
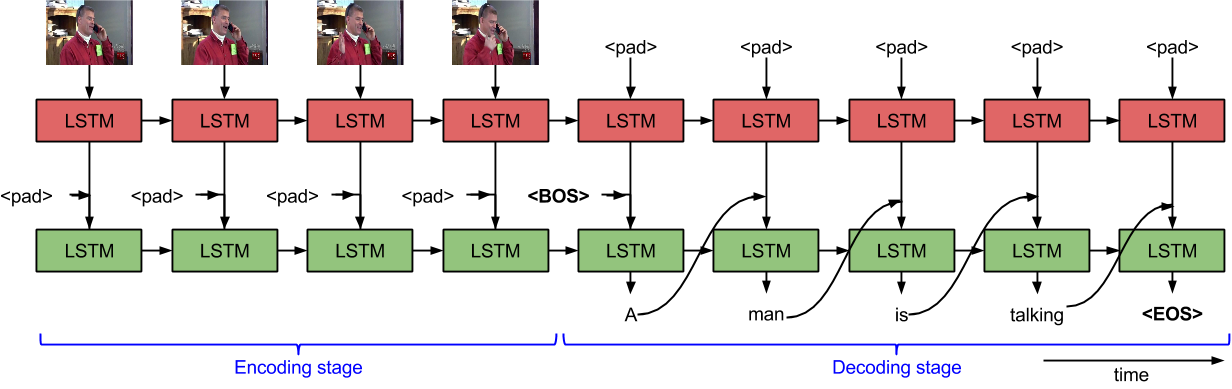
- This repository is an implement of an ICCV '15 paper Sequence to Sequence -- Video to Text in Tensorflow 1.0
| method | BLEU@1 score |
|---|---|
| seq2seq* | 0.28 |
*seq2seq is the reproduction of paper's model
pip install -r requirements.txt./run.sh data/testing_id.txt data/test_featuresfor details, run.sh needs two parameters
./run.sh <video_id_file> <path_to_video_features>- video_id_file
a txt file with video id
you can use data/testing_id.txt for convience
- path_to_video_features
a path contains video features, each video feature should be a *.npy file
take a look at data/test_features
you can use "data/test_features" directory for convience
pip install -r requirements.txt./train.sh./test.sh <path_to_model>- path_to_model
the path to trained model
type "models/model-2380" to use pre-trained model
- OS: CentOS Linux release 7.3.1611 (Core)
- CPU: Intel(R) Xeon(R) CPU E3-1230 v3 @ 3.30GHz
- GPU: GeForce GTX 1070 8GB
- Memory: 16GB DDR3
- Python3 (for data_parser.py) & Python2.7 (for others)
Po-Chih Huang / @pochih