AI Powered DORA Report #493
Conversation
|
|
|
Great work @samad-yar-khan and @jayantbh 🎉 |
| const doraData = { | ||
| lead_time, | ||
| mean_time_to_recovery, | ||
| change_failure_rate | ||
| } as any; |
6391560
to
f07f4e1
Compare
| <FlexBox | ||
| col | ||
| gap1 | ||
| sx={{ ['[data-lastpass-icon-root]']: { display: 'none' } }} |
There was a problem hiding this comment.
It's to remove the password manager from showing its autofill icon in the input field.
It's... unfortunately the recommended way to deal with it.
There was a problem hiding this comment.
damn, this is interesting !
|
|
||
| const selectedModel = useEasyState<Model>(Model.GPT4o); | ||
| const token = useEasyState<string>(''); | ||
| const selectedTab = useEasyState<string>('0'); |
There was a problem hiding this comment.
No good reason. Hacky code.
Will fix with the enum.
There was a problem hiding this comment.
Oh wait, there was a reason. Mui Tabs need the value to be a string.
| <Markdown>{data.change_failure_rate_trends_summary}</Markdown> | ||
| </TabPanel> | ||
| <TabPanel | ||
| value="5" |
There was a problem hiding this comment.
all these values can be combined into an enum:
enum MyEnum {
dora_trend_summary,
change_failure_rate_trends_summary,
mean_time_to_recovery_trends_summary
...more...
}this means that:
MyEnum.dora_trend_summary will be equal to 0
| @@ -77,7 +79,9 @@ export const AIAnalysis = () => { | |||
|
|
|||
| const selectedModel = useEasyState<Model>(Model.GPT4o); | |||
| const token = useEasyState<string>(''); | |||
| const selectedTab = useEasyState<string>('0'); | |||
| const selectedTab = useEasyState<string>( | |||
There was a problem hiding this comment.
could have just removed string:
const selectedTab = useEasyState<AnalysisTabs>(
no more type conversion would have been needed
Pull Request Contents
Quick Look at how it works 👀
Screen.Recording.2024-07-30.at.4.34.33.PM.mov
Acceptance Criteria fulfillment
Evaluation and Results: GPT4o Vs LLAMA 3.1
We did the DORA AI analysis for July on the following open-source repositories: facebook/react, middlewarehq/middlware, meta-llama/llama and facebookresearch/dora.
Mathematical Accuracy
DORA Metrics score: 5/10
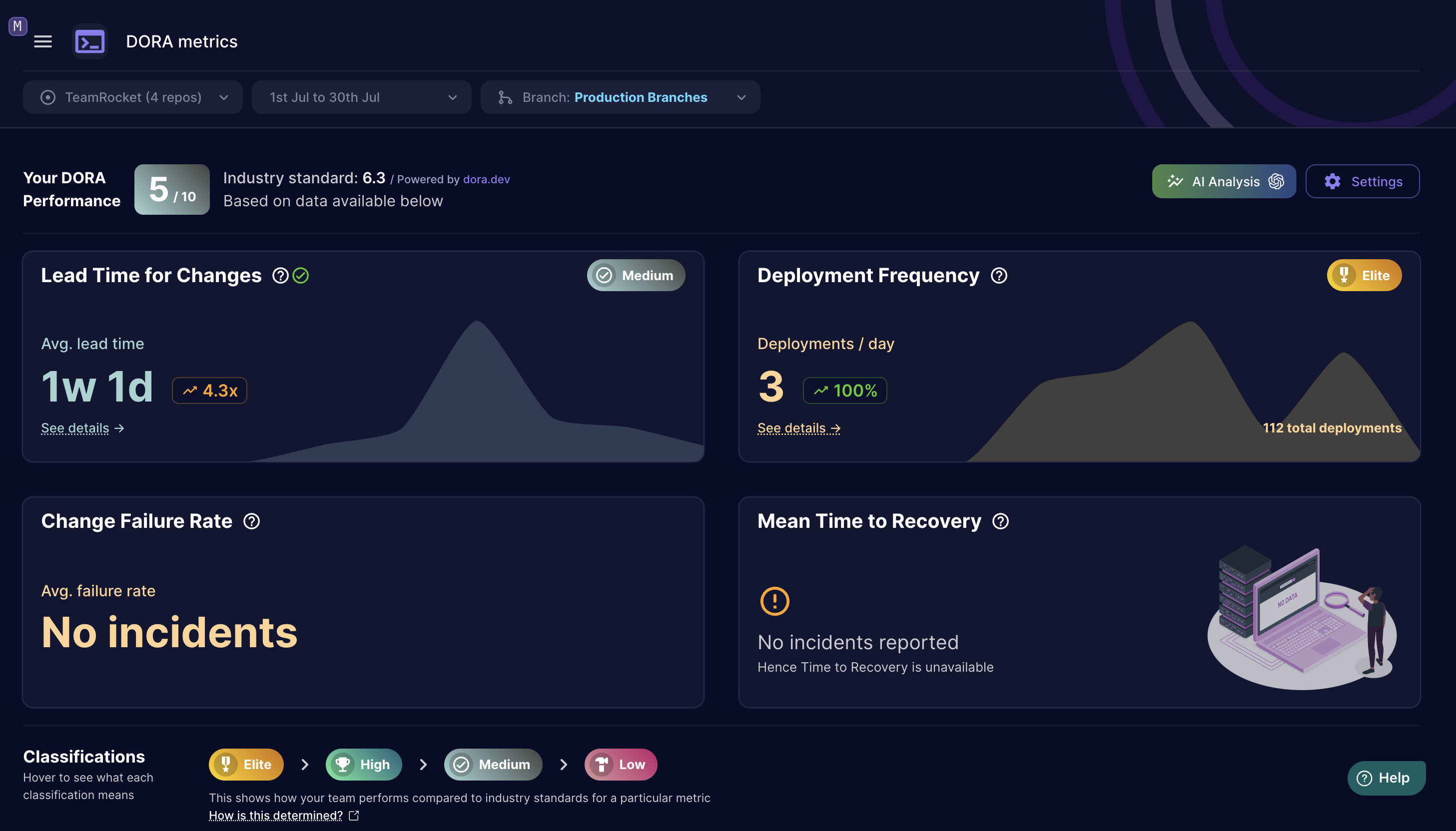
GPT 4o with DORA score 5/10
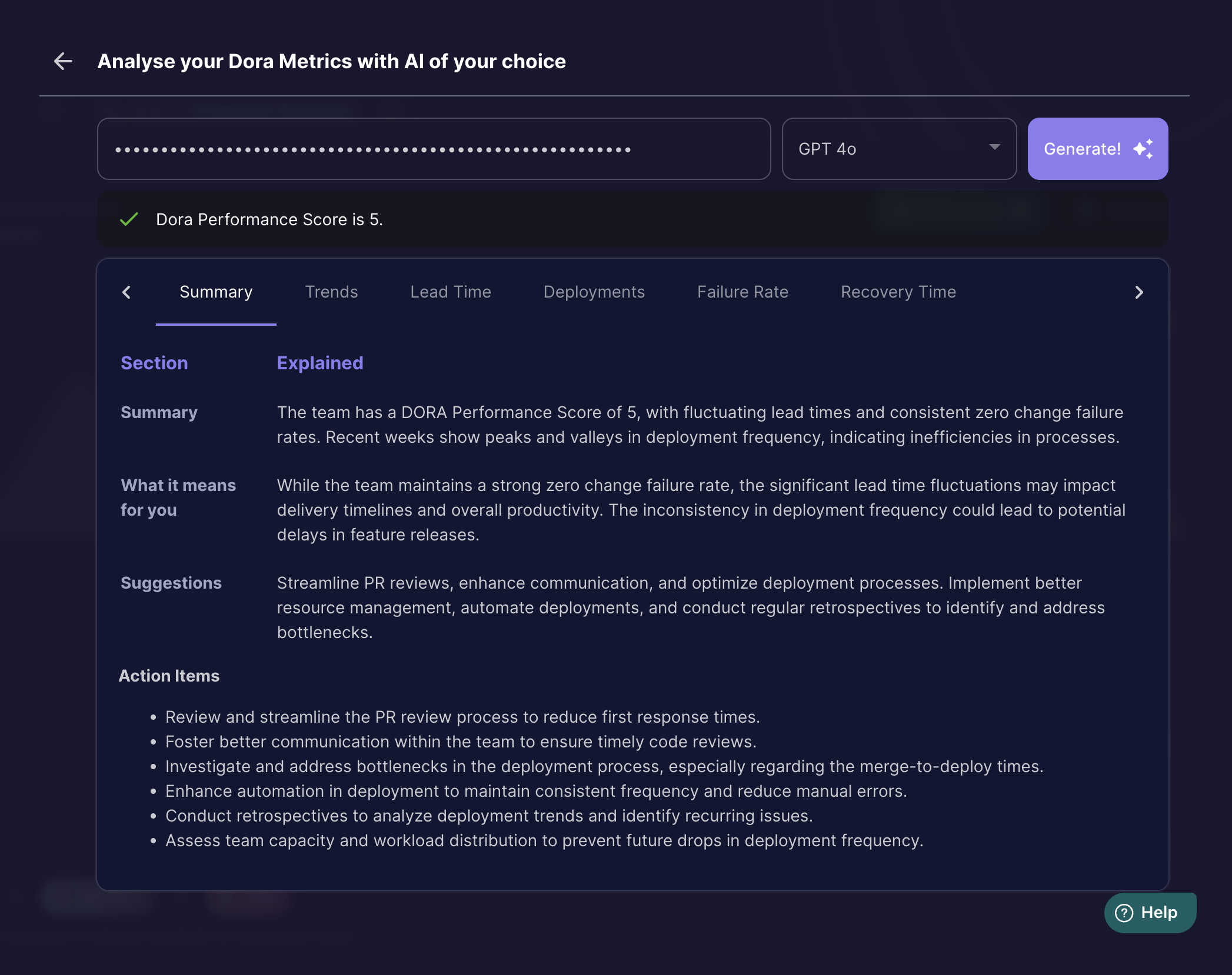
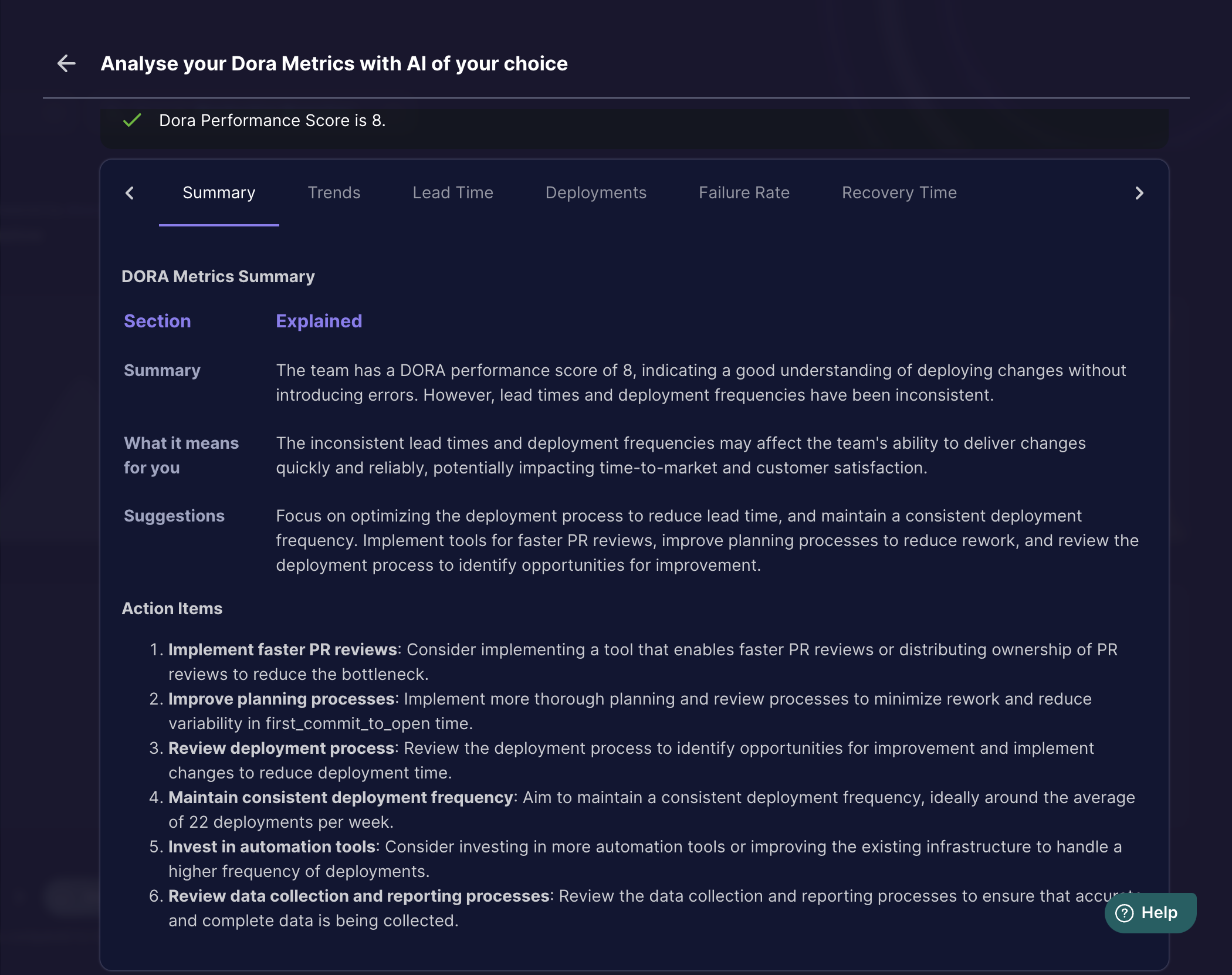
LLAMA 3.1 with DORA Score 8/10 (incorrect)
GPT 4o DORA Score was closer to the actual DORA score than LLAMA 3.1 in 9/10 cases, hence GPT4o was more accurate compared to LLAMA 3.1 in this scenario.
Data Analysis
The trend data for the four keys dora metrics, calculated by Middleware, was fed to the LLMs as input along with different experimental prompts to ensure a concrete data analysis.
The trend data is usually a JSON object with date strings as keys, representing weeks' start dates mapped to the metric data.
Mapping Data: Both the models were at par at extracting data from the JSON and inferring the data in the correct manner. Example: Both GPT and LLAMA were able to map the correct data to the input weeks without errors or hallucinations.
Deployment Trends Summarised: GPT4o
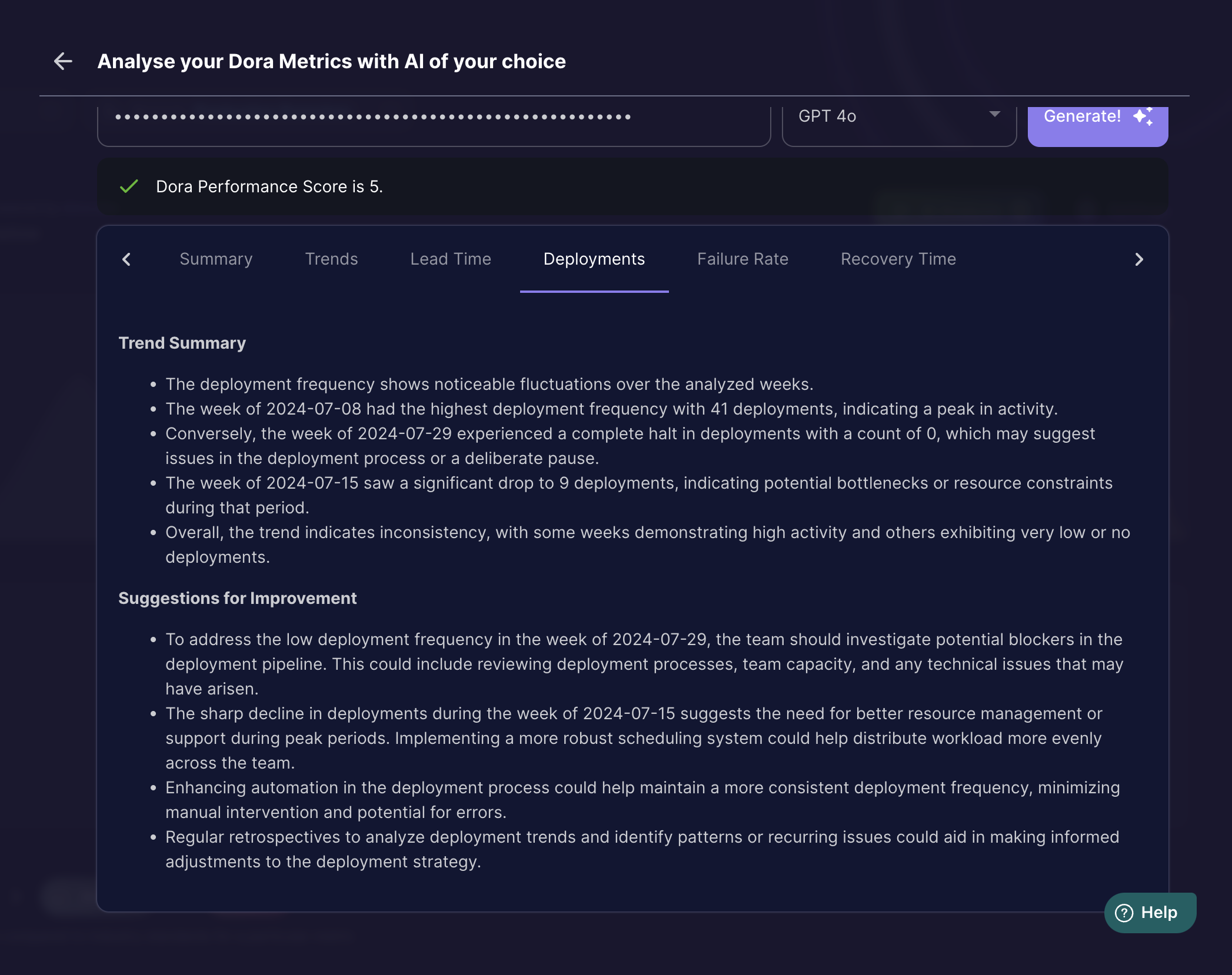
Deployment Trends Summarised: LLAMA 3.1 405B
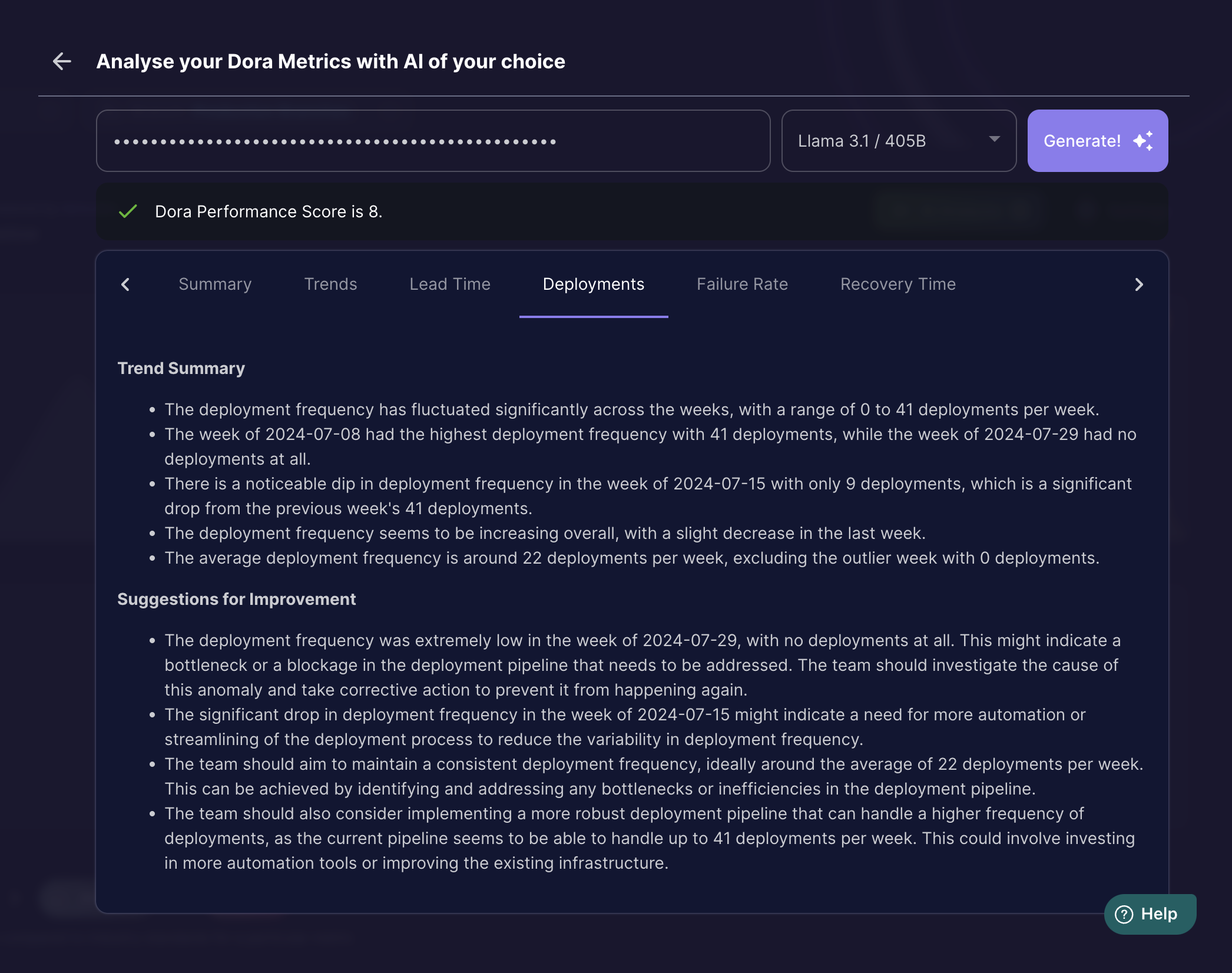
Extracting Inferences: Both the models were able to derive solid inferences from data.
LLAMA 3.1 identified week with maximum lead time along with the reason for the high lead time.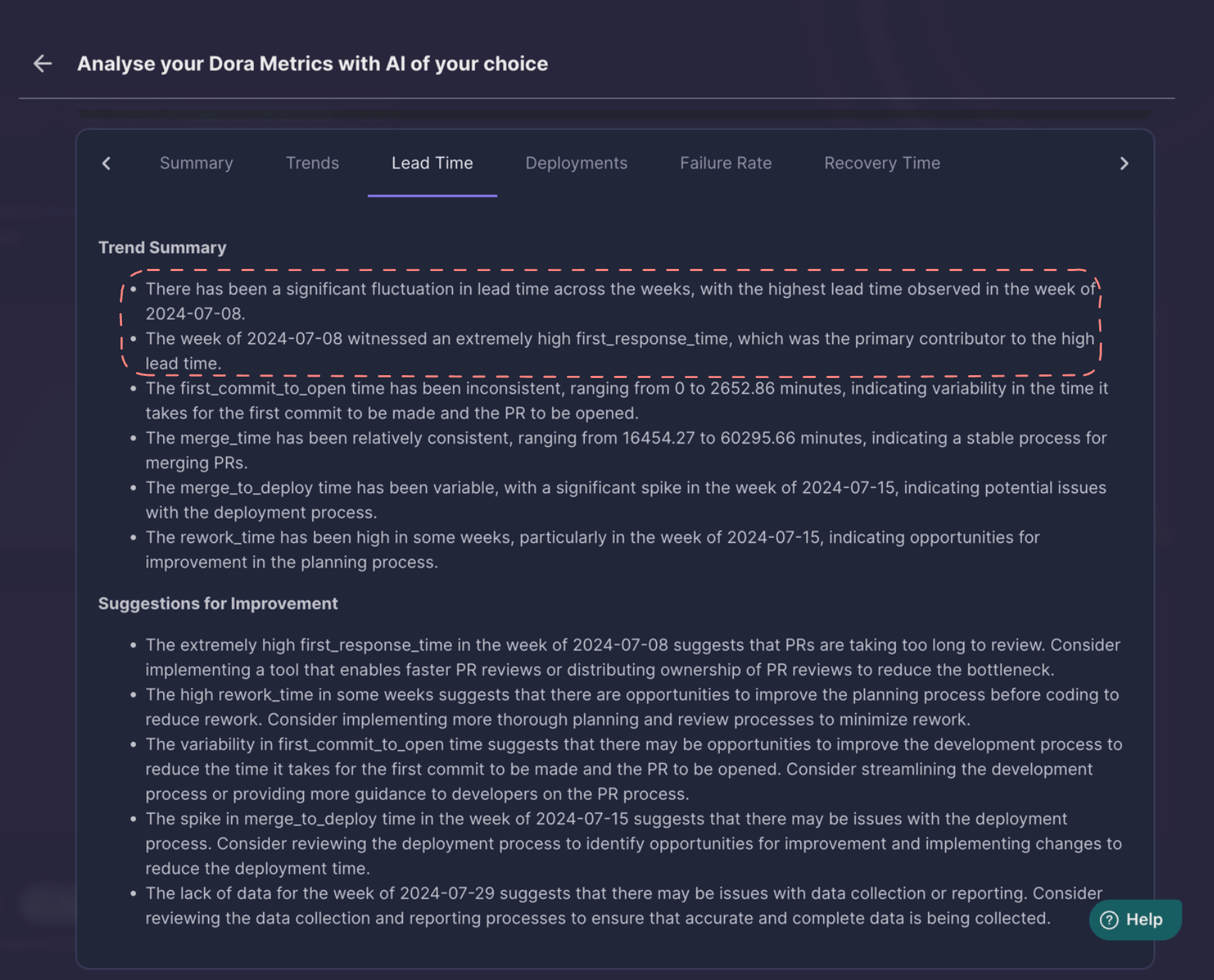
This inference could be verified by the Middleware Trend Charts.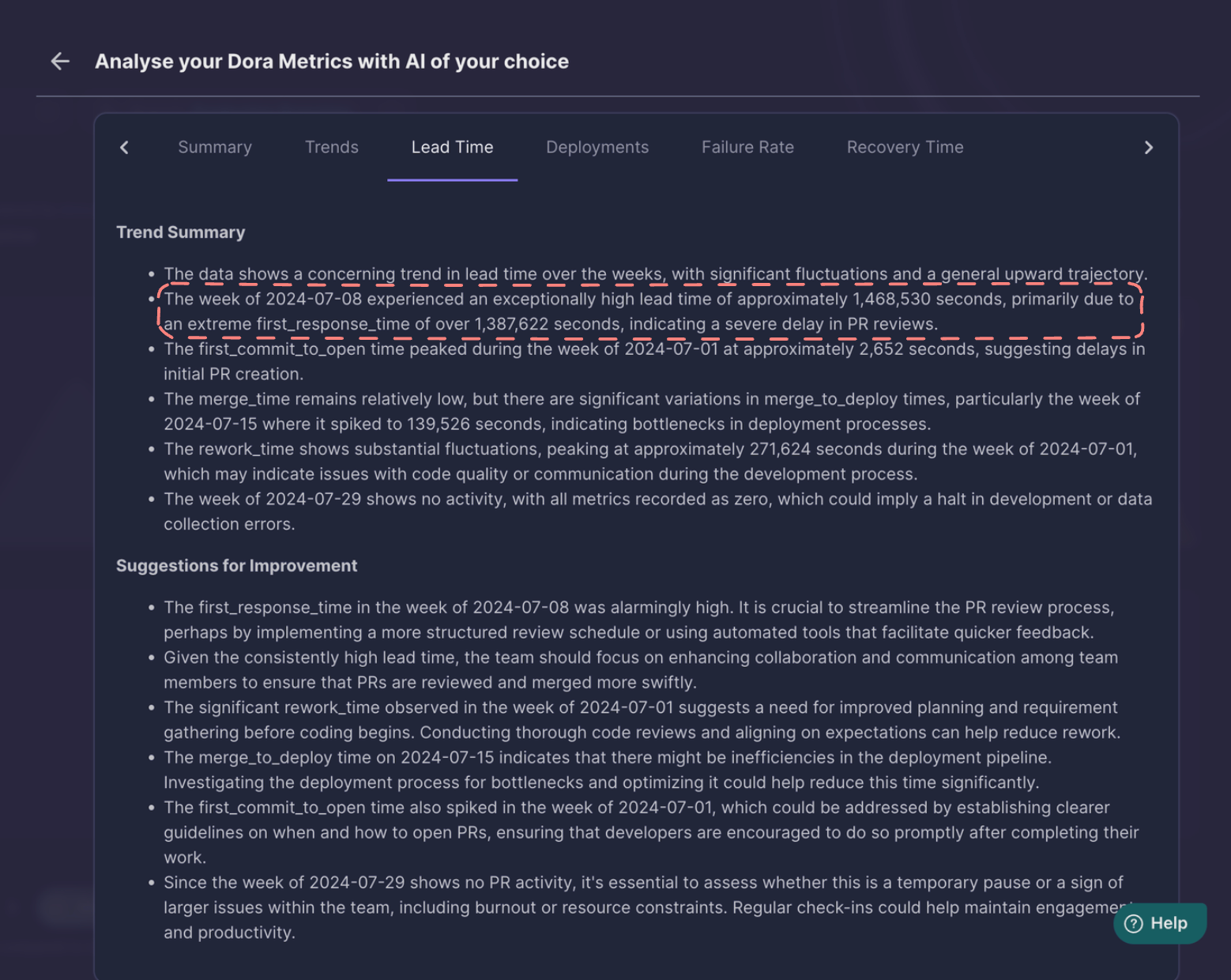
GPT4o was also able to extract the week with the maximum lead time and the reason too, which was, high first-response time.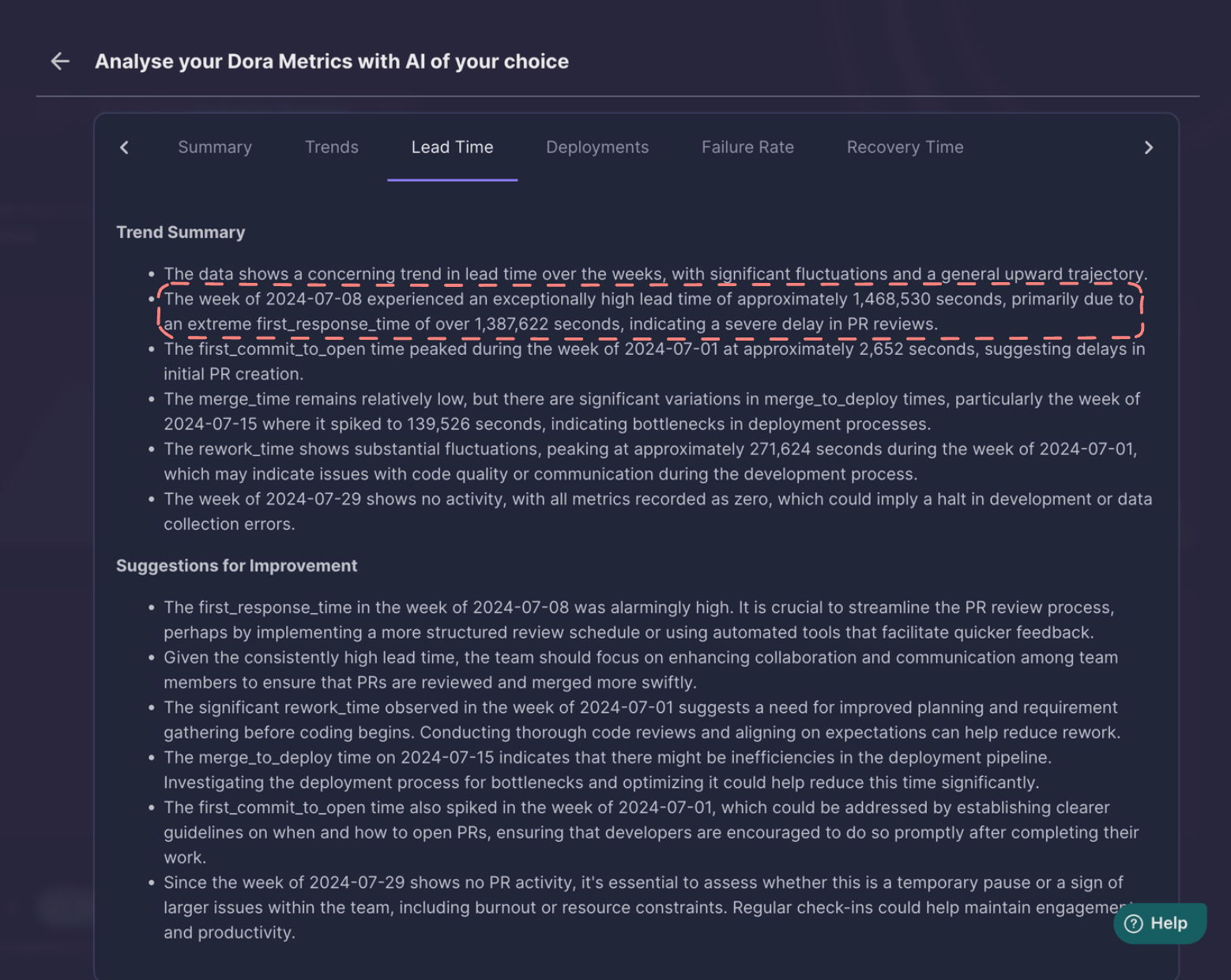
Data Presentation: Data representation has been a hit or miss with LLMs. There are cases where GPT performs better at data presentation but lacks behind LLAMA 3.1 in accuracy and there have been cases like the DORA score where GPT was able to do the math better.
LLAMA and GPT were both given the lead time value in seconds. LLAMA was able to round off the data closer to the actual value of 16.99 days while GPT rounded off the data to 17 days 2 hours but presented the data in a more detailed format.
GPT4o
LLAMA 3.1 405B
Actionability
GPT4o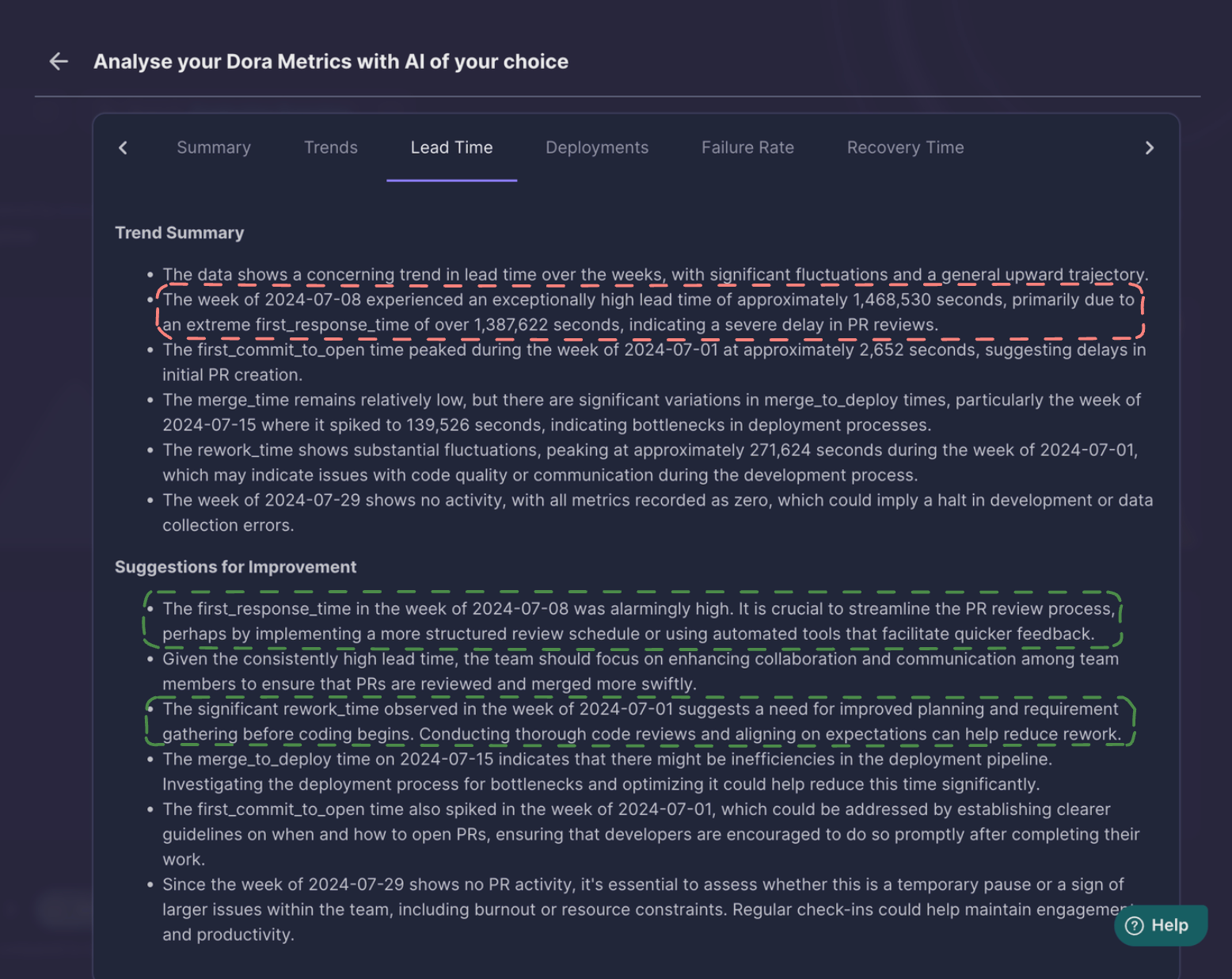
LLAMA 3.1 405B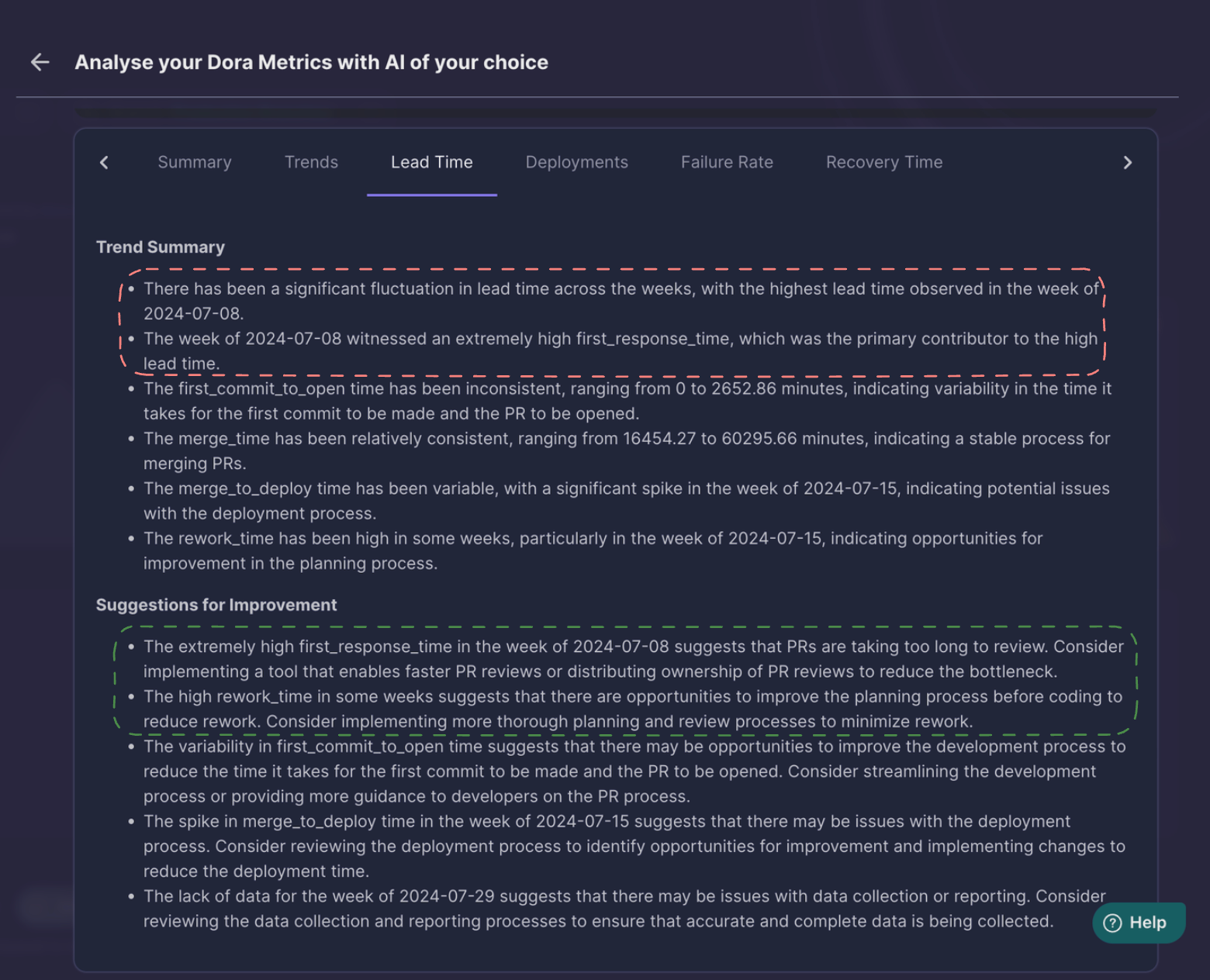
Summarisation
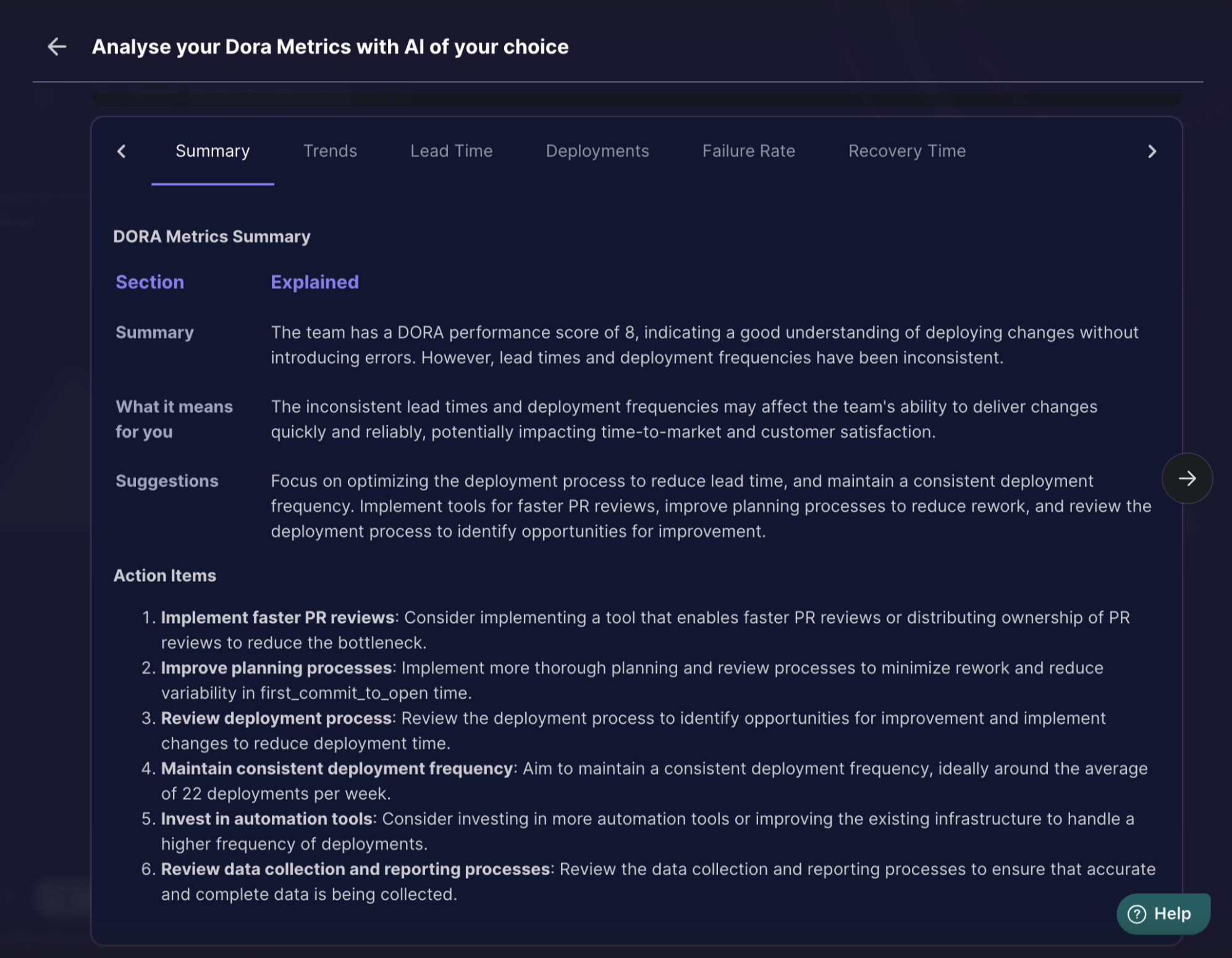
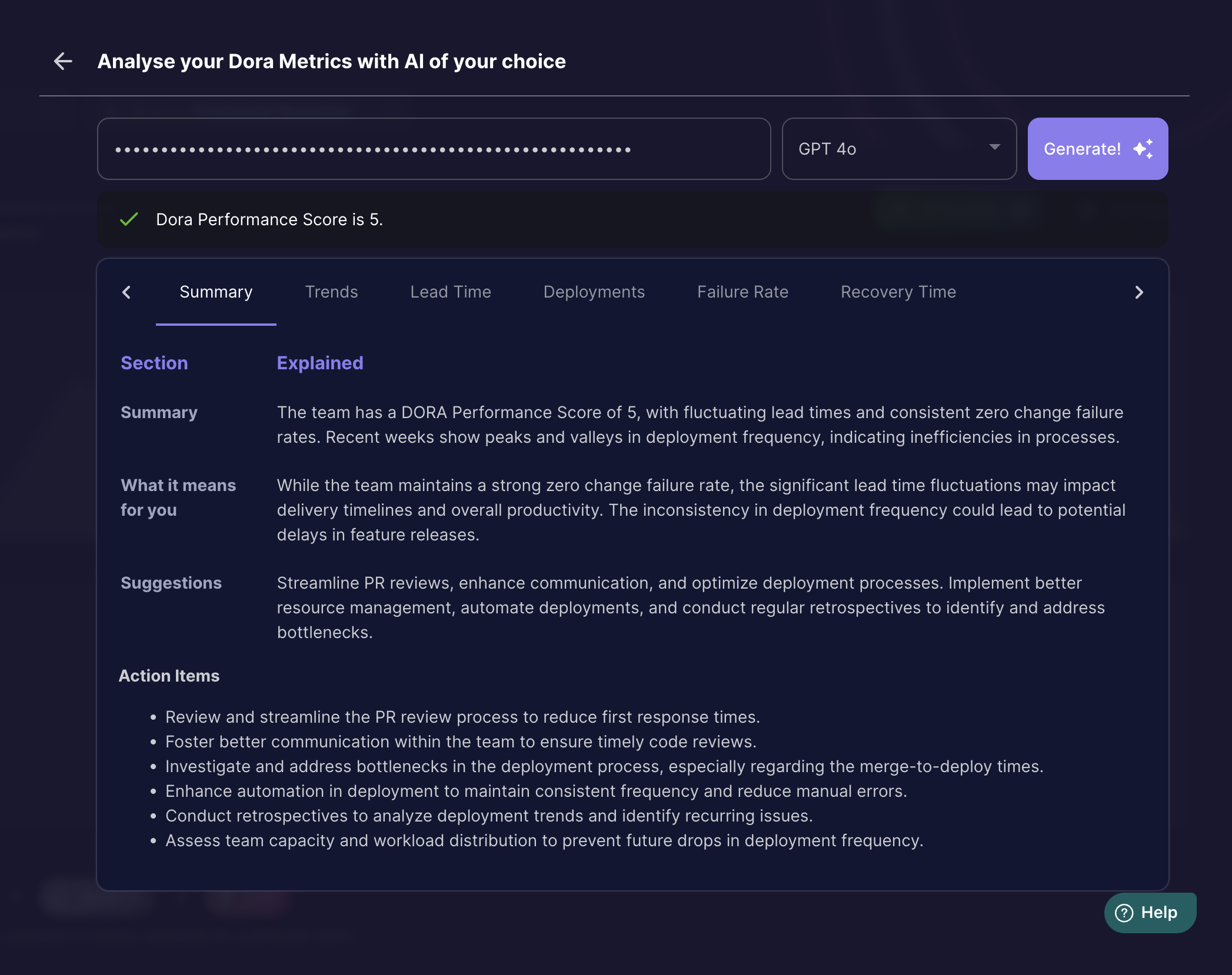
To test out the summarisation capabilities of the models we asked the model to summarise each metric trend individually and then feed the output results for all the trends back into the LLMs to get a summary or in Internet's slang DORA TLDR for the team.
The summarisation capability of large data is similar in both the LLMs.
LLAMA 3.1 405B
GPT4o
Conclusion
For a long time LLAMA was trying to catch up with GPT in terms of data processing and analytical abilities. Our earlier experimentation with older LLAMA models led us to believe that GPT is way ahead, but the recent LLAMA 3.1 405B model is at par with the GPT4o.
If you value data privacy of your customers and want to try out the open-source LLAMA 3.1 models instead of GPT4, go ahead! There will be negligible difference in performance and you will be able to ensure data privacy if you use self hosted models. Open-Source LLMs have finally started to compete with all the closed-source competitors.
Both LLAMA 3.1 and GPT4o are super capable of deriving inferences from processed data and making Middleware’s DORA metrics more actionable and digestible for engineering leaders, leading to more efficient teams.
Future Work
This was an experiment to build an AI powered DORA solution and in the future we will be focusing on adding greater support for self hosted or locally running LLMs from Middleware. Enhanced support for AI powered action-plans throughout the product using self hosted LLMs, while ensuring data privacy, will be our goal for the coming months.
Proposed changes (including videos or screenshots)
Added Services
AIAnalyticsServiceto allow summarising and inference of DORA data based on different models.UI Changes
Screen.Recording.2024-07-30.at.4.34.33.PM.mov
Added APIs
Added Compiled Summary API to take data from all the above
Fetch Models
curl --location 'http://localhost:9696/ai/models'Further comments