Introduction
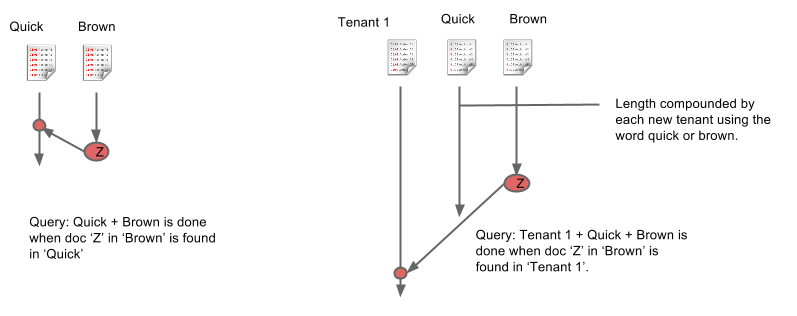
There are several well known open source projects which provide sharding and replication on top of Lucene. Jive has used or is currently using SenseiDB, Solar, Katta, and ElasticSearch. They work, but none of them are a good fit for multi-tenant datasets. For example, adding multi-tenancy through use of a "tenant ID" field filter in every query has inherent performance implications. Our tenants range in size from from tens to hundreds of thousands of users, and by sharing the same indexes we find ourselves in a situation where searching the smallest tenant incurs the same cost as searching the largest tenant. By including a tenant field we force every search to traverse to the end of each field index, because the tenant always constitutes the longest index.
Put simply, current open source search solutions lack any notion of tenancy. This shortcoming adds to latency because a query is only complete when the last item in the shortest inverted index has been found in the longest inverted index.
Here is a short list of features that existing technologies do not support that Miru provides:
- Handle out of order updates (e.g. deletion received before creation) (per-document version order)
- Handle partial document updates
- Isolate tenants and scale them individually
- Expand or contract capacity to support additional or fewer queries per second on a per-tenant basis
- Expand or contract partitions for a given tenant
- Move a specific tenant off of an overloaded node
- Remove a tenant without having to rebuild the entire index
- Merge and split a given tenants partitions to adjust to node size
- Track index traits per tenant
- Support field by field updates
- Support document term frequency per tenant (Miru roadmap)
In the process of digging through Lucene and its index data structures it was immediately apparent how much of Lucene and other Lucene-backed technologies are built around scoring. Scoring makes a lot of sense when you have a large number of items that are intrinsically unordered. However, this is not the case with streams, where documents are always viewed in time-descending order.
If you remove all of the scoring concerns from Lucene you are left with bitsets and the ability to combine them using boolean operations (AND, OR, AND NOT, etc.). To mirror this capability, we found and focused our efforts on a pair of compressed bitmap libraries: JavaEWAH and Roaring Bitmap. With these libraries at our disposal, we had the necessary foundation to build a bit collider for inverted indexes. Now all that was left was to write something that manages partitioning and replication of all these bits sets. That something became Miru.
Miru kept the following use cases in mind:
- The ability to dynamically follow 100,000+ people, places, and/or content (aka followables). A grouping of followable things is called a stream. Streams have a further distinction of being either a “Custom Stream” or an “Inbox.”
- The ability for each user to have an “Inbox” stream which durably records what has happened to its followable things.
- The ability to maintain a per user record of what has or has not been read within a given user's “Inbox” stream.
- The ability to aggregate all activities around a give followable down to one displayable entity.
- The ability to filter streams by tags, author, type, etc.
- The ability to count the number of aggregate activities on a followable that have happened since a point in time within a given stream.
- The ability to only return results which a given user is authorized to see.
- The ability to perform full-text searches of streams.