Here our aim is to enhance the image quality in the image dataset that we are dealing with. For a comprehensive list of datasets, refer to this linkedin post by me. Following are few approaches that can be used :
- Normalizing Image : Convert pixel values from 0-255 to 0-1 range
- Illumination Correction : Various methods available, choose based on project requirements and previous research
- Handling Noise
- Duplicate Image Removal : Check if there are duplicate images or not (both exact and near duplicates) and remove if any
- Remove blurry images
- Remove images with unusual aspect ratios
- Resize images with odd dimensions : Check if there are images with odd size, if yes then resize them
- Remove low-information images
Note : In NLP we already saw when to use freeze learning / partial finetuning / complete finetuning, same logic also applies here!!
-
Object Classification
- Say we have a small dataset of images on which we need to perform object classification task.
- Since majority of the foundation models are built on this task we dont need to finetune the foundation models, instead we will just extract the last layer representation from the foundation model
- Now we will pass this representation to any classification model like KNN / Logistic Regression / Naive Bayes / FLDA / SVM / Decision Tree / … / Neural Network to perform the classification.
- Here is a code implementation using Neural Network!!
-
Object Localization / Image Classification + Localization Task
-
Instance Segmentation / Simultaneous Detection and Segmentation (SDS) Task :
- This is an advanced form of object detection task, in object detection task you just made bounding boxes but here you can make exact outline of the object
- Check out this image here
-
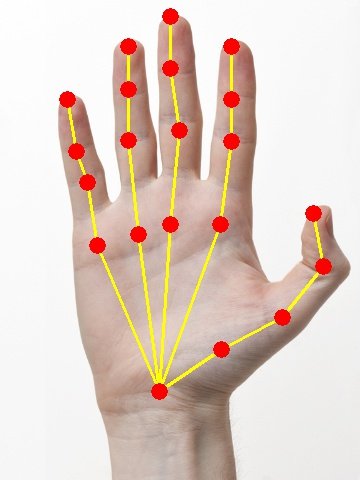
Single Human Key-Point Detection / Pose Estimation Task :
- Problem Statement : Represent a person by K points. Most of the time K =14 cause almost everyone has 14 joints. Refer this image here.
- Solution Architecture :
- This is very similar to Image Classification Architecture just that in the output layer you add 14*2 neurons representing coordinates of all these 14 joints. Refer architecture diagram here
- Instead of classification this is a regression problem hence loss function = Regression Loss = L2 Loss
- If you change the dataset this same approach can also be used for other similar tasks like Face Mesh Detection / Hand Detection
-
Multiple Human Key Point Detection Task :
- Same as above single human key point detection problem just that here we have multiple persons and for each person you need to do key point detection.
- Now during test time you will not know how many people will be there in the image. There can be 5 / 10 / 1000, we saw this similar kind of issue in case of object detection tasks.
- Hence use the same strategy as used in the Object Detection task to solve this issue here.
-
Photo Optical Camera Recognition (OCR) Task
-
Problem Statement : Identify the texts present in the image, as shown in image here
-
Solution :
a. Step 1 : Text Bounding Box Detection => Identify the regions in the image which have text using the object detection model. Refer image here
b. Step 2 : Character Segmentation => Now for each of the text region, you need to segment out the character in that text. Refer image here
c. Step 3 : Character Classification => Now for each segmented character you need to run a character classification model. Refer image here
-
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Style Transfer [Image2Image Translation]
- Depth Estimation
- It is a difficult task because it requires the model to understand 3D structure using only 2D images. There are two ways to solve this.
- Non-Learning Based Method: This was used earlier and not used anymore. This required 2 camera setup and hence called stereo pair. This method is called stereo vision.
- Learning-Based Method: This method is SOTA and requires only 1 camera setup. Hence called monocular depth estimation (MDE). There have been many proposed models but the few best models are
- a. MiDas Model (2019)
- b. Depth Anything Model V1 (Early 2024)
- c. Depth Anything Model V2 (Late 2024, SOTA)
There are many types of Deep RL algorithms :
-
Model Free RL Algorithms :
- Value Learning : Methods wherein we learn the policy by learning a value function
- Policy Learning : Methods wherein we learn the policy by learning the policy itself
- Actor Critic / Advantage Actor Critic(A2C) : combining both Value-Learning and Policy-Learning
-
Model Based RL Algorithms : In model free RL algorithms we could solve the RL problem without learning state transition probabilities P(sₜ₊₁|sₜ, aₜ) . But in these model based RL algorithms we will try to learn these state transition probabilities which will help us predict correct actions for a given state. These state transition probabilities are also called transition dynamics / dynamics / models
-
Inverse RL Algorithms : In both the above algorithms we designed our own scalar reward structures but in these algorithms we learn the reward structure automatically
Important
One of the best way to learn more about Deep RL is to use this resource created by OpenAI. Other great resource are these lectures from UCB and for implementation details you can use this github repo. Recently I also discovered this course from HF which is also a great start to Deep Reinforcement Learning
Caution
Above we saw all the implementation using Neural Networks but earlier people used MDPs to model these instead of Neural Networks. Since MDPs were not scalable, Neural Networks became prominent. You can understand this scalability issue here. But if you still want to learn more about how to use RL with MDPs I would recommend watching these IIT Madras Course and then watch this course by David Silver (Google Deepmind). Finally you can read this github book