this is a fork of absurd sql that implements a nostr specific bench (absurd sql info below). feedback welcome on a better format to release this tool. assuming you are starting in root folder, commands to run nostr bench are (again, feedback welcome):
cd src/examples
../../node_modules/.bin/webpack serve --config-name "nostr_bench"
and then open http://localhost:8080/ in your browser
NOTE: work on nostr bench is still in progress
This is an absurd project.
It implements a backend for sql.js (sqlite3 compiled for the web) that treats IndexedDB like a disk and stores data in blocks there. That means your sqlite3 database is persisted. And not in the terrible way of reading and writing the whole image at once -- it reads and writes your db in small chunks.
It basically stores a whole database into another database. Which is absurd.
See the demo. You can also view an entire app using this here.
You should also read this blog post which explains the project in great detail.
If you like my work, feel free to buy me a coffee!
You can check out the example project to get started. Or follow the steps below:
First you install the packages:
yarn add @jlongster/sql.js absurd-sql
Right now you need to use my fork of sql.js, but I'm going to open a PR and hopefully get it merged. The changes are minimal.
absurd-sql must run in a worker. This is fine because you really shouldn't be blocking the main thread anyway. So on the main thread, do this:
import { initBackend } from 'absurd-sql/dist/indexeddb-main-thread';
function init() {
let worker = new Worker(new URL('./index.worker.js', import.meta.url));
// This is only required because Safari doesn't support nested
// workers. This installs a handler that will proxy creating web
// workers through the main thread
initBackend(worker);
}
init();Then in index.worker.js do this:
import initSqlJs from '@jlongster/sql.js';
import { SQLiteFS } from 'absurd-sql';
import IndexedDBBackend from 'absurd-sql/dist/indexeddb-backend';
async function run() {
let SQL = await initSqlJs({ locateFile: file => file });
let sqlFS = new SQLiteFS(SQL.FS, new IndexedDBBackend());
SQL.register_for_idb(sqlFS);
SQL.FS.mkdir('/sql');
SQL.FS.mount(sqlFS, {}, '/sql');
const path = '/sql/db.sqlite';
if (typeof SharedArrayBuffer === 'undefined') {
let stream = SQL.FS.open(path, 'a+');
await stream.node.contents.readIfFallback();
SQL.FS.close(stream);
}
let db = new SQL.Database(path, { filename: true });
// You might want to try `PRAGMA page_size=8192;` too!
db.exec(`
PRAGMA journal_mode=MEMORY;
`);
// Your code
}Because this uses SharedArrayBuffer and the Atomics API, there are some requirement for code to run.
- It must be run in a worker thread (you shouldn't block the main thread with queries anyway)
- Your server must respond with the following headers:
Cross-Origin-Opener-Policy: same-origin
Cross-Origin-Embedder-Policy: require-corp
Those headers are required because browsers only enable SharedArrayBuffer if you tell it to isolate the process. There are potential security problems if SharedArrayBuffer was available everywhere.
We do support browsers without SharedArrayBuffer (only Safari). Read more about it here: https://jlongster.com/future-sql-web#fallback-mode-without-sharedarraybuffer
There are some limitations in this mode: only one tab can be writing the database at a time. The database will never be corrupted; if multiple tabs try to write it will just throw an error (in the future it should call a handler that you provide so you can notify the user).
It consistently beats IndexedDB performance up to 10x:
Read performance: doing something like SELECT SUM(value) FROM kv:

Write performance: doing a bulk insert:
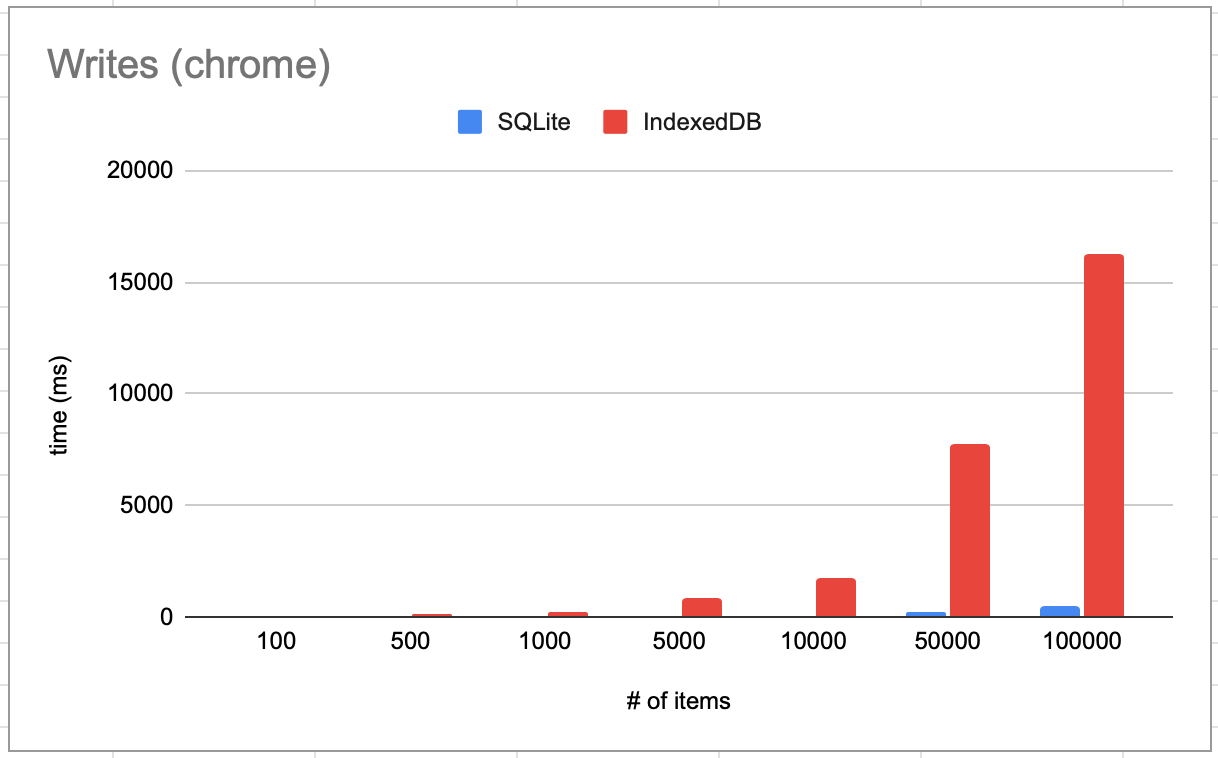
These are all on a 2015 macbook pro. Benchmark code is in src/examples/bench.
Read this blog post for more details.
There are several things that could be done:
- Add a bunch more tests
- Implement a
webkitFileSystembackend- I already started it here, but initial results showed that it was way slower?
- Bug fixes