Logging and Monitoring Tools for the Cluster
Application and systems logs can help you understand what is happening inside your cluster. The logs are particularly useful for debugging problems and monitoring cluster activity. Most modern applications have some kind of logging mechanism; as such, most container engines are likewise designed to support some kind of logging. The easiest and most embraced logging method for containerized applications is to write to the standard output and standard error streams.
However, the native functionality provided by a container engine or runtime is usually not enough for a complete logging solution. For example, if a container crashes, a pod is evicted, or a node dies, you’ll usually still want to access your application’s logs. As such, logs should have a separate storage and lifecycle independent of nodes, pods, or containers. This concept is called cluster-level-logging. Cluster-level logging requires a separate backend to store, analyze, and query logs.
Why bother setting up such a stack of tools when a user can just run docker logs... or kubectl logs...? Well, technically it is true, a user can just do that. However, if you have several replicas you'll have to go through each one of the containers to find what you are looking for. A stack of tools is meant to gather and present nicely all the logs at once by making it easier to go through all of them. Furthermore, visual representation of information is known to help performing debugging. Another interesting point is the manipulation of the logs. With a tool such as Fluentd or Logstash you can filter, modify and backup your logs very easily.

Basically, Elasticsearch is a search engine that is responsible for storing our logs and allowing for them to be queried. Fluentd sends log messages from Kubernetes to Elasticsearch, whereas Kibana is a graphical interface for viewing and querying the logs stored in Elasticsearch.
A key feature is related to Fluentd, which is deployed as a DaemonSet which spawns a pod on each node that reads logs, generated by kubelet, container runtime and containers and sends them to Elasticsearch.
The stack installation is based on the following GitHub project: https://github.com/cdwv/efk-stack-helm
First of all, Fluentd is now hosted by the Cloud Native Computing Foundation, the same which hosts Kubernetes. Furthermore, it uses a Buffering System that is highly configurable, which means that it could be both in-memory or on-disk. Last but not least, its memory footprint is very low and its configuration process is very easy.
We could also replace Fluentd by Fluent Bit, which is a lighter log forwarder but has fewer functionalities than the first one.
Monitoring an application's current state is one of the most effective ways to anticipate problems and discover bottlenecks in a production environment. Yet it is also currently one of the biggest challenges faced by almost all software development organizations.
The growing adoption of microservices makes logging and monitoring more complex since a large number of applications, distributed and diversified in nature, are communicating with each other. A single point of failure can stop the entire process, but identifying it is becoming increasingly difficult.
Generally speaking, there are several Kubernetes metrics to monitor. These can be separated into two main components: (1) monitoring the cluster itself, and (2) monitoring pods.
For cluster monitoring, the objective is to monitor the health of the entire Kubernetes cluster. As an administrator, we are interested in discovering if all the nodes in the cluster are working properly and at what capacity, how many applications are running on each node, and the resource utilization of the entire cluster.
The act of monitoring a pod can be separated into three categories: Kubernetes metrics, container metrics, and application metrics.
-
Using Kubernetes metrics, we can monitor how a specific pod and its deployment are being handled by the orchestrator.
-
Container metrics are available mostly through Cadvisor. In this case, metrics like CPU, network, and memory usage compared with the maximum allowed are the highlights.
-
Finally, there are the application specific metrics. These metrics are developed by the application itself and are related to the business rules it addresses. An e-commerce application would expose data concerning the number of users online and how much money the software made in the last hour, for example. The metrics described in the latter type are commonly exposed directly by the application: if you want to keep closer track you should connect the application to a monitoring application.
We have opted for a combination of two tools that are the most common monitoring solutions used by Kubernetes users: Prometheus and Grafana, which combine open source tools that are deployed inside Kubernetes.
Prometheus, a Cloud Native Computing Foundation project, is a systems and service monitoring system. It collects metrics from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts if some condition is observed to be true.
Grafana is a web dashboarding system that allows you to query, visualize and understand metrics collected by time series data database (aka Data Source). Time series are used on modern monitoring as a way to represent metric data collected over time. This way, modern performance metrics can be stored and displayed in a smart and useful fashion.
For both the aforementioned tools the official Helm charts from the Kubernetes stable repo have been used.
Once your PhenoMeNal cluster has been deployed, run the following command to get the whole list of enabled Ingresses:
kn kubectl get ingress --all-namespaces
or alternatively you can first login into the master via ssh with the command kn ssh and then run only kubectl get ingress --all-namespaces. You should get a similar output:
NAMESPACE NAME HOSTS ADDRESS PORTS AGE
default galaxy-stable-galaxy-ingress galaxy.34.244.118.105.nip.io 80 15m
default jupyter-ingress notebook.34.244.118.105.nip.io 80 15m
default luigi-ingress luigi.34.244.118.105.nip.io 80 15m
kube-system kubernetes-dashboard dashboard.34.244.118.105.nip.io 80 15m
logmon efk-kibana kibana.34.244.118.105.nip.io 80 22s
logmon grafana grafana.34.244.118.105.nip.io 80 18s
logmon prometheus-alertmanager alertmanager.34.244.118.105.nip.io 80 20s
logmon prometheus-pushgateway pushgateway.34.244.118.105.nip.io 80 20s
logmon prometheus-server prometheus.34.244.118.105.nip.io 80 20s
Copy one of the logmon Ingresses' Hosts listed in your output and paste it in a browser window. You will be prompted with a pop-up dialogue box asking for credentials. You can find them in the config.tfvars file generated when you initialize your working directory with the command kn init provider my-deployment.
In such a file password for all various dashboard are usually listed under the provision block (check here for further documentation), specifically in the extra_vars field of an action block. Password can be of course customized. However, strong password are required to be used otherwise during the initialization of the cluster a pre-init check will return an error informing that the password/s saved in the config.tfvars file is/are too weak.
Note: Such secrets are carefully encrypted before being ingested into the related Kubernetes' namespaces.
When you will access Kibana for the first time, as explained in the paragraph above, you will be initially requested to enter the username and password before attempting to do any setup. Once successfully logged in, the first and foremost step as user is to configure an index in order to retrieve data from Elasticsearch indices for things like visualizations. If Fluentd's default configuration has not be changed, then the index name/pattern is logstash-YYYY-MM-DD. The wildcard logstash-* for matching all index beginning with logstash-... is recommended.
Next you can specify some settings, in particular it is highly recommended to setup a "Time Filter field name" by usually selecting the default suggested one: @timestamp . Finally click on the blue button "Create index pattern". Once confirmed, you should be displayed with a list of the found Fields associated to the just created index. Usually logs files follow the json syntax, thus Data are represented by name/value pairs. The Fields are none other than the name (or key if you will) from all the various pairs collected up to a certain moment in your instance.
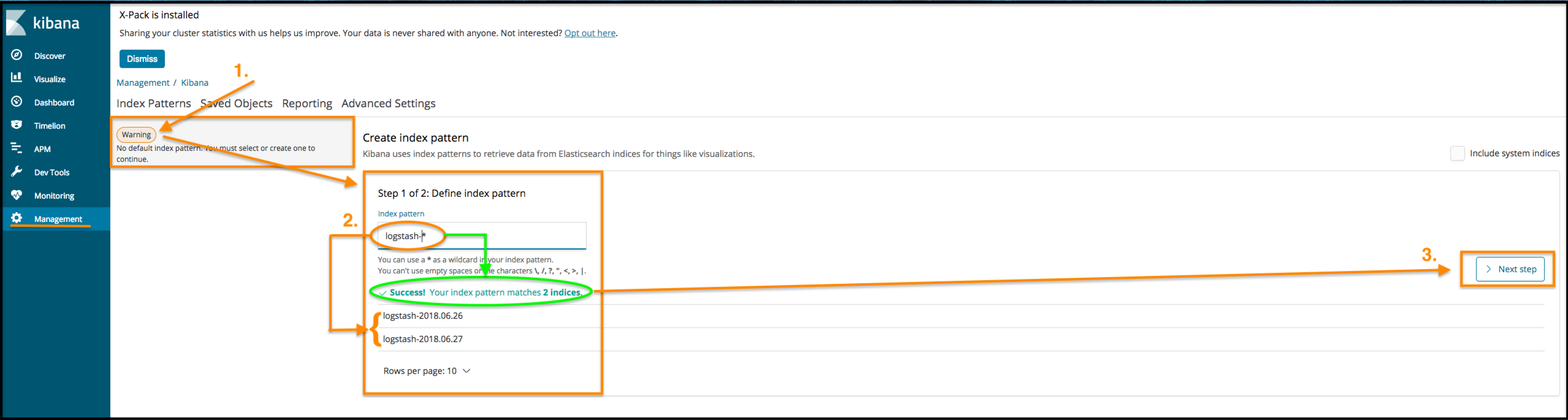 (Right-click with the mouse and select "View Image")
(Right-click with the mouse and select "View Image")
Finally, on the left navigation panel click on "Discover" in order to start see the logs being collected.
Here you can find the official getting started for Kibana.
When you will access Grafana for the first time, some basic configuration is required. As explained in the paragraph above, you will be initially requested to enter the username and password before attempting to do any setup. Once successfully logged in, then the primarily configuration is to add a so called "Data Source". Like we mentioned earlier, Grafana is a web dashboard for visualizing time series data collected by a data source (i.e. Prometheus in our specific case, but Grafana can work with several others).
The procedure is quite straightforward. On the Home you will be shown with a top panel suggesting first setup actions:
- Click on "Add data source" button. (Note: if you have already added a source, then such button will be labeled differently cause the action have been already completed once.)
- Enter an helpful and meaningful name for such source.
- Select "Prometheus" from the "Type" drop-down menu.
- Under the "HTTP" section, the "URL" field represents the source address from where data will be collected. Thus, enter your
prometheus-server's host IP (do not forget to placehttp://before, e.g.http://prometheus.34.244.118.105.nip.io). Regarding the field "Access", you can leave selected the default option (which at the current used version should be "Server(Default)"). - Next, under the "Auth" section select the "Basic Auth" checkbox. This will automatically make a new HTML section be visible, namely "Basic Auth Details".
- As expected, under the "Basic Auth Details" section enter the same pair of username and password that you would use to access the
prometheus-server's host (such pair can be found in theconfig.tfvarsfile). - Optionally, under the "Advanced HTTP Settings" section it is possible to define a global "scrape interval" for the HTTP GET requests (however can be tweaked later as well).
- Last but not least, click on the green button "Save & Test". If everything went well, you should see two green pop-up banners: one saying "Data Source added" and the other "Data source is working"
Once we made sure that a Data Source has been correctly added to Grafana, it is time to either create or import some dashboards. We definitely recommend to import some already existing ones specifically tailored for Kubernetes clusters. The ones we've found to be useful are the following IDs: 3131, 3119, 5303, 5327. These dashboards can be explored and retrieved at the following official URL: https://grafana.com/dashboards?search=Kubernetes . Nevertheless, the exercise of creating your own dashboard will certainly help with exploring Grafana's features.
In order to import an existing dashboard, please follow these steps:
- Hover with the mouse on the plus (+) button which is located on the top left-hand corner of the Web GUI.
- Select the entry "Import".
- At this point you could either: upload a .Json file, enter one of the official Grafana dashboard's URL or its ID, or paste a .Json file.
- Either way, remember to click on the blue "Load" button.
- If the dashboard has been correctly found, you should be displayed with some basic details about it, the options of renaming the fetched dashboard's and linking it to your Prometheus source (i.e in the related drop-down menu you should find listed at least one entry with the same name of the data source you have supposedly already setup. If not, then you have to create a data source otherwise a dashboard cannot be imported for it will not be fed with any metrics).
- Last but not least, click on the green button "Import" and you will be redirected to the new imported dashboard.
For both the aforementioned steps, we would like to recommend the following couple of video tutorials:
- Specifically about the procedures of adding a Data Source and import a Dashboard: https://youtu.be/jxNRXslYmrU?t=18m42s (NOTE: Web GUI is slightly older in such video, thus some differences will be noticed).
- The official Grafana's Youtube Screencasts playlist: https://www.youtube.com/playlist?list=PLDGkOdUX1Ujo3wHw9-z5Vo12YLqXRjzg2
As well as the official getting started for Grafana.
As stated at the beginning of this Wiki, logging and monitoring tools can help you understand what is happening inside your cluster, anticipate problems and discover bottlenecks. In order words, having a well equipped armory in order to deal with one of the oldest yet necessary IT ritual of all: debugging.
Let's image that something was wrong with one of the running dockerized applications. How could one look for logs specific to such docker container? Thanks to the EFK stack this should be "relatively" easy. Among the various features, Kibana allows to perform query in order to retrieve valuable info from the gathered logs.
By having Fluentd deployed as a DaemonSet which spawns a pod on each node that reads logs generated by kubelet, container runtime and containers installed, then among the available Fields one should most likely find many related to the Kubernetes environment of course. For example: kubernetes.namespace_name, kubernetes.pod_name, kubernetes.container_name, kubernetes.labels.app, kubernetes.hosts, etc...
NOTE: In order for Kibana to be able to visualize any logs generated by containers, it is assumed that the latter have been at least correctly started and have run for a while, otherwise no logs will be available.
Therefore, let's suppose for instance that we want to look for logs associated to the docker container related to the Galaxy application. By knowing its docker's name (which should be something like galaxy-k8s), we could then perform a simple query in Kibana in order to get all those logs which are a match. Once all the matches have been returned, by clicking on one of them you will see all the related details displayed in a more human readable fashion (i.e. a table). Nonetheless the original Json format is available as well. More often than not, a user debugging would be likely interested in messages of any kind which usually are represented by the value associated to the field "log": , as shown here:
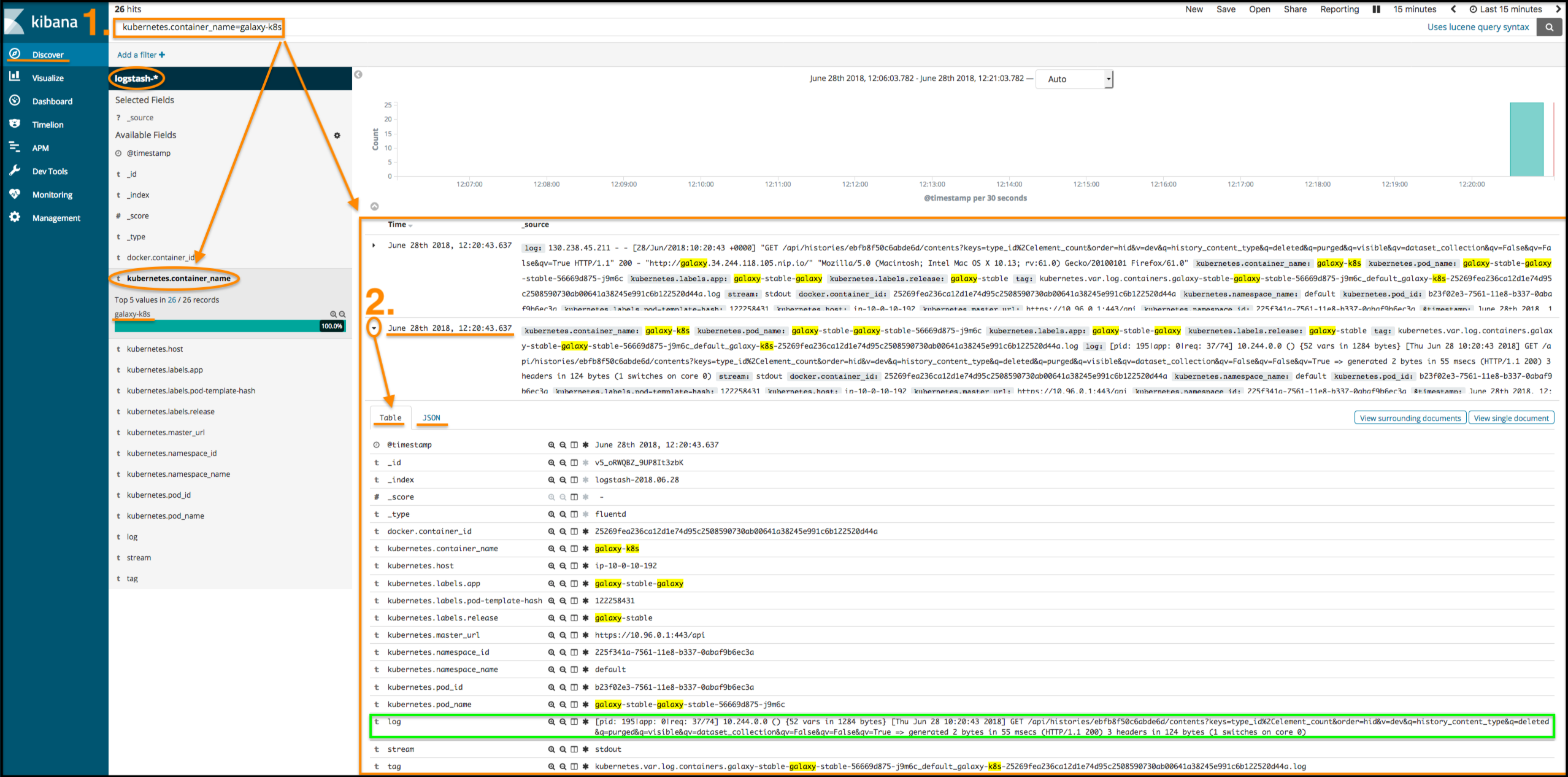 (Right-click with the mouse and select "View Image")
(Right-click with the mouse and select "View Image")
This is a good place where to start. However, an abundance of very useful information are gathered in such Kubernetes' logs, so it's definitely worthwhile to go through them in order to get a broader perspective for any cluster resources such as a pod, container, etc...
Last but not least, what about the monitoring tools? Grafana is essentially a visualization layer to display metrics stored in the Prometheus time-series database. Instead of writing queries directly into the Prometheus server, you use Grafana UI boards to query metrics from Prometheus server at an interval that you choose at the top-right corner of the Grafana Dashboard and displays them graphically in its Dashboard as a whole. The Grafana's community has developed some quite useful dashboard tailored for Kubernetes (whose IDs have been mentioned in the above section), e.g. to query metrics related to specifically pods, deployment and/or the all nodes.
Thence, let's imagine that something funky was going on with the Kibana's pod memory usage. Thanks to a tailored Grafana's dashboard (ID: 5327) that specifically fetches metrics about Kubernetes' pods, a user can filter by the namespace and/or pod's name to start gathering metrics about its memory usage for example:
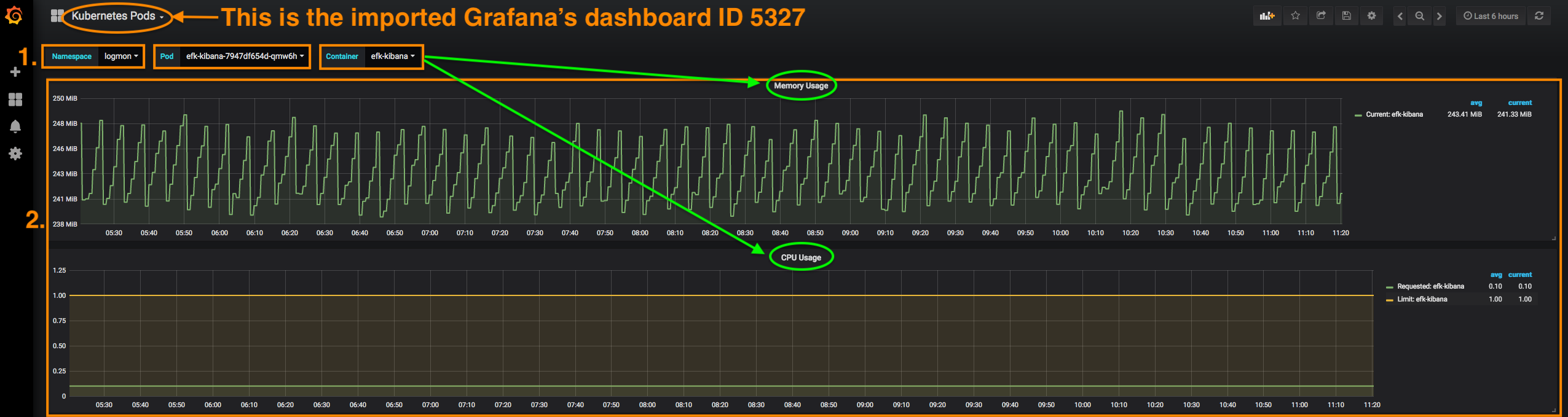 (Right-click with the mouse and select "View Image")
(Right-click with the mouse and select "View Image")
Same theory goes for CPU or disk usage, storage spikes, even application exceptions or simply put any important DevOps' practice and procedure. The features offered by the combination of tools such as Prometheus and Grafana are pretty ample.
For more advanced scenarios to be built with Kibana and Grafana, we recommend deep diving into their official documentations available at the following URLs:
| Funded by the EC Horizon 2020 programme, grant agreement number 654241 |
|---|
