Dataset is released here!
- Curated by: Mu Cai, Reuben Tan, Jianfeng Gao, Yong Jae Lee, Jianwei Yang, etc.
- Language(s): English
- License: MIT
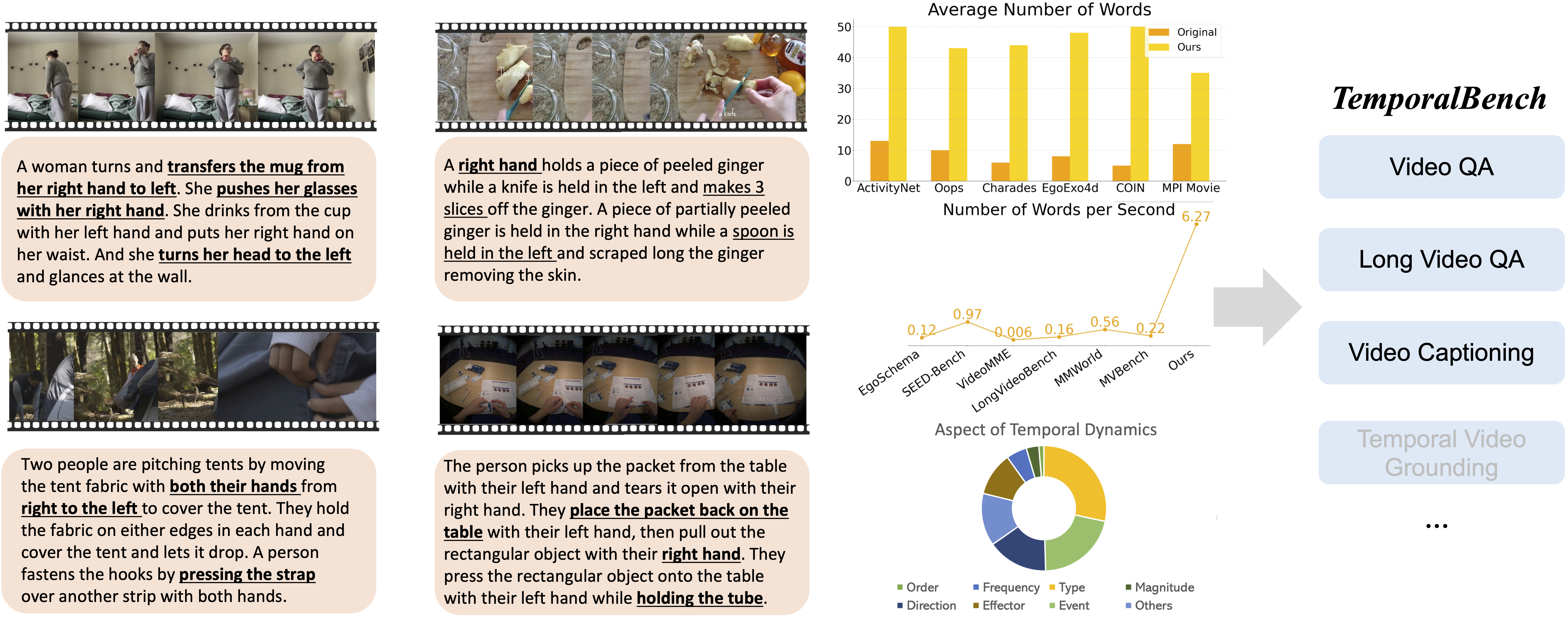
TemporalBench is a video understanding benchmark designed to evaluate fine-grained temporal understanding and reasoning for multimodal video models. It consists of ∼10K video question-answer pairs sourced from ∼2K high-quality human-annotated video captions, capturing detailed temporal dynamics and actions.
Please clone our HuggingFace repository, which contains the following structure:
|--short_video.zip
|--long_video_ActivityNet.zip
|--long_video_Charades.zip
|--long_video_COIN.zip
|--long_video_EgoExo4D.zip
|--long_video_FineGym.zip
|--temporalbench_short_qa.json
|--temporalbench_long_qa.json
|--temporalbench_short_caption.json
and then unzip all videos. You can use the following commands:
git lfs install
git clone https://huggingface.co/datasets/microsoft/TemporalBench
cd TemporalBench
unzip long_video_ActivityNet.zip long_video_Charades.zip long_video_COIN.zip long_video_EgoExo4D.zip long_video_FineGym.zip short_video.zip
rm -rf *.zip
cd ..0. Agree to our [license] and log in
Agree to our [license], and then use following command to log in via terminal.
huggingface-cli login
Case 1: How to use your own model?
Very simple!
-
Initilze your model at https://github.com/mu-cai/TemporalBench/blob/main/eval/llava-onevision.py/#L33-L47
-
Write the inference code at https://github.com/mu-cai/TemporalBench/blob/main/eval/llava-onevision.py/#L68-L101
Case 2: Evaluate existing models
If you want to evaluate existing models like LLaVA-OneVision, prepare the environment as follows
git clone https://github.com/LLaVA-VL/LLaVA-NeXT
cd LLaVA-NeXT
pip install -e .
# Update --data_folder
CUDA_VISIBLE_DEVICES=0 python eval/llava-onevision.py --data_json temporalbench_short_qa.json
CUDA_VISIBLE_DEVICES=1 python eval/llava-onevision.py --data_json temporalbench_long_qa.json
CUDA_VISIBLE_DEVICES=2 python eval/llava-onevision.py --data_json temporalbench_short_caption.json
Option 2. Using [lmms-eval] (Systematic!)
Our pull request is here.
You can use commands like this:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 accelerate launch --main_process_port=29504 --num_processes=8 \
-m lmms_eval \
--model llava_onevision \
--model_args pretrained=lmms-lab/llava-onevision-qwen2-7b-ov,conv_template=qwen_1_5,model_name=llava_qwen,max_frames_num=1 \
--tasks temporalbench \
--batch_size 1 \
--log_samples \
--log_samples_suffix llava_onevision \
--output_path ./logs/temporalbench_short_qa_try
You can change --tasks temporalbench to --tasks temporalbench_short_qa, --tasks temporalbench_long_qa, --tasks temporalbench_short_caption to specify a specific task.
# for QA
python get_qa_acc.py --data_json temporalbench_short_qa.json
python get_qa_acc.py --data_json temporalbench_long_qa.json
# for captioning
python get_captioning_score.py You will get something like this for temporalbench_short_qa:
$ python get_qa_acc.py --data_json temporalbench_short_qa.json
******************** llava-onevision-qwen2-7b-ov-frame1.jsonl ********************
Binary Accuracy: 5259/9867 53.30%
Multiple Binary Accuracy: 290/2179 13.31%
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
|+++ Dataset Binary Accuracy ||| Multiple Binary Accuracy
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
|--- ActivityNet 629/1186 53.04% ||| 47/281 16.73%
|--- Charades 544/957 56.84% ||| 55/298 18.46%
|--- COIN 890/1550 57.42% ||| 62/385 16.10%
|--- EgoExo4D 883/1542 57.26% ||| 34/307 11.07%
|--- Movie_Description 796/1467 54.26% ||| 52/326 15.95%
|--- Oops 815/1571 51.88% ||| 26/294 8.84%
|--- FineGym 702/1594 44.04% ||| 14/288 4.86%
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
|-- Category Binary Accuracy ||| Multiple Binary Accuracy
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
|--- Action Order 62/129 48.06% ||| 48/110 43.64%
|--- Action Frequency 244/530 46.04% ||| 154/390 39.49%
|--- Action Type 1453/2802 51.86% ||| 608/1547 39.30%
|--- Motion Magnitude 138/320 43.12% ||| 97/253 38.34%
|--- Motion Direction/Orientation 723/1536 47.07% ||| 400/1037 38.57%
|--- Action Effector 516/1109 46.53% ||| 275/746 36.86%
|--- Event Order 1296/2099 61.74% ||| 542/1132 47.88%
|--- Others 827/1342 61.62% ||| 435/839 51.85%Each data instance in the dataset consists of a question-answer pair based on a video clip. Below is an example from the dataset:
{
"idx": "short_video/Charades/EEVD3_start_11.4_end_16.9.mp4_0",
"video_name": "short_video/Charades/EEVD3_start_11.4_end_16.9.mp4",
"category": "Action Effector",
"source_dataset": "Charades",
"question": "Which caption best describes this video?\nA. A person closes the door of the fridge with his left hand while looking at the bowl of fruit he holds in his right hand. He transfers the bowl from his right hand to his left hand. He picks up a fruit from the bowl with his left hand. He tosses the fruit up with his left hand and catches it with the same hand while walking forward. \nB. A person closes the door of the fridge with his left hand while looking at the bowl of fruit he holds in his right hand. He transfers the bowl from his right hand to his left hand. He picks up a fruit from the bowl with his right hand. He tosses the fruit up with his right hand and catches it with the same hand while walking forward.\nAnswer with the option's letter from the given choices directly.",
"GT": "B"
}idx: A string representing the video identifier.video_name: Video pathquestion: A string containing the question related to the video.GT: A string containing the correct answer.
This dataset was created from human annotators with fine-grained temporal annotations. The videos were sampled from various sources, including procedural videos and human activities.
- ActivityNet-Captions, COIN, Charades-STA, FineGym, Oops, Movei Description, EgoExo4d,
TemporalBench is made for academic research purposes only. Commercial use in any form is strictly prohibited. The copyright of all videos belong to their respective owners. We do not own any of the videos. Any form of unauthorized distribution, publication, copying, dissemination, or modifications made over TemporalBench in part or in whole is strictly prohibited. You cannot access our dataset unless you comply to all the above restrictions and also provide your information for legal purposes. This dataset is foucsing on fine-grained temporal tasks rather than coarse-grained video understanding.
If you find this work useful, please cite:
@article{cai2024temporalbench,
title={TemporalBench: Towards Fine-grained Temporal Understanding for Multimodal Video Models},
author={Cai, Mu and Tan, Reuben and Zhang, Jianrui and Zou, Bocheng and Zhang, Kai and Yao, Feng and Zhu, Fangrui and Gu, Jing and Zhong, Yiwu and Shang, Yuzhang and Dou, Yao and Park, Jaden and Gao, Jianfeng and Lee, Yong Jae and Yang, Jianwei},
journal={arXiv preprint arXiv:2410.10818},
year={2024}
}