Introduction
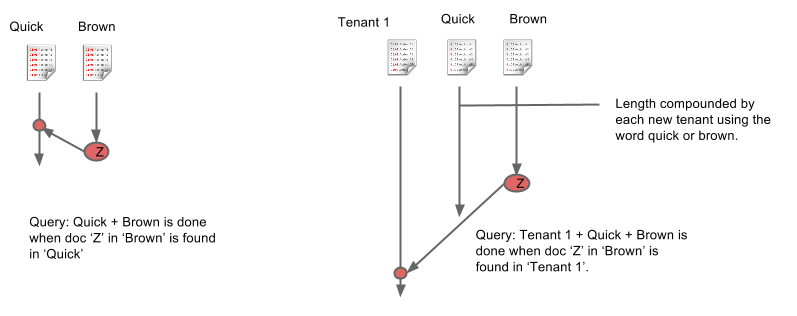
First of all, there are multiple well known open source projects which provide sharding and replication on top of lucene. Jive has or is using SenseiDB, Solar, Katta, and ElasticSearch They work - but the thing is, none of them fit our needs well as we might like. For example cramming multi-tenancy into them by using a field for the tenant id and including it as a filter in every search. Our tenants range in size from from 10s to 100s of thousands and since they all shared the same indexes searching for the smallest tenant took was just expensive as searching for the largest tenants. Including the tenant field forces every search to traverse to the end of each fields index because the longest index in every query if for the tenant id.
Open Source search solutions lack the concept of Tenancy which adds to latency because a query is done when the last item in the shortest inverted index has been found in the longest inverted index.
- handle out of order updates
- handle partial document updates
- isolate tenants and scale them individually
- expand and contract capacity to support more or less queries per second on a per tenant basis.
- expand and contract partitions for a given tenant.
- move a specific tenant off of an overloaded node.
- remove a tenant without having to rebuild the entire index.
- merge and split a given tenants partitions to adjust to node size.
- track index traits on a per tenant basis.
- support field by field updates
- support per tenant doc frequence. (roadmap)