Tutorial
DynaSOAr is a CUDA framework for a class of object-oriented programs that we call Single-Method Multiple-Objects (SMMO). In SMMO, parallelism is expressed by running the same method on all objects of a type. DynaSOAr optimizes the performance of SMMO applications by storing them in a Structure of Arrays (SOA) data layout.
DynaSOAr consists of three parts:
- A dynamic memory allocator that provides
new/delete-style functions for object allocation/deallocation in device code. - A data layout DSL that allows programmers to use OOP abstractions in CUDA while data is stored in an SOA layout under the hood. The DSL is based on Ikra-Cpp.
- A parallel do-all operation that assigns objects to GPU threads in such a way that most field accesses have good coalescing. This is the main source of speedup of DynaSOAr.
DynaSOAr is a collection of C++/CUDA header files. Programmers must include the main header file dynasoar.h and use the DynaSOAr API for defining classes etc.
DynaSOAr has a few software and hardware requirements:
- NVIDIA GPU with compute capability of at least 5.0.
- CUDA Toolkit 9.1 or greater. DynaSOAr may work with older versions, but we cannot confirm that. (Tested with CUDA Toolkit 9.1, 10.0, 10.1.)
- Boost library 1.70 or higher
- GCC host compiler. Edit
build_scripts/nvcc.shto specify a different host compiler. (Tested with GCC 5.4.0 and GCC 8.2.1.) - For graphical output: SDL 2 (Ubuntu APT packages:
libsdl2-2.0-0,libsdl2-dev) - For custom allocators (mallocMC): C++ Boost library
- 64-bit Linux operating system. (Tested on Ubuntu 16.04.4 LTS (kernel 4.4.0) and Arch Linux (kernel 5.0.2).)
We tested DynaSOAr on 3 different GPUs: NVIDIA Titan Xp, NVIDIA GeForce 940MX and NVIDIA GeForce GTX 1080 Ti.
Clone the git repository and initialize all submodules.
$ git clone https://github.com/prg-titech/dynasoar.git
$ cd dynasoar
$ git submodule init
$ git submodule updateMake sure that you can build and run the API example application.
$ build_scripts/sanity_check.sh
Built API example.
Check passed!
Ran API example. Done.If this fails, you may be missing some prerequisites. Make sure that the path to nvcc is set correctly in build_scripts/nvcc.sh.
We briefly explain DynaSOAr's API and data layout DSL.
Every DynaSOAr application must include the DynaSOAr header file.
#include "dynasoar.h"Now we have to define an allocator type (a template instantiation of SoaAllocator). To do this, we first have to pre-declare all C++ classes/structs that we want to use with the allocator.
class Foo;
class Bar;
using AllocatorT = SoaAllocator</*num_objs=*/ 262144, Foo, Bar>;The first template argument num_objs is the capacity (heap size) of the allocator. This is the number of objects of the smallest type that the allocator can allocate. E.g., if sizeof(Foo) < sizeof(Bar), then AllocatorT can allocate 262144 objects of type Foo; assuming that only Foo objects are allocated. The number of objects of type Bar that AllocatorT can allocate is smaller. The actual number of bytes that AllocatorT uses depends on num_objs and the size of the smallest type. Details are described in the paper. We will change this part of the API in future versions of DynaSOAr, so that programmers can specify the heap size in bytes.
Programmers interact with the allocator via two handles; one for device code and one for host code. These handles will be initialized in the main() function.
__device__ AllocatorT* device_allocator; // device side
AllocatorHandle<AllocatorT>* allocator_handle; // host side
Now it is time to define all classes/structs. Every class/struct must inherit from AllocatorT::Base or from a subclass of that class.
class Bar : public AllocatorT::Base {
/* ... */
};The first thing we have to do inside a class is to pre-declare all field types.
class Bar : public AllocatorT::Base {
public:
declare_field_types(Bar, Foo*, int, int)
/* ... */
};In this example, class Bar has three fields: The first field has type Foo* and the next two fields have type int. Note that fields must currently be sorted according to their size. E.g., sizeof(Foo*) > sizeof(int), so the Foo* field must come first. We will remove this requirement in future versions of DynaSOAr.
Finally, fields are declared with special proxy types.
class Bar : public AllocatorT::Base {
public:
declare_field_types(Bar, Foo*, int, int)
private:
Field<Bar, 0> the_first_field_;
Field<Bar, 1> the_second_field_;
Field<Bar, 2> the_third_field_;
};From now on, fields can be used like ordinary C++ fields.
class Bar : public AllocatorT::Base {
public:
delcare_field_types(Bar, Foo*, int, int)
private:
Field<Bar, 0> the_first_field_;
Field<Bar, 1> the_second_field_;
Field<Bar, 2> the_third_field_;
public:
__device__ Bar(int a, int b)
: the_first_field_(nullptr), the_second_field_(a), the_third_field_(b) {}
__device__ void increment_by_one() {
the_second_field_ += 1;
}
__device__ void increment_by_n(int n) {
the_second_field_ += n;
}
};When using fields, there are a few limitations with respect to automatic type deduction (e.g., auto keyword). Furthermore, an explicit typecast is required to printf fields:
__device__ void print_second() {
printf("Second value: %i\n", (int) the_second_field_);
}Now let us create a few objects in a CUDA kernel. Object are created with C++ placement-new syntax.
__global__ void create_objs() {
Bar* result = new(device_allocator) Bar(threadIdx.x, 5);
}Now let's put it all together and run a few parallel do-all operations.
int main(int argc, char** argv) {
// Some boilerplate code.... Create new allocator.
allocator_handle = new AllocatorHandle<AllocatorT>();
AllocatorT* dev_ptr = allocator_handle->device_pointer();
cudaMemcpyToSymbol(device_allocator, &dev_ptr, sizeof(AllocatorT*), 0,
cudaMemcpyHostToDevice);
// Allocate a few objects.
create_objs<<<5, 10>>>();
cudaDeviceSynchronize();
// Run a do-all operations in parallel.
allocator_handle->parallel_do<Bar, &Bar::increment_by_one>();
// If a member function takes an argument, we have to specify its type here.
allocator_handle->parallel_do<Bar, int, &Bar::increment_by_n>(/*n=*/ 10);
// Now print some stuff.
allocator_handle->parallel_do<Bar, &Bar::print_second>();
}What we showed here is only the most basic functionality. There is also a AllocatorT::device_do function for running a sequential for-each loop inside a CUDA kernel (see N-Body example). Moreover, every object has a cast<T>() method for type casting and type checks (see Barnes-Hut example; similar to C++ dynamic_cast). Objects are deleted with destroy(device_allocator, ptr). DynaSOAr also supports class inheritance and there is a special syntax for declaring classes as abstract (see Structure example).
The full source code of this tutorial is located in example/tutorial/tutorial.cu. Run the following commands to compile and run it.
$ build_scripts/build_tutorial.cu
$ bin/tutorialWe provide 10 benchmark applications that illustrate how DynaSOAr is used. Some of these applications have visualizations, which make it easier to analyze the effect of application parameters. In the following, we are building and running wator, a simple fish-and-sharks simulation in which fish and shark objects are dynamically allocated and destroyed.
All benchmark build scripts are located in the build_scripts directory and must be invoked from the DynaSOAr root directory. Before running the scripts, make sure that nvcc is available or set the correct path in build_scripts/nvcc.sh.
We analyze the wator benchmark in this section. The source code of this benchmark is located in the example/wa-tor directory. This benchmark has three/four classes: Agent, Fish, Shark (, Cell).
We compile wator as follows:
$ build_scripts/build_wa_tor.sh
Certain parameters such as the benchmark size or the allocator can be modified. (Check -? option.) We first take a look at the visualization to get a first impression of the benchmark.
$ build_scripts/build_wa_tor.sh -r -x 500 -y 500 -m 262144
$ bin/wator_dynasoar_no_cell
We provide four variants of wator:
-
wator_dynasoar: Runs with the selected allocator. (DynaSOAr unless overridden.) -
wator_dynasoar_no_cell: Same as above, butCellobjects are statically allocated since the cell structure does not change in the benchmark. This variant has only 3 classes instead of 4. We used this variant for our benchmarks. -
wator_baseline_aos: AOS baseline without any dynamic allocation. -
wator_baseline_soa: SOA baseline without any static allocation.
Now let us try to understand how dynamic allocation is used in this benchmark. Take a look at the header file example/wa-tor/dynasoar_no_cell/wator.h which defines the three classes Agent, Fish and Shark. When we build the benchmark in debug mode, we can see how DynaSOAr allocates objects.
$ build_scripts/build_wa_tor.sh -d -x 500 -y 500
$ bin/wator_dynasoar_no_cell
First, we get some information about our platform. We are running the benchmark on a GeForce 940MX at the moment.
Current Device Number: 0
Device name: GeForce 940MX
Memory Clock Rate (KHz): 1001000
Memory Bus Width (bits): 64
Peak Memory Bandwidth (GB/s): 16.016000
Total global memory: 2100.232192 MB
Available (free) global memory: 923.860992 MB
What follows is an overview of the memory usage of DynaSOAr.
┌───────────────────────────────────────────────────────────────────────┐
│ Smallest block type: 4Fish │
│ Max. #objects: 262144 │
│ Block size: 3904 bytes │
│ #Blocks: 4096 │
│ #Bitmap levels: 2 │
│ Data buffer size: 000015.250000 MB │
│ Allocator overead: 000000.114670 MB + block overhead │
│ Total memory usage: 000015.364670 MB │
└───────────────────────────────────────────────────────────────────────┘
We can see from here that:
- The smallest class in our system is
Fish. This is important because block capacities are determined by the size of the smallest type. (See paper.) - We configured the allocator such that it can allocate up to 262144 objects of the smallest type
Fish(-mcommand line argument). This number must be a multiple of 64. - The size of a block is 3904 bytes (see calculation later...).
- The heap consists of
262144 / 64 = 4096blocks. - The hierarchical bitmaps of this allocator (e.g., free block bitmap, allocated block bitmaps) have
ceil(log_64(4096)) = 2levels. - The size of all blocks is
3904 B * 4096 = 15.25 MiB. - The size of all block bitmaps is 0.115 MiB.
- The total memory usage of the allocator (including all of its allocations) is 15.4 MiB.
Note that the capacity/heap size of the allocator can currently not be specified in bytes. Instead, we specify the heap size via the number of objects of the smallest type in the system. We currently have to launch the program in debug mode to see how many bytes that equates to. (Or calculate it manually.) This is just a matter of the API and will change in future versions of DynaSOAr.
Now let us take a look at the classes in our application, starting with class Agent. This class is the first class that was passed as a template argument to SoaAllocator in the header file, so it has type ID 0.
┌───────────────────────────────────────────────────────────────────────┐
│ Block stats for 5Agent (type ID 0) │
├────────────────────┬──────────────────────────────────────────────────┤
│ #fields │ 3 │
│ #objects / block │ 64 │
│ block size │ 3648 bytes │
│ base class │ v │
│ is abstract │ 1 │
│ data seg. [64] sz │ 3584 bytes │
│ (unpadded) │ 3584 bytes │
│ (simple sz) │ 3584 bytes │
│ (padding waste) │ 0 bytes │
│ data seg. [ 1] sz │ 64 bytes │
│ (unpadded) │ 56 bytes │
│ data seg. [64] sz │ 3584 bytes │
│ (unpadded) │ 3584 bytes │
├────────────────────┴──────────────────────────────────────────────────┤
│ Fields │
├───────┬─────────────────┬───────────────────────┬──────────┬──────────┤
│ Index │ Def. Class │ Type │ Size │ Offset │
├───────┼─────────────────┼───────────────────────┼──────────┼──────────┤
│ 2 │ 5Agent │ i │ 4 │ 52 │
│ 1 │ 5Agent │ i │ 4 │ 48 │
│ 0 │ 5Agent │ 17curandStateXORWOW │ 48 │ 0 │
├───────┼─────────────────┼───────────────────────┼──────────┼──────────┤
│ Σ │ │ │ 56 │ │
└───────┴─────────────────┴───────────────────────┴──────────┴──────────┘
From here we can see that:
- The class has 3 fields: Two fields of type
int(i) and one field of typecurandStateXORWOW(defined ascurandState_tin the source code, provided by the cuRAND library). DynaSOAr is not aware of the inner layout ofcurandState_t. It is probably a struct with multiple fields, but we do not change its layout. This is future work. - The class is abstract. (See
static const bool kIsAbstract = true;in the header file.) - The block capacity (
#objects / block) has no meaning in abstract classes. - The class does not inherit from another class. (Base class
v=void.) - The size of the data segment is also not important for abstract classes.
The next two classes are non-abstract classes. Let us take a look at class Shark.
┌───────────────────────────────────────────────────────────────────────┐
│ Block stats for 5Shark (type ID 2) │
├────────────────────┬──────────────────────────────────────────────────┤
│ #fields │ 5 │
│ #objects / block │ 60 │
│ block size │ 3904 bytes │
│ base class │ 5Agent │
│ is abstract │ 0 │
│ data seg. [60] sz │ 3840 bytes │
│ (unpadded) │ 3840 bytes │
│ (simple sz) │ 3840 bytes │
│ (padding waste) │ 0 bytes │
│ data seg. [ 1] sz │ 64 bytes │
│ (unpadded) │ 64 bytes │
│ data seg. [64] sz │ 4096 bytes │
│ (unpadded) │ 4096 bytes │
├────────────────────┴──────────────────────────────────────────────────┤
│ Fields │
├───────┬─────────────────┬───────────────────────┬──────────┬──────────┤
│ Index │ Def. Class │ Type │ Size │ Offset │
├───────┼─────────────────┼───────────────────────┼──────────┼──────────┤
│ 1 │ 5Shark │ j │ 4 │ 60 │
│ 0 │ 5Shark │ j │ 4 │ 56 │
│ 2 │ 5Agent │ i │ 4 │ 52 │
│ 1 │ 5Agent │ i │ 4 │ 48 │
│ 0 │ 5Agent │ 17curandStateXORWOW │ 48 │ 0 │
├───────┼─────────────────┼───────────────────────┼──────────┼──────────┤
│ Σ │ │ │ 64 │ │
└───────┴─────────────────┴───────────────────────┴──────────┴──────────┘
This class inherits from Agent, so its fields are repeated in here. The capacity of blocks of type Shark is 60. This is calculcated as follows (also see paper):
The capacity of the smallest type in the system, Fish in this example, is always 64. The size of a Fish object is 60 bytes, so the size of a block is 60 B * 64 = 3840 B. The size of a Shark object is 64 bytes, so the number of Shark objects in a block is 3840 B / 64 B = 60. Sometimes, this computation is more complicated due to padding of SOA arrays.
Finally, we can see some statistics about the state of the allocator. The benchmark code prints statistics after every iteration when built in debug mode. Note that this slows down the allocator significantly, so do not use debug mode (or rendering) when measuring performance.
┌────┬──────────┬──────────┬──────────┬┬──────────┬──────────┬──────────┐
│ Ty │ #B_alloc │ #B_leq50 │ #B_activ ││ #O_alloc │ #O_used │ O_frag │
├────┼──────────┼──────────┼──────────┼┼──────────┼──────────┼──────────┤
│ fr │ 1320 │ n/a │ n/a ││ n/a │ n/a │ n/a │
│ 0 │ 0 │ 0 │ 0 ││ 0 │ 0 │ 0.000000 │
│ 1 │ 2224 │ 0 │ 2141 ││ 142336 │ 133631 │ 0.061158 │
│ 2 │ 552 │ 0 │ 411 ││ 33120 │ 12478 │ 0.623249 │
│ Σ │ 2776 │ 0 │ 2552 ││ 175456 │ 146109 │ 0.167261 │
└────┴──────────┴──────────┴──────────┴┴──────────┴──────────┴──────────┘
We can read these statistics as follows.
- The
frline shows the number of blocks that arefree(not allocated). There were 1320 free blocks in this particular iteration. - There is one line for every type. The number in the first column is the type ID (
0=Agent,1=Fish,2=Shark). -
B_allocis the number of allocated blocks,B_activeis the number of active blocks,O_allocis the number of allocated object slots (all object slots of allocated blocks) andO_usedis the number of object slots that actually contain an object. We can calculate the fragmentation from the last two values as defined in the paper:(O_alloc - O_used) / O_alloc. - There are no objects of abstract classes, so all values for class
Agentare0.
If we watch these statistics for a while, we see that the fragmentation rate is pretty high around iterations 60-80. Sometimes over 80%. We can see this fragmentation spike in the Wa-Tor figures in the paper.
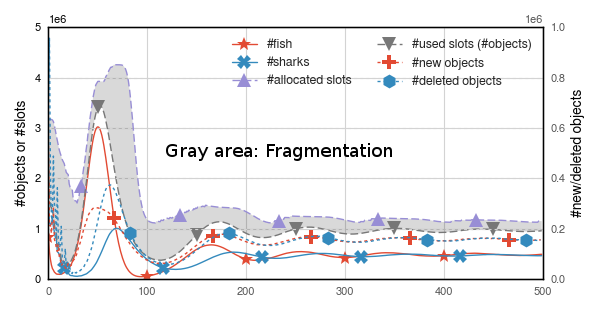
Now let us compare the performance of DynaSOAr and mallocMC.
$ build_scripts/build_wa_tor.sh -x 300 -y 300 -a dynasoar -m 262144
$ bin/wator_dynasoar_no_cell
634949, 159514
$ build_scripts/build_wa_tor.sh -x 300 -y 300 -a mallocmc -m 262144 -s 536870912
$ bin/wator_dynasoar_no_cell
2123027, 1344489
Note that for custom allocators (other than dyansoar), the heap size in bytes can be specified in addition to the maximum number of objects with the -s parameter. Custom allocators may then use that amount of memory. The -m parameter determines the size of the auxiliary data structures that implement parallel enumeration of custom allocators.
We ran the benchmark with a very small problem size. If no problem size is specified, the default problem size (used in the paper) is selected. The first number is the overall benchmark running time. The second number is the time spent on parallel enumeration. We should substract this number from the first one to allow for a fair comparison (see paper).
Not taking into account enumeration time, the benchmark finishes in 634949 - 159514 = 475435 microseconds (0.475s) with DynaSOAr. With mallocMC, the benchmark runs for 2123027 - 1344489 = 778538 microseconds (0.779s). We can repeat this experiment with other allocators (bitmap, cuda, halloc). When running larger problem sizes, keep in mind that the CUDA allocator is very slow, so it may run for a long time.
If we increase the problem size, it may also be necessary to increase the heap size -s (and/or the max. number of objects -m) to ensure that the allocator does not run out of memory. If DynaSOAr runs out of memory, it currently goes into an infinite loop (see algorithm in the paper). If the other allocators run out of memory, the program usually crashes.