Architecture
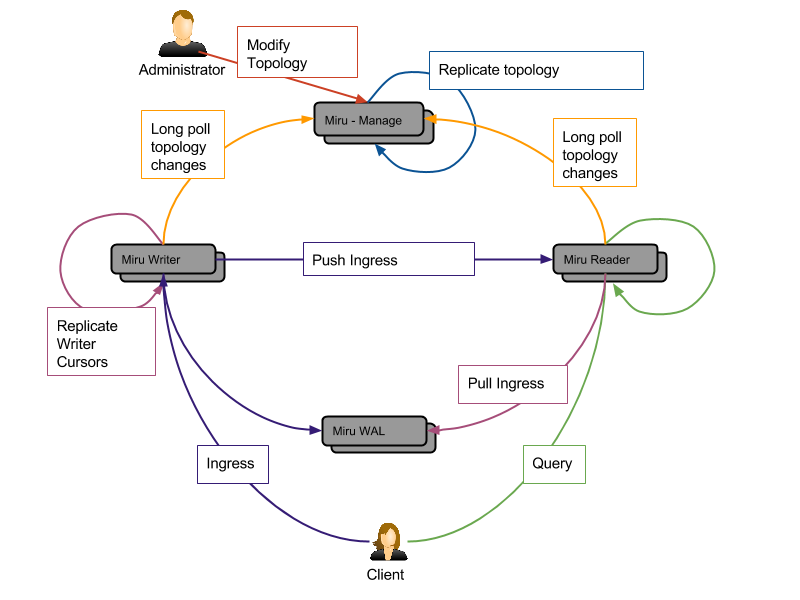
- miru-wal: The system of record for ingressed activities. The WAL stores activity per tenant partition in time ascending order. The typical backing implementation is HBase.
- miru-manage: The system of record for cluster layout, replica sets, and topology (replication status). Backing implementations include HBase as well as Amza.
- miru-writer: The point of ingress for clients. The writer is responsible for recording activities in the WAL and attempting delivery to the reader. The writer maintains cursors for active tenant partitions, which are either up-to-date based on event replication (Amza) or cached for a short period (HBase).
- miru-reader: The point of egress for clients. The reader maintains up-to-date indexes for any replica sets it has been assigned, and serves queries on behalf of any tenant for which it holds a replica.
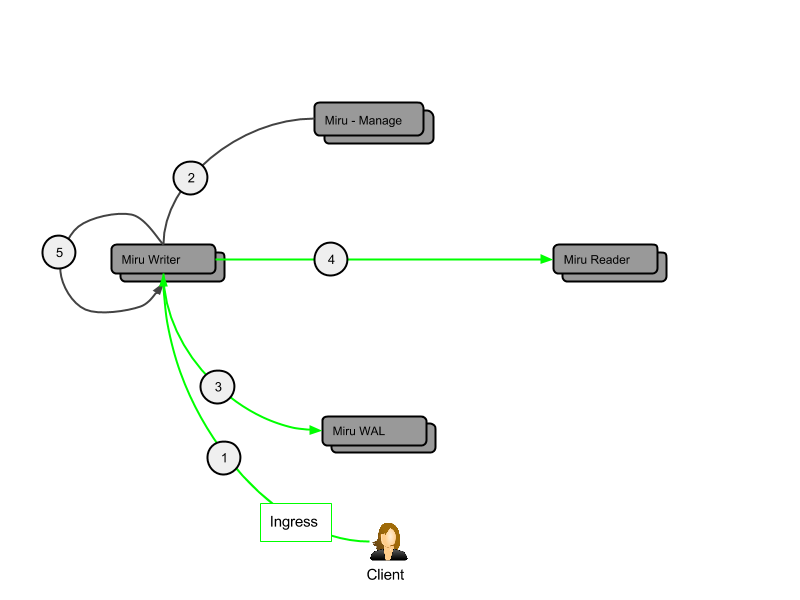
- The client delivers a batch of activity for a specific tenant to miru-writer in a single HTTP request.
- The cursor (active partition) for the ingress tenant is retrieved from miru-manage by miru-writer.
- This cursor is either kept up-to-date (Amza) or cached for a short period (HBase).
- When any miru-writer detects that a partition needs to roll over (due to capacity or age), it advances its cursor to a new partition.
- The miru-writer which performs the partition rollover elects an initial replica set and notifies miru-manage.
- Any sibling miru-writers detect and align themselves to the new partition, either immediately upon event replication (Amza) or after the short cache period has elapsed (HBase).
- Simultaneously, miru-writer fetches the tenant's replica set for the active partition from miru-manage. The replica set is cached and re-fetched periodically.
- The batch of activity is partitioned according to the cursor and written to miru-wal, where it is time-ordered within each tenant partition.
- An attempt is made to deliver the partitioned activity to the miru-readers in the replica set. Failure during this leg is considered acceptable since miru-readers can repair from the WAL (see below).
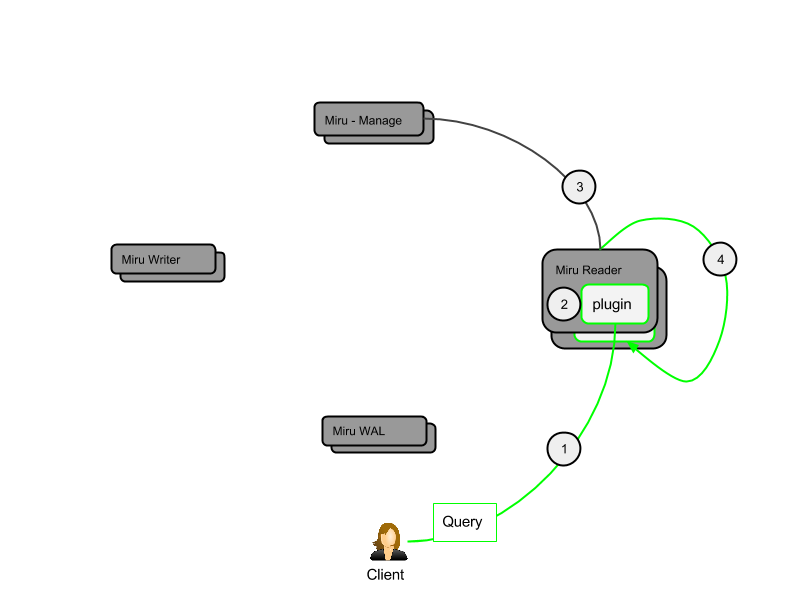
- A client queries miru-reader for a specific tenant using a query plugin (see Plugins).
- A plugin receiver in miru-reader constructs a "solvable" and delegates to the internal query service.
- The tenant topology is fetched from miru-manage in order to route the query. Topology includes online/health status in order to select the ideal route (best replicas) through the topology. The topology is cached locally and fetched in bulk by a background task.
- With an ideal route selected, the primary miru-reader delivers the "solvable" to itself and/or to other miru-readers in the topology. Using 95th percentile failover, the primary miru-reader collects the results and merges them incrementally for each subsequent tenant partition until the query is deemed "solved" and a response is delivered to the client.
Miru's coordination of routing, partition location, and replication is async and convergent. Where a partition should be located and how many times the it is replicated is declared in miru-manage. It is then the responsibility of the cluster to converge according to the declaration. To that end, miru-manage maintains the following declarative tables:
- Hosts: A list of the hosts that should be online to server partitions
- Replication: A mapping of tenant-partition tuples to a list of hosts
- Topology: A mapping of tenant-partition-host tuples to their replication status (offline, rebuilding, online)
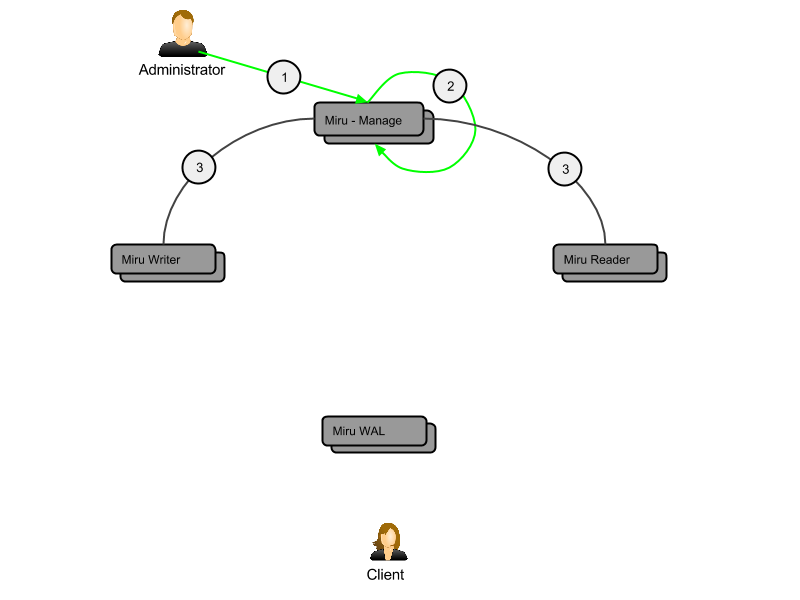
- An administrator effects a manual change to one or more tenant topologies via miru-manage.
- The miru-manage node replicates the change to its siblings.
- Each miru-writer polls miru-manage for the active partition replica set in order to conduct direct delivery of activity ingress. At the same time, each miru-reader polls miru-manage for topology updates, both for routing of queries and for hosting of replicas. As a miru-reader is elected to or demoted from a replica set, it stands up and rebuilds or pushes offline the partition accordingly.
We want updates and read tracking to appear in inboxes for active users as soon as possible, so we rely on a push model (explained above) that is backed up by a pull model. The following diagram shows how the pull mechanism works. This capability, in conjunction with the push model, gives us low latency ingress with fault tolerance.
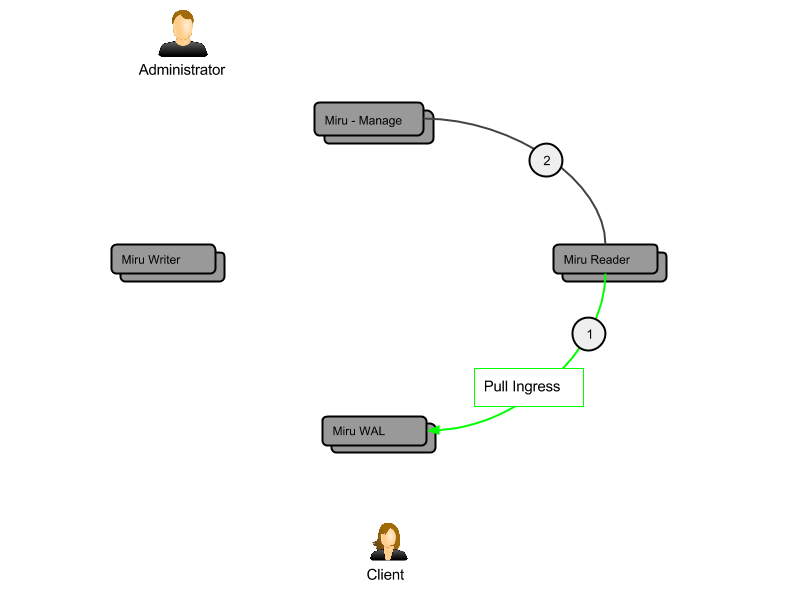
- Each miru-reader pulls from the activity WAL for any of its hosted partitions that are still active (receiving ingress). It applies any changes that may have been missed during miru-writer's best-effort push.
- In the background, each miru-reader polls miru-manage for the list of tenant partitions it needs to serve, and automatically adjusts its hosted partitions accordingly.
Now that we have a clear understanding of how "Push backed up by Pull" works, let’s look at how it addresses failure cases.
- HBase region is down
- Client cannot send new activities
- Client cannot add activities to the WAL
- Client can only route queries to last known (cached) partition topology
- One or more services are down, in a full GC, or unable to keep up with ingress
- Client cannot forward events to downed services; however, downed, garbage collecting, or drowning services will catch up from the activity WAL
Currently, HBase is used as the system of record for all activities across all tenants and their partitions. These activities are write-time partitioned and stored in activity timestamp order. Miru maintains a separate record (in HBase or an alternative durable, HA store) which maps tenant ID and time-ordered partition ID to a list of hosts (its replica set).
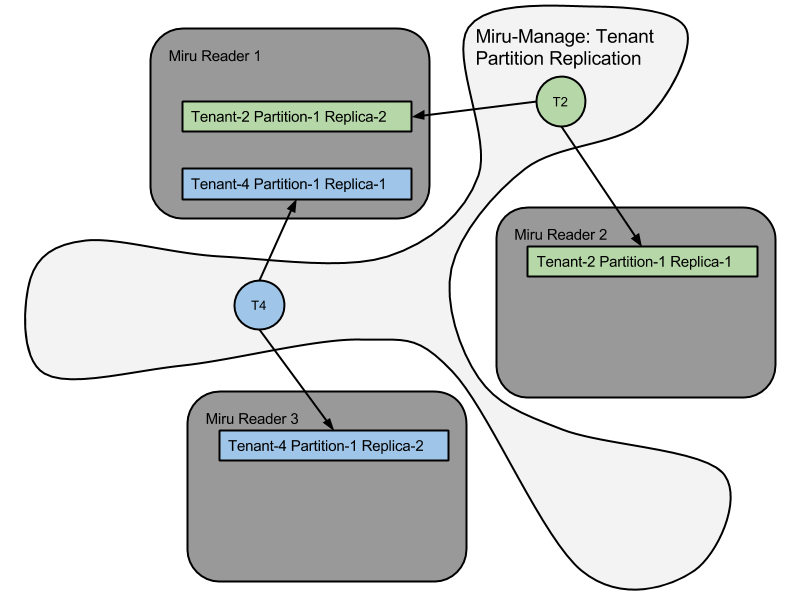
Miru indexes are both partitioned and replicated. Partitioning the index based on time lets us spread large customers across multiple nodes. High availability is solved by replicating partitions across nodes.
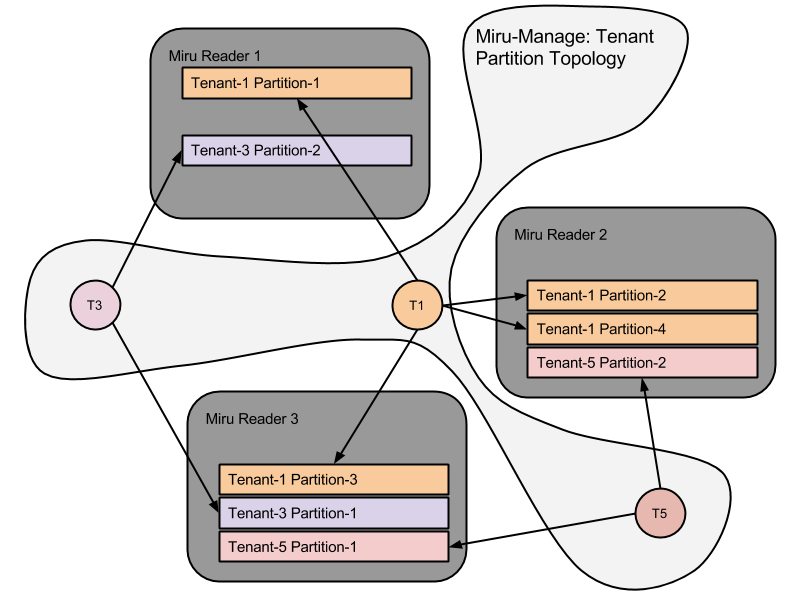
Both problems are chiefly addressed by maintaining an ordered index per tenant. These indexes are further partitioned based on the number of activities. All tenants are given partitions with the same activity capacity. This uniform unit of capacity gives us the ability to move partitions around with a relatively stable understanding of cost that is agnostic of the tenant. Once a particular tenant fills up its active partition, the tenant is rolled over into a new active partition which is randomly elected and replicated within the cluster.
Query loads to these partitions can still be unbalanced. This is where the random distribution of small and large customers ideally balance each other out. In cases where this random distribution is not sufficient in balancing load, or there is an exacting requirement for high SLA or a security-sensitive customer, we need to be able to either increase the number of replicas or manually move replicas to other nodes. The Miru architecture supports both requirements. The following diagrams shows how tenants are spread around a three-node cluster from both a partition distribution and replication perspective.