataset.obtain_episodes(
behavior_policies=behavior_policy,
n_trajectories=10000,
random_state=random_state + 1,
)We are now ready to learn a new policy (evaluation policy) from the logged data using d3rlpy.
# implement an offline RL procedure using SCOPE-RL and d3rlpy
# import d3rlpy algorithms
from d3rlpy.dataset import MDPDataset
from d3rlpy.algos import DiscreteCQLConfig
# (3) Learning a new policy from offline logged data (using d3rlpy)
# convert the logged dataset into d3rlpy's dataset format
offlinerl_dataset = MDPDataset(
observations=train_logged_dataset["state"],
actions=train_logged_dataset["action"],
rewards=train_logged_dataset["reward"],
terminals=train_logged_dataset["done"],
)
# initialize the algorithm
cql = DiscreteCQLConfig().create(device=device)
# train an offline policy
cql.fit(
offlinerl_dataset,
n_steps=10000,
)Then, we evaluate the performance of several evaluation policies (ddqn, cql, and random) using offline logged data collected by the behavior policy. Specifically, we compare the estimation results of various OPE estimators, including Direct Method (DM), Trajectory-wise Importance Sampling (TIS), Per-Decision Importance Sampling (PDIS), and Doubly Robust (DR) below.
# implement a basic OPE procedure using SCOPE-RL
# import SCOPE-RL modules
from scope_rl.ope import CreateOPEInput
from scope_rl.ope import OffPolicyEvaluation as OPE
from scope_rl.ope.discrete import DirectMethod as DM
from scope_rl.ope.discrete import TrajectoryWiseImportanceSampling as TIS
from scope_rl.ope.discrete import PerDecisionImportanceSampling as PDIS
from scope_rl.ope.discrete import DoublyRobust as DR
# (4) Evaluate the learned policy in an offline manner
# we compare ddqn, cql, and random policy
cql_ = EpsilonGreedyHead(
base_policy=cql,
n_actions=env.action_space.n,
name="cql",
epsilon=0.0,
random_state=random_state,
)
ddqn_ = EpsilonGreedyHead(
base_policy=ddqn,
n_actions=env.action_space.n,
name="ddqn",
epsilon=0.0,
random_state=random_state,
)
random_ = EpsilonGreedyHead(
base_policy=ddqn,
n_actions=env.action_space.n,
name="random",
epsilon=1.0,
random_state=random_state,
)
evaluation_policies = [cql_, ddqn_, random_]
# create input for the OPE class
prep = CreateOPEInput(
env=env,
)
input_dict = prep.obtain_whole_inputs(
logged_dataset=test_logged_dataset,
evaluation_policies=evaluation_policies,
require_value_prediction=True,
n_trajectories_on_policy_evaluation=100,
random_state=random_state,
)
# initialize the OPE class
ope = OPE(
logged_dataset=test_logged_dataset,
ope_estimators=[DM(), TIS(), PDIS(), DR()],
)
# perform OPE and visualize the result
ope.visualize_off_policy_estimates(
input_dict,
random_state=random_state,
sharey=True,
)
Policy Value Estimated by OPE Estimators
More formal example implementations with RTBGym are available at ./examples/quickstart/rtb/. Those with RecGym are also available at ./examples/quickstart/rec/.
We can also estimate various statics of the evaluation policy, beyond just its expected performance, including variance and conditional value at risk (CVaR) via estimating the cumulative distribution function (CDF) of the reward under the evaluation policy.
# implement a cumulative distribution estimation procedure using SCOPE-RL
# import SCOPE-RL modules
from scope_rl.ope import CumulativeDistributionOPE
from scope_rl.ope.discrete import CumulativeDistributionDM as CD_DM
from scope_rl.ope.discrete import CumulativeDistributionTIS as CD_IS
from scope_rl.ope.discrete import CumulativeDistributionTDR as CD_DR
from scope_rl.ope.discrete import CumulativeDistributionSNTIS as CD_SNIS
from scope_rl.ope.discrete import CumulativeDistributionSNTDR as CD_SNDR
# (4) Evaluate the cumulative distribution function of the reward under the evaluation policy (in an offline manner)
# we compare ddqn, cql, and random policy defined from the previous section (i.e., (3) of basic OPE procedure)
# initialize the OPE class
cd_ope = CumulativeDistributionOPE(
logged_dataset=test_logged_dataset,
ope_estimators=[
CD_DM(estimator_name="cd_dm"),
CD_IS(estimator_name="cd_is"),
CD_DR(estimator_name="cd_dr"),
CD_SNIS(estimator_name="cd_snis"),
CD_SNDR(estimator_name="cd_sndr"),
],
)
# estimate the variance
variance_dict = cd_ope.estimate_variance(input_dict)
# estimate the CVaR
cvar_dict = cd_ope.estimate_conditional_value_at_risk(input_dict, alphas=0.3)
# estimate and visualize the cumulative distribution function of the policy performance
cd_ope.visualize_cumulative_distribution_function(input_dict, n_cols=4)
Cumulative Distribution Function Estimated by OPE Estimators
For more extensive examples, please refer to quickstart/rtb/rtb_synthetic_discrete_advanced.ipynb.
We can also select the best-performing policy among a set of candidate policies based on the OPE results using the OPS class. It is also possible to evaluate the reliability of OPE/OPS using various metrics such as mean squared error, rank correlation, regret, and type I and type II error rates.
# perform off-policy selection based on the OPE results
# import SCOPE-RL modules
from scope_rl.ope import OffPolicySelection
# (5) Conduct Off-Policy Selection
# Initialize the OPS class
ops = OffPolicySelection(
ope=ope,
cumulative_distribution_ope=cd_ope,
)
# rank the candidate policies by their policy value estimated by (basic) OPE
ranking_dict = ops.select_by_policy_value(input_dict)
# rank the candidate policies by their policy value estimated by cumulative distribution OPE
ranking_dict_ = ops.select_by_policy_value_via_cumulative_distribution_ope(input_dict)
# visualize the top k deployment result
ops.visualize_topk_policy_value_selected_by_standard_ope(
input_dict=input_dict,
compared_estimators=["dm", "tis", "pdis", "dr"],
relative_safety_criteria=1.0,
)
Comparison of the Top-k Statistics of 10% Lower Quartile of Policy Value
# (6) Evaluate the OPS/OPE results
# rank the candidate policies by their estimated lower quartile and evaluate the selection results
ranking_df, metric_df = ops.select_by_lower_quartile(
input_dict,
alpha=0.3,
return_metrics=True,
return_by_dataframe=True,
)
# visualize the OPS results with the ground-truth metrics
ops.visualize_conditional_value_at_risk_for_validation(
input_dict,
alpha=0.3,
share_axes=True,
)
Validation of Estimated and Ground-truth Variance of Policy Value
For more examples, please refer to quickstart/rtb/rtb_synthetic_discrete_advanced.ipynb for discrete actions and quickstart/rtb/rtb_synthetic_continuous_advanced.ipynb for continuous actions.
If you use our software in your work, please cite our paper:
Haruka Kiyohara, Ren Kishimoto, Kosuke Kawakami, Ken Kobayashi, Kazuhide Nakata, Yuta Saito.
SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation
[arXiv] [slides]
Bibtex:
@article{kiyohara2023scope,
author = {Kiyohara, Haruka and Kishimoto, Ren and Kawakami, Kosuke and Kobayashi, Ken and Nataka, Kazuhide and Saito, Yuta},
title = {SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation},
journal={arXiv preprint arXiv:2311.18206},
year={2023},
}
If you use our proposed metric "SharpeRatio@k" in your work, please cite our paper:
Haruka Kiyohara, Ren Kishimoto, Kosuke Kawakami, Ken Kobayashi, Kazuhide Nakata, Yuta Saito.
Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation
[arXiv] [slides]
Bibtex:
@article{kiyohara2023towards,
author = {Kiyohara, Haruka and Kishimoto, Ren and Kawakami, Kosuke and Kobayashi, Ken and Nataka, Kazuhide and Saito, Yuta},
title = {Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation},
journal={arXiv preprint arXiv:2311.18207},
year={2023},
}
If you are interested in SCOPE-RL, please follow its updates via the google group: https://groups.google.com/g/scope-rl
Any contributions to SCOPE-RL are more than welcome! Please refer to CONTRIBUTING.md for general guidelines on how to contribute to the project.
This project is licensed under Apache 2.0 license - see LICENSE file for details.
- Haruka Kiyohara (Main Contributor; Cornell University)
- Ren Kishimoto (Tokyo Institute of Technology)
- Kosuke Kawakami (HAKUHODO Technologies Inc.)
- Ken Kobayashi (Tokyo Institute of Technology)
- Kazuhide Nakata (Tokyo Institute of Technology)
- Yuta Saito (Cornell University)
For any questions about the paper and software, feel free to contact: hk844@cornell.edu
Papers (click to expand)
-
Alina Beygelzimer and John Langford. The Offset Tree for Learning with Partial Labels. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 129-138, 2009.
-
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. OpenAI Gym. arXiv preprint arXiv:1606.01540, 2016.
-
Yash Chandak, Scott Niekum, Bruno Castro da Silva, Erik Learned-Miller, Emma Brunskill, and Philip S. Thomas. Universal Off-Policy Evaluation. In Advances in Neural Information Processing Systems, 2021.
-
Miroslav Dudík, Dumitru Erhan, John Langford, and Lihong Li. Doubly Robust Policy Evaluation and Optimization. In Statistical Science, 485-511, 2014.
-
Justin Fu, Mohammad Norouzi, Ofir Nachum, George Tucker, Ziyu Wang, Alexander Novikov, Mengjiao Yang, Michael R. Zhang, Yutian Chen, Aviral Kumar, Cosmin Paduraru, Sergey Levine, and Tom Le Paine. Benchmarks for Deep Off-Policy Evaluation. In International Conference on Learning Representations, 2021.
-
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the 35th International Conference on Machine Learning, 1861-1870, 2018.
-
Josiah P. Hanna, Peter Stone, and Scott Niekum. Bootstrapping with Models: Confidence Intervals for Off-Policy Evaluation. In Proceedings of the 31th AAAI Conference on Artificial Intelligence, 2017.
-
Hado van Hasselt, Arthur Guez, and David Silver. Deep Reinforcement Learning with Double Q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, 2094-2100, 2015.
-
Audrey Huang, Liu Leqi, Zachary C. Lipton, and Kamyar Azizzadenesheli. Off-Policy Risk Assessment in Contextual Bandits. In Advances in Neural Information Processing Systems, 2021.
-
Audrey Huang, Liu Leqi, Zachary C. Lipton, and Kamyar Azizzadenesheli. Off-Policy Risk Assessment for Markov Decision Processes. In Proceedings of the 25th International Conference on Artificial Intelligence and Statistics, 5022-5050, 2022.
-
Nan Jiang and Lihong Li. Doubly Robust Off-policy Value Evaluation for Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, 652-661, 2016.
-
Nathan Kallus and Masatoshi Uehara. Intrinsically Efficient, Stable, and Bounded Off-Policy Evaluation for Reinforcement Learning. In Advances in Neural Information Processing Systems, 3325-3334, 2019.
-
Nathan Kallus and Masatoshi Uehara. Double Reinforcement Learning for Efficient Off-Policy Evaluation in Markov Decision Processes. In Journal of Machine Learning Research, 167, 2020.
-
Nathan Kallus and Angela Zhou. Policy Evaluation and Optimization with Continuous Treatments. In Proceedings of the 21st International Conference on Artificial Intelligence and Statistics, 1243-1251, 2019.
-
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative Q-Learning for Offline Reinforcement Learning. In Advances in Neural Information Processing Systems, 1179-1191, 2020.
-
Vladislav Kurenkov and Sergey Kolesnikov. Showing Your Offline Reinforcement Learning Work: Online Evaluation Budget Matters. In Proceedings of the 39th International Conference on Machine Learning, 11729--11752, 2022.
-
Hoang Le, Cameron Voloshin, and Yisong Yue. Batch Policy Learning under Constraints. In Proceedings of the 36th International Conference on Machine Learning, 3703-3712, 2019.
-
Haanvid Lee, Jongmin Lee, Yunseon Choi, Wonseok Jeon, Byung-Jun Lee, Yung-Kyun Noh, and Kee-Eung Kim. Local Metric Learning for Off-Policy Evaluation in Contextual Bandits with Continuous Actions. In Advances in Neural Information Processing Systems, xxxx-xxxx, 2022.
-
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems. arXiv preprint arXiv:2005.01643, 2020.
-
Qiang Liu, Lihong Li, Ziyang Tang, and Dengyong Zhou. Breaking the Curse of Horizon: Infinite-Horizon Off-Policy Estimation. In Advances in Neural Information Processing Systems, 2018.
-
Ofir Nachum, Yinlam Chow, Bo Dai, and Lihong Li. DualDICE: Behavior-Agnostic Estimation of Discounted Stationary Distribution Corrections. In Advances in Neural Information Processing Systems, 2019.
-
Ofir Nachum, Bo Dai, Ilya Kostrikov, Yinlam Chow, Lihong Li, and Dale Schuurmans. AlgaeDICE: Policy Gradient from Arbitrary Experience. arXiv preprint arXiv:1912.02074, 2019.
-
Tom Le Paine, Cosmin Paduraru, Andrea Michi, Caglar Gulcehre, Konrad Zolna, Alexander Novikov, Ziyu Wang, and Nando de Freitas. Hyperparameter Selection for Offline Reinforcement Learning. arXiv preprint arXiv:2007.09055, 2020.
-
Doina Precup, Richard S. Sutton, and Satinder P. Singh. Eligibility Traces for Off-Policy Policy Evaluation. In Proceedings of the 17th International Conference on Machine Learning, 759–766, 2000.
-
Rafael Figueiredo Prudencio, Marcos R. O. A. Maximo, and Esther Luna Colombini. A Survey on Offline Reinforcement Learning: Taxonomy, Review, and Open Problems. arXiv preprint arXiv:2203.01387, 2022.
-
Yuta Saito, Shunsuke Aihara, Megumi Matsutani, and Yusuke Narita. Open Bandit Dataset and Pipeline: Towards Realistic and Reproducible Off-Policy Evaluation. In Advances in Neural Information Processing Systems, 2021.
-
Takuma Seno and Michita Imai. d3rlpy: An Offline Deep Reinforcement Library, arXiv preprint arXiv:2111.03788, 2021.
-
Alex Strehl, John Langford, Sham Kakade, and Lihong Li. Learning from Logged Implicit Exploration Data. In Advances in Neural Information Processing Systems, 2217-2225, 2010.
-
Adith Swaminathan and Thorsten Joachims. The Self-Normalized Estimator for Counterfactual Learning. In Advances in Neural Information Processing Systems, 3231-3239, 2015.
-
Shengpu Tang and Jenna Wiens. Model Selection for Offline Reinforcement Learning: Practical Considerations for Healthcare Settings. In,Proceedings of the 6th Machine Learning for Healthcare Conference, 2-35, 2021.
-
Philip S. Thomas and Emma Brunskill. Data-Efficient Off-Policy Policy Evaluation for Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, 2139-2148, 2016.
-
Philip S. Thomas, Georgios Theocharous, and Mohammad Ghavamzadeh. High Confidence Off-Policy Evaluation. In Proceedings of the 9th AAAI Conference on Artificial Intelligence, 2015.
-
Philip S. Thomas, Georgios Theocharous, and Mohammad Ghavamzadeh. High Confidence Policy Improvement. In Proceedings of the 32nd International Conference on Machine Learning, 2380-2388, 2015.
-
Masatoshi Uehara, Jiawei Huang, and Nan Jiang. Minimax Weight and Q-Function Learning for Off-Policy Evaluation. In Proceedings of the 37th International Conference on Machine Learning, 9659--9668, 2020.
-
Masatoshi Uehara, Chengchun Shi, and Nathan Kallus. A Review of Off-Policy Evaluation in Reinforcement Learning. arXiv preprint arXiv:2212.06355, 2022.
-
Mengjiao Yang, Ofir Nachum, Bo Dai, Lihong Li, and Dale Schuurmans. Off-Policy Evaluation via the Regularized Lagrangian. In Advances in Neural Information Processing Systems, 6551--6561, 2020.
-
Christina J. Yuan, Yash Chandak, Stephen Giguere, Philip S. Thomas, and Scott Niekum. SOPE: Spectrum of Off-Policy Estimators. In Advances in Neural Information Processing Systems, 18958--18969, 2022.
-
Shangtong Zhang, Bo Liu, and Shimon Whiteson. GradientDICE: Rethinking Generalized Offline Estimation of Stationary Values. In Proceedings of the 37th International Conference on Machine Learning, 11194--11203, 2020.
-
Ruiyi Zhang, Bo Dai, Lihong Li, and Dale Schuurmans. GenDICE: Generalized Offline Estimation of Stationary Values. In International Conference on Learning Representations, 2020.
Projects (click to expand)
This project is strongly inspired by the following three packages.
- Open Bandit Pipeline -- a pipeline implementation of OPE in contextual bandits: [github] [documentation] [paper]
- d3rlpy -- a set of implementations of offline RL algorithms: [github] [documentation] [paper]
- Spinning Up -- an educational resource for learning deep RL: [github] [documentation]