1 Object Detection
The inputs of this stage are the frames of the input feed.
The outputs of this stage are the ROI over the desired objects, detected by deep learning recognition models. These models are optimized by Intel’s OpenVINO Toolkit.
As we attempt to detect near misses in an intersection, we first focused on Vehicles and Pedestrians Detection. We intend to be able to use different combinations of detection models and compare the results.
We researched 2 different approaches:
-
Use a dedicated model for each set of objects (Vehicles, Pedestrians, ..) in parallel.
-
Use a general detection model.
Using dedicated models is supposed to be more time efficient, but the existing detection networks are not detecting consistently on several testing sets.
General detection models, like Yolo v3, are more accurate but still run slow. The trade-off for accuracy is speed. Yolo is currently able to detect up to 80 different objects.
To test the 2 approaches, we created two branches in the repo. We added support for the yolo v3 model to the master branch. In addition, we have added support for other single-model/multiple-object-detection included in the Openvino toolkit. This means that the project supports:
-
Single model - multiple object detection (person-vehicle-bike-detection-crossroad-0078)
-
Dual model - dual object detection (vehicle-detection-adas-0002 and person-detection-retail-0013) this could still be improved to use more models.
-
Yolo v3 detection model.
As mentioned, the start-up point for this project is the STEP 4 of the Car detection tutorial of Intel’s OpenVino Inference.
Milestones:
-
Add PedestriansDetection class (Similar to VehicleDetection class).
-
Delete VehicleAttribsDetection. Not used on this scope.
-
Structural changes on the example workflow. Made a second pipeline to process pedestrian in parallel, using the same input frames as the Vehicle detection class.
-
Change FLAGS to run Pedestrian models.
-
Rewrite Pedestrian and Vehicle class to fit both in a new class, ObjectDetection class.
-
Made changes on BaseDetection to make YoloDetection class inherited from it.
-
YoloDetection class.
-
Made files for each new class (object_detection.hpp, yolo_detection.cpp).
-
Made file for Yolo v3 labels identification.
-
Moved Processing logic from main.cpp to BaseDetection.
Models tested to detect vehicles:
-
vehicle-detection-adas-0002
Models tested to detect pedestrians:
-
person-detection-retail-0013
-
pedestrian-detection-adas-0002
Models tested to detect vehicles and pedestrians:
-
person-vehicle-bike-detection-crossroad-0078
To see how the iference logic is implented on the project see ObjectDetecion class.
To use Yolo and Tiny-Yolo(v3) with the OpenVino Inference Engine, we had to run the model optimizer of the Yolo model. But first, we have to set up the Yolo model:
First, go to a desired folder to clone the Yolo model repository:
git clone https://github.com/mystic123/tensorflow-yolo-v3.git
Then, Download COCO class names file:
wget https://raw.githubusercontent.com/pjreddie/darknet/master/data/coco.names
Download binary file with desired weights:
mkdir weights cd weights wget https://pjreddie.com/media/files/yolov3.weights wget https://pjreddie.com/media/files/yolov3-tiny.weights cd ..
Now run:
mkdir pbmodels python3 convert_weights.py \ --class_names coco.names \ --weights_file weights/yolov3.weights \ --data_format NHWC python3 convert_weights_pb.py \ --class_names coco.names \ --weights_file weights/yolov3.weights \ --data_format NHWC \ --output_graph pbmodels/frozen_yolo_v3.pb python3 convert_weights.py \ --class_names coco.names \ --weights_file weights/yolov3-tiny.weights \ --data_format NHWC \ --tiny python3 convert_weights_pb.py \ --class_names coco.names \ --weights_file weights/yolov3-tiny.weights \ --data_format NHWC \ --tiny \ --output_graph pbmodels/frozen_tiny_yolo_v3.pb
Now we have our 2 .pb files to run Model optimizer.
Be aware to change <PATH-TO-Openvino-For-SmartCity> for your absolute path to that folder.
Then run:
sudo python3 /opt/intel/computer_vision_sdk/deployment_tools/model_optimizer/mo_tf.py \ --input_model pbmodels/frozen_yolo_v3.pb \ --output_dir lrmodels/YoloV3/FP32 \ --data_type FP32 \ --batch 1 \ --tensorflow_use_custom_operations_config <PATH-TO-Openvino-For-SmartCity>/utils/yolo_v3_changed.json sudo python3 /opt/intel/computer_vision_sdk/deployment_tools/model_optimizer/mo_tf.py \ --input_model pbmodels/frozen_yolo_v3.pb \ --output_dir lrmodels/YoloV3/FP16 \ --data_type FP16 \ --batch 1 \ --tensorflow_use_custom_operations_config <PATH-TO-Openvino-For-SmartCity>/utilsyolo_v3_changed.json sudo python3 /opt/intel/computer_vision_sdk/deployment_tools/model_optimizer/mo_tf.py \ --input_model pbmodels/frozen_tiny_yolo_v3.pb \ --output_dir lrmodels/tiny-YoloV3/FP32 \ --data_type FP32 \ --batch 1 \ --tensorflow_use_custom_operations_config <PATH-TO-Openvino-For-SmartCity>/utils/yolo_v3_tiny_changed.json sudo python3 /opt/intel/computer_vision_sdk/deployment_tools/model_optimizer/mo_tf.py \ --input_model pbmodels/frozen_tiny_yolo_v3.pb \ --output_dir lrmodels/tiny-YoloV3/FP16 \ --data_type FP16 \ --batch 1 \ --tensorflow_use_custom_operations_config <PATH-TO-Openvino-For-SmartCity>/utils/yolo_v3_tiny_changed.json
The YoloDetection class implements the logic to run the inference process for that models.
While running vehicle and pedestrian detection in parallel works at ~30fps, the yolov3 model yields results at ~4fps for the 32bits precision model and ~9fps for the 16bits one.
As can be seen on the following videos, yolov3 seems to work better as the detections look smoother and overall better (more objects detected on most frames) but at a slower fps rate. The vehicle and pedestrian models, on the other hand, work +3 times faster but the detections are not constant (they look glitchy). Another problem with the vehicle model is that it detects the cars only when they show part of their front (most cars moving perpendicular to the vision ray are not detected), restricting the perspectives to be used in the video sequences or camera locations. A camera with a perspective as the one shown in the videos would be the best case scenario for detection.
Tiny-yolov3 works extremely fast (~120fps) but fails to recognize most objects. For that reason, evaluations with this model will not be included in the following sections.
-
Vehicle and Pedestrian detection running on CPU (synchronously):
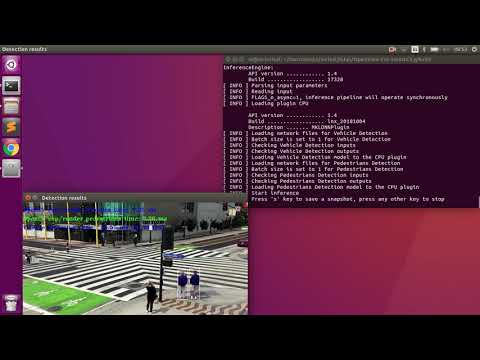
./intel64/Release/smart_city_tutorial -m $mVDR16 -d CPU -m_p $person216 -d_p CPU -i '../data/video1_640x320.mp4' -n_async 1
-
Vehicle and Pedestrian detection running on CPU (asynchronously):
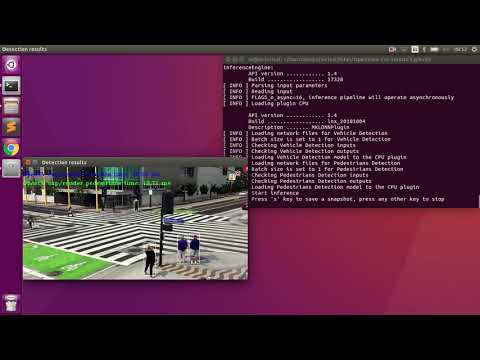
./intel64/Release/smart_city_tutorial -m $mVDR16 -d CPU -m_p $person216 -d_p CPU -i '../data/video1_640x320.mp4' -n_async 16
-
Vehicle and Pedestrian detection running on CPU and GPU:
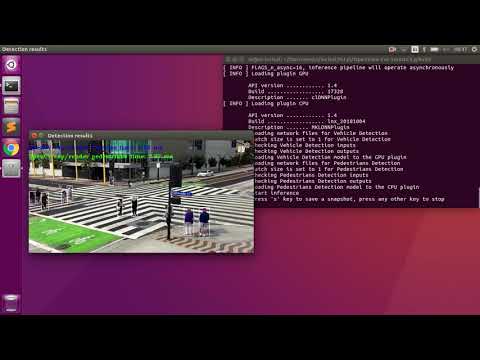
./intel64/Release/smart_city_tutorial -m $mVDR16 -d GPU -m_p $person216 -d_p CPU -i '../data/video1_640x320.mp4' -n_async 16
-
Vehicle and Pedestrian detection running on GPU and MYRIAD:
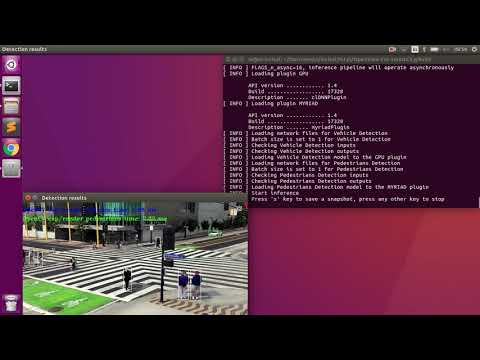
./intel64/Release/smart_city_tutorial -m $mVDR16 -d GPU -m_p $person216 -d_p MYRIAD -i '../data/video1_640x320.mp4' -n_async 16
-
Yolov3 running on GPU (FP16):
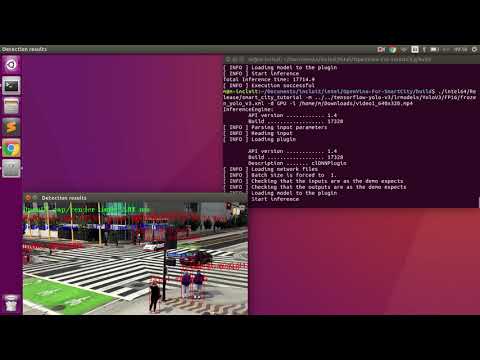
./intel64/Release/smart_city_tutorial -m_y ../../tensorflow-yolo-v3/lrmodels/YoloV3/FP16/frozen_yolo_v3.xml -d_y GPU -i ../data/video1_640x320.mp4