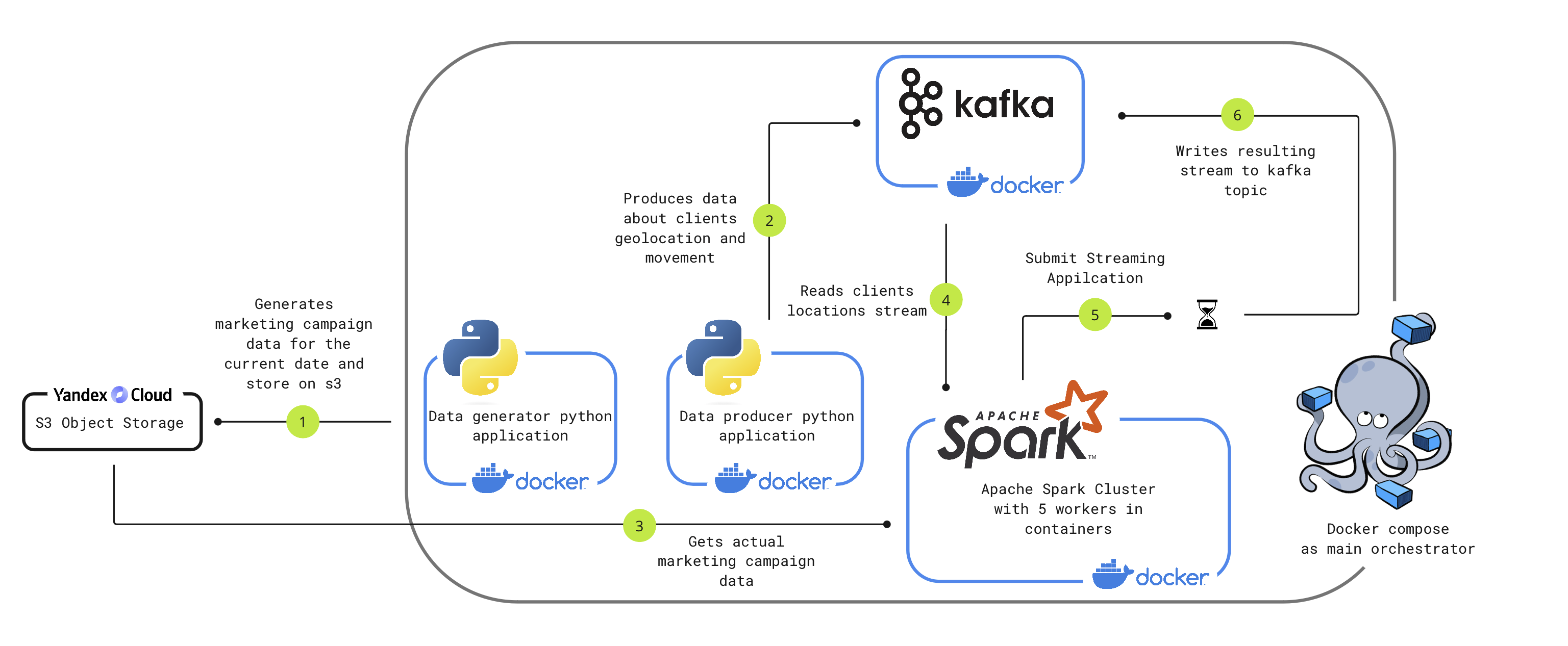
This Project is a simulation of geo-targeted marketing campaigns based on real-time geo-data collected from users devices implemented with Apache Spark Streaming engine and Kafka as main message broker.
The project consist of following key components:
- Marketing Campaign Data Generator. It generates marketing campaign data for the current date, including geolocation information.
- User Geolocation Simulator. This Python application simulates a stream of messages from user devices, encapsulating data about their geolocation and movement. These data are subsequently written to a Kafka topic.
- Apache Spark Streaming Query. This distributed Spark application reads the data stream from the Kafka topic, merges the user movement data with the current marketing campaign data, calculates the distance to each user, and retains only those campaigns that are within a target radius of the user. The processed data is then written back to a Kafka topic for further processing, for example by push-notification service, that can send messages to user about actual marketing actions.
All project's componets should managed by make utility.
To see all available commands make sure you have make already installed on your machine and just type make help.
You will see this manual page:
Usage: make [COMMAND]... [OPTIONS]...
Comands for kafka running in container:
make create-topic topic=<str> Create new topic in kafka cluster
make describe-topic topic=<str> Show descripiton of given topic
make list-topics Show list of all created topics in kafka cluster
kafkacat commands:
make run-producer topic=<str> Run kafkacat in producer mode
make run-consumer topic=<str> Run kafkacat in consumer mode
Commands for Spark:
make run-job job=<str> Run one of the Spark jobs listed in ./jobs folder
Docker compose commands:
make up-generator Generate advertisment campaings data for today's date
make up-producer Up data producer to generate client's moving locations
make up-kafka Up kafka in container
make up-spark Up Spark cluster with 5 workers in containers
Create .env in root directory of project and set all required environment variables listed in .env.tempalte.
Check main configuration file - config.yaml. Specify target locations and paths.
Generate actual marketing campaings data for today's date:
make up-generatorUp container with kafka:
make up-kafkaCreate topics for clients location data producer:
make create-topic topic=clients.client-routes-locations.exportAnd Streaming application output:
make create-topic topic=adv-push.actual-adv.exportUp containers with Spark master and 5 workers:
make up-spark Submit Streaming application:
make run-job job=collect-streaming-query.pyNow you can run kafkacat in consumer mode to see messages produced by Streaming application:
make run-consumer topic=adv-push.actual-adv.exportFor debugging purposes set is_debug to true in config.yaml file.
# Apps configurations
apps:
spark:
is_debug: true # <----- here
clients-locations-topic: *clients-locations-topicNow result producing by Streaming application will be printed to console.