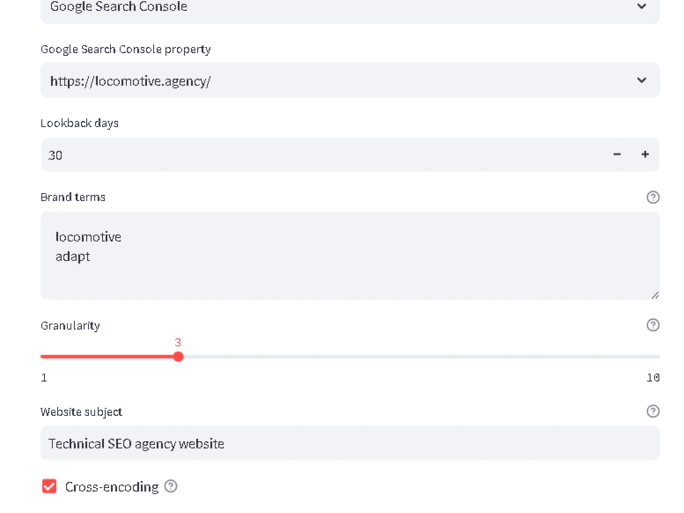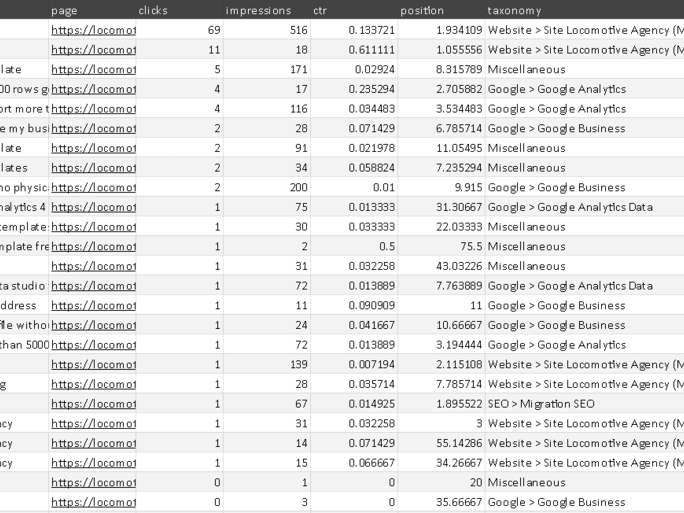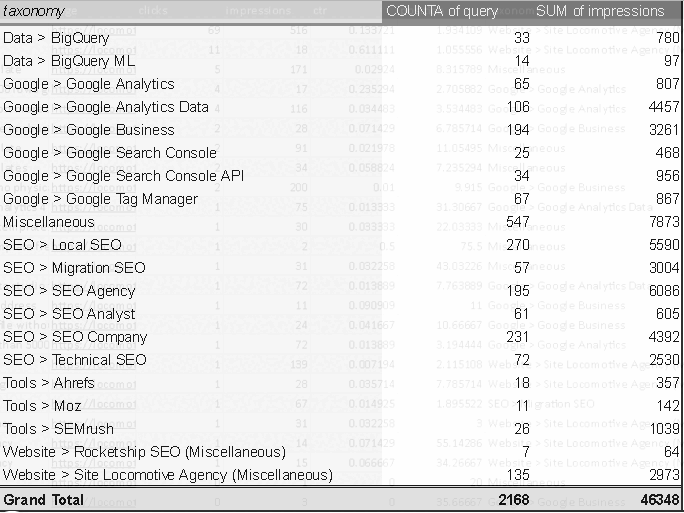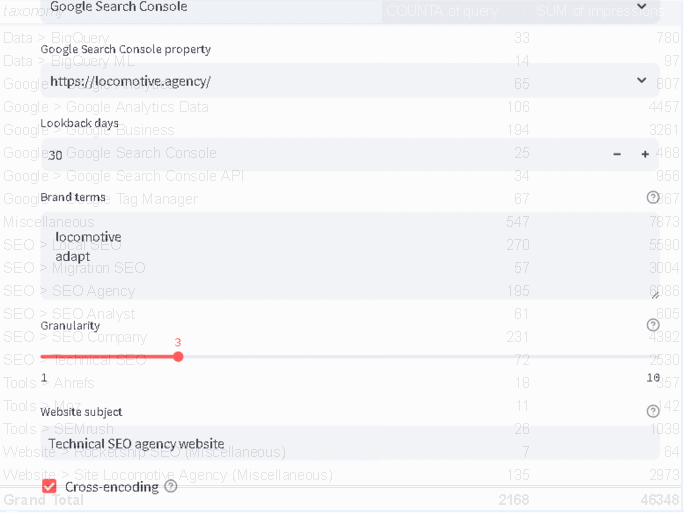
Build a site taxonomy from a list of keywords, provided via CSV file upload, or by connecting to a Google Search Console property. Uses OpenAI for taxonomy creation.
Try out a working Streamlit demo on Huggingface here.
Proudly open sourced by Locomotive Agency.
pip install git+https://github.com/locomotive-agency/taxonomyml.git
from taxonomyml import create_taxonomy
filename = "domain_data.csv"
brand_terms = ['brand', 'brand', 'brand']
website_subject = "This website is about X"
taxonomy, df, samples = create_taxonomy(
filename,
text_column="keyword",
search_volume_column="search_volume",
website_subject=website_subject,
cross_encoded=True,
min_df=5,
brand_terms=brand_terms,
openai_api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
)
df.to_csv("taxonomy.csv", index=False)import os
from taxonomyml import create_taxonomy
from taxonomyml.lib import gsc, gauth
os.environ["OPENAI_API_KEY"] = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
auth_manager = gauth.GoogleServiceAccManager(
scopes=["https://www.googleapis.com/auth/webmasters.readonly"],
credentials_path="service_account.json",
)
gsc_client = gsc.GoogleSearchConsole(auth_manager=auth_manager)
brand_terms = ["brand"]
website_subject = "This website is about X"
prop = "https://www.example.com/"
taxonomy, df, samples = create_taxonomy(
prop,
gsc_client=gsc_client,
days=30,
website_subject=website_subject,
min_df=2,
brand_terms=brand_terms,
limit_queries_per_page=5
)
df.to_csv("domain_taxonomy.csv", index=False)import os
from taxonomyml import create_taxonomy
from taxonomyml.lib import gsc, gauth
os.environ["OPENAI_API_KEY"] = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
auth_manager = gauth.GoogleServiceAccManager(
scopes=["https://www.googleapis.com/auth/webmasters.readonly"],
credentials_path="service_account.json",
subject="emailuser@domain.com",
)
gsc_client = gsc.GoogleSearchConsole(auth_manager=auth_manager)
brand_terms = ["brand"]
website_subject = "This website is about X"
prop = "https://www.example.com/"
taxonomy, df, samples = create_taxonomy(
prop,
gsc_client=gsc_client,
days=30,
website_subject=website_subject,
brand_terms=brand_terms,
)
df.to_csv("domain_taxonomy.csv", index=False)These are the most important parameters. If you are using a CSV, search_volume_column and text_column are required.
data(Union[str, pd.DataFrame]): GSC Property, CSV Filename, or pandas dataframe.text_column(str, optional): Name of the column with the queries. Defaults to None.search_volume_column(str, optional): Name of the column with the search volume. Defaults to None.website_subject(str, required): Provides GPT with context about the website.openai_api_key(str | None, optional): OpenAI API key. Defaults to environment variable OPENAI_API_KEY if not provided.brand_terms(List[str], optional): List of brand terms to remove from queries. Defaults to None.days(int, optional): Number of days back to pull data from Search Console. Defaults to 30.
These parameters allow you to fine-tune the selection of topics sent to OpenAI.
ngram_range(tuple, optional): Ngram range to use for scoring. Defaults to (1, 5).min_df(int, optional): Minimum document frequency to use for scoring. Defaults to 5.limit_queries_per_page(int, optional): Number of queries per page to use for clustering. Defaults to 5.debug_responses(bool, optional): Whether to print debug responses. Defaults to False.
These parameters control the matching back of taxonomy categories to your original data.
cluster_embeddings_model(Union[str, None], optional): Name of the cluster embeddings model. Defaults to 'local'.cross_encoded(bool, optional): Whether to use cross encoded matching. Defaults to False. Improves matching, but takes longer.percentile_threshold(int, optional): The percentile threshold to use for good matches. Defaults to 50.std_dev_threshold(float, optional): The standard deviation threshold to use for good matches. Defaults to 0.1.
from taxonomyml.lib.clustering import ClusterTopics
model = ClusterTopics()
corpus = ['The sky is blue and beautiful.', 'Love this blue and beautiful sky!', 'The quick brown fox jumps over the lazy dog.']
categories = ['weather', 'sports', 'news']
model.fit_pairwise(corpus, categories)
2023-08-02 06:51:39.209 | INFO | lib.clustering:fit_pairwise:615 - Similarity threshold: 0.06378791481256485
2023-08-02 06:51:39.211 | INFO | lib.clustering:fit_pairwise:621 - Most similar: 0
2023-08-02 06:51:39.212 | INFO | lib.clustering:fit_pairwise:623 - Most similar score: 0.407695472240448
2023-08-02 06:51:39.213 | INFO | lib.clustering:fit_pairwise:625 - Standard deviation: 0.16589634120464325
2023-08-02 06:51:39.214 | INFO | lib.clustering:fit_pairwise:621 - Most similar: 0
2023-08-02 06:51:39.215 | INFO | lib.clustering:fit_pairwise:623 - Most similar score: 0.37827810645103455
2023-08-02 06:51:39.216 | INFO | lib.clustering:fit_pairwise:625 - Standard deviation: 0.15577822923660278
2023-08-02 06:51:39.218 | INFO | lib.clustering:fit_pairwise:621 - Most similar: 1
2023-08-02 06:51:39.219 | INFO | lib.clustering:fit_pairwise:623 - Most similar score: 0.0687832236289978
2023-08-02 06:51:39.220 | INFO | lib.clustering:fit_pairwise:625 - Standard deviation: 0.0209036972373724
>>> ([0, 0, -1], ['weather', 'weather', '<outlier>'])