Transaction Serialization
To construct the next block, the leader node would dequeue transactions from the txqueue till either the block size limit is reached, or the txqueue has become empty. In the same dequeued order, the transaction would be added to the block. Here, there is no unfairness to clients.
Similar to the FIFO_ORDER, the leader would dequeue transaction from txqueue. However, before putting these transactions into a block, it does reorder them based on the dependency to reduce the validation failures. Towards achieving this, we define a rw-dependency rule:
rw-dependency rule
- If Ti writes a version of some state and Tj reads the previous version of that state, then we add a rw-depdendency edge from Tj to Ti to denote that the transaction Ti must be validated and committed only after validating/committing the transaction Tj.
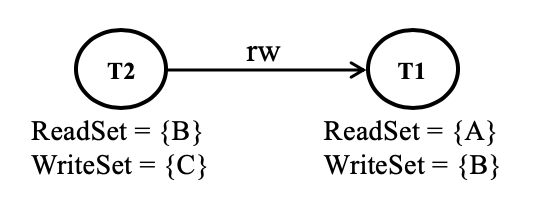
For example, let’s take two transactions T1 and T2:
T1: ReadSet = {A} WriteSet = {B}
T2: ReadSet = {B} WriteSet = {C}Assume that both T1 and T2 are present in the txqueue. There is a rw-dependency between T1 and T2 because T1 writes B while T2 reads B. Hence, we would add a rw-dependency edge from T2 to T1.
Why are we doing so?
If T1 commits first, the T2 would be aborted due to change in the read version of B. However, if T2 commits first, T1 would not be aborted. Hence, we have added an edge from T2 to T1 to denote that T2 must come first in the block ordering before T1 so that we can reduce the number of aborted transactions.
Topological Sort
Once we have constructed a directed dependency graph for a bunch of transactions which are dequeued from the txqueue, we need to run the topological sort on them to find the ordering of transactions to be included in the block to reduce the conflict rates. However, if the directed dependency graph has a cycle, we cannot run topological sorting. Hence, first, we need to detect all occurrences of cycles and remove transactions to break it.
Let’s look at some examples:
Example 1:
T1: ReadSet = {A} WriteSet = {B}
T2: ReadSet = {B} WriteSet = {A}As per our rw-dependency rule, we would get a cycle in the dependency graph as shown below.
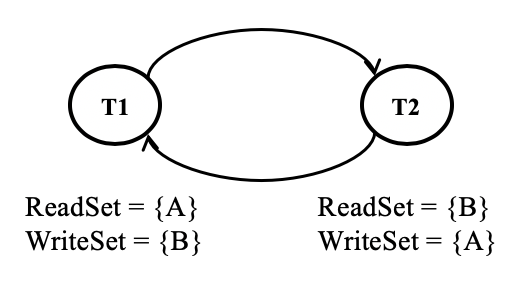
When a cycle occurs, it means that only either of the transaction can become valid. Further, we cannot run topology sort when the graph has a cycle. Hence, we need to break the cycle by aborting a transaction. Early Fail Tx (3) in diagram.
Example 2:
T1: ReadSet = {B} WriteSet = {C}
T2: ReadSet = {A} WriteSet = {B}
T3: ReadSet = {C} WriteSet = {D}The dependency graph for the above set of transactions is shown below:
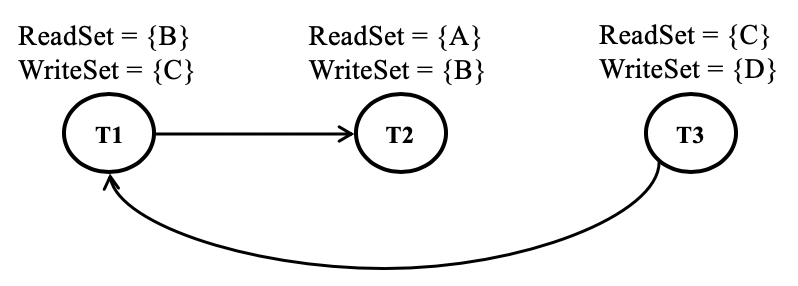
When we add transactions to a block, if we aren't reordering them and instead storing it in the FIFO order, i.e., T1, T2, T3, the transaction T3 would get invalidated by the block processor for sure as the read version of key C would be different from the committed version given that T1 is committed and updated the key C. However, if we run the topology sorting on the dependency graph, we would get T3, T2, and T2 as the order. If we include the transactions in that order in the block, all three transactions would go through (assuming that the committed state is still same as the one read by these transactions).
In both FIFO_ORDER and REORDER_FOR_CONFLICT_REDUCTION, the block processor still needs to validate transaction serially as there is still a dependency between these transactions. However, if we include only non-dependent transactions within a block, the block processor can validate and commit all transactions in parallel.
Let's look at an example:
T1: ReadSet = {B} WriteSet = {C}
T2: ReadSet = {A} WriteSet = {B}
T3: ReadSet = {C} WriteSet = {D}
T4: ReadSet = {E} WriteSet = {G}
T5: ReadSet = {H} WriteSet = {I}The dependency graph for all these five transactions are shown below.
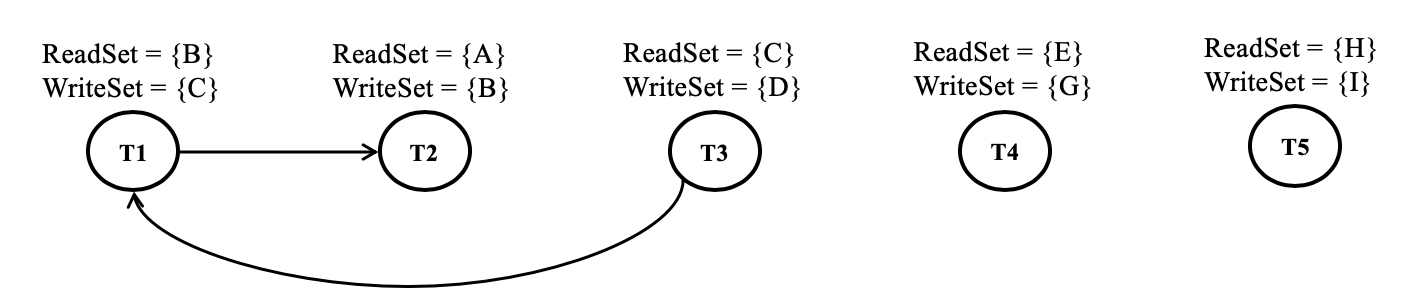
If we decide to either defer T1 or abort T1 early, we can blindly include the rest of the transactions T2, T3, T4, and T5 in any order in the block. The block processor can validate and commit these transactions parallely.
We can also have a mix of dependent transactions and non-dependent transactions in a block to ensure that we reach the block size limit. As a result, our typical block would look like
PARALLEL_VALIDATION {
SERIAL_VALIDATION{T1, T2, T3}
SERIAL_VALIDATION{T7, T9, T11}
T4,
T5,
T6,
T8,
T10
}As a result, the block processor can validate these rows of transaction parallely. Within a row, if there are many transaction with an identifier SERIAL_VALIDATION, then those transactions have to be validated serially. In other words, the block processor would first validate T1, T7, T4, T5, T6, T8, T10 in parallel. Once T1 is validated, the block processor would validate T2 immediately. Similarly, once T7 is validated, the block processor would validate T9 immediately. The same logic is applicable for T3 and T11.
While there is fairness in FIFO_ORDER, in REORDER_FOR_CONFLICT_REDUCTION and MAXIMIZE_PARALLEL_VALIDATION, we tradeoff fairness with performance.