A simple distributed bank management system which uses Zookeeper to ensure consistency, availability and fault tolerance.
The aim of this project is to create a simple distributed bank system made of application servers connected to a Zookeeper ensemble (or standalone if locally). Client requests (in this case STDIN commands) can be sent to any application server. In case the request is sent to the leader elected amongst the application servers, the request is processed by that server and forwarded to all the other applications servers. In case of a request sent to a non-leader application server, however, there are 2 cases: read requests are processed by the application server itself; create, update and delete requests are forwarded to the application server leader, which processes it and, when terminated, forwards them to all the other application servers.
This project depends on 3 libraries:
These dependecies can be downloaded and imported manually into the project (e.g. for development).
To enable the functionalities provided by the application servers, a Zookeeper Ensemble (or Standalone if in localhost) need to be started. For the standalone version we only need to start the Zookeeper server, which can be achieved running the zkServer.sh script which can be found inside the uncompressed jar, under the /bin folder (/zookeeper-3.4.10/bin/zkServer.sh). The standalone will use the default configuration file (/zookeeper-3.4.10/conf/zoo.cfg). To achieve the same result for an Ensemble, create different configurations file and edit the clientPort attribute.
The ensemble also provides a CLI (/zookeeper-3.4.10/bin/zkCli.sh) which can be used to manage the Zookeeper structure (see Znodes, read data, delete nodes, etc.).
The application servers are really simple Java applications. The database is made of a HashMap data structures, which stores information abour customers (account id, owner and current balance). The set of operations provided by the application are the standard CRUD (Creata, Read, Update, Delete).
The application can be run from the command line, providing a basic UI which allows to execute the above-mentioned operations.
Communications never happen directly between application servers. Each of the application server is connected to a Zookeper ensemble which functions like a service bus.
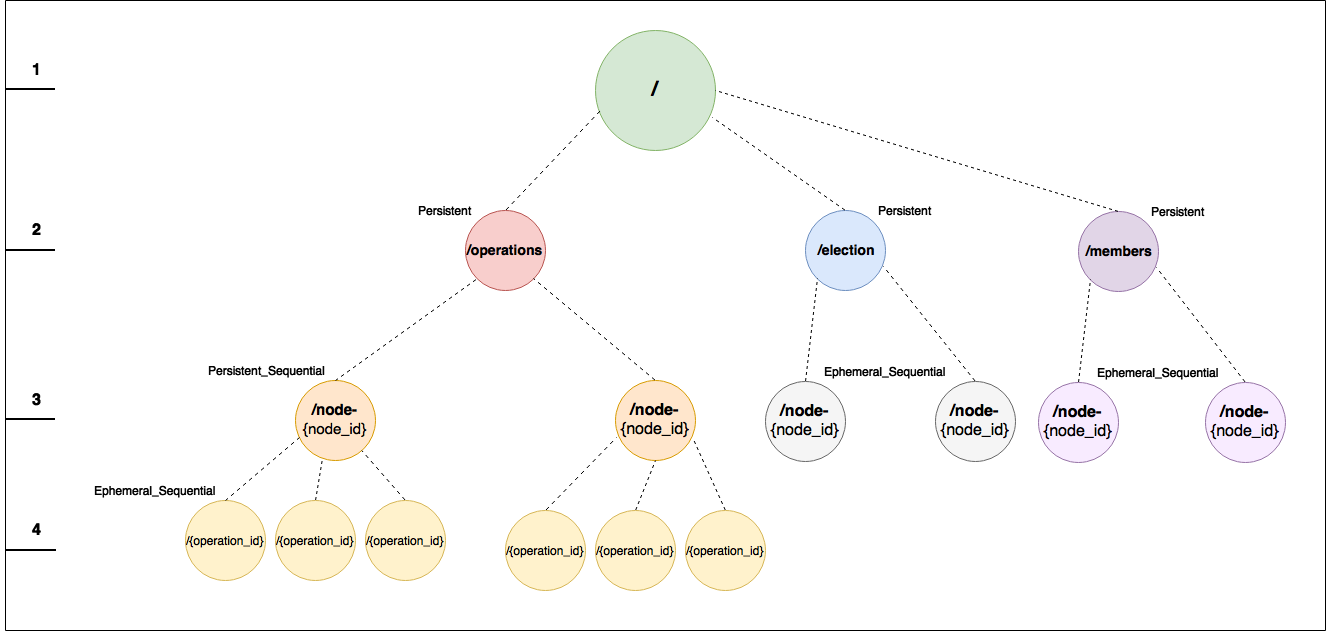
In the above image it can be seen the structure of the Zookeeper ensemble. Under the root node "/" (1) several nodes are created (2): an election node, a members node and an operation node. All of these nodes are PERSISTENT, meaning that they are not associated with the current session and, therefore, are never deleted.
The Election node is used to register all the application servers which are part of the cluster. Everytime a new application server is started, an EPHEMERAL_SEQUENTIAL (3) node is created under the root election node (/election). This mechanism enable to perform operations such as Leader election amongst all the nodes.
The algorithm used for choosing the leader amongst all the application servers is very simple: the node with the lowest id will be elected as leader.
The Members node is used to enforce Fault Detection. As previously described for the Election Node, everytime that an application server joins the cluster, an EPHEMERAL_SEQUENTIAL (3) node is created under the members node (/members). Everytime that a new member joins the Members node, a watch that check its existance is set. This watch will be triggered if/when the node goes down (either crashed, or gets stopped). The watcher process is responsible for starting a new application server, thus ensuring fault detection and automatic recovery.
The Operations node is used to enforce the consistency of the cluster. As above, everytime that an application server joins the cluster, a PERSISTENT_SEQUENTIAL (3) node is created under the operations node (/operation). This node is set to be PERSISTENT because numerous sub-nodes (4) will be created under each application server operation's node, one for each operation to be executed.
To achieve consistency, in fact, all the application servers need to execute the same set of operations.
The strategy for ensuring consistency is as follow:
- Read operations: when a read operation is sent to any node (being it a leader node or a simple node), it is processed by the node itself;
- Write operations: when a write operation is received by an application server, we distinguish two cases:
- the operation is received by the leader: the application server executes it and forwards it to all the other nodes;
- the operation is received by a non leader node: the operation is forwarded from this node to the leader, which will execute it and, then, forward it to all the other nodes.
N.B.: Even though the /members and /elections znodes could be merged into a single node, for the purpose of this assignment and for the separation of concerns (=easier understanding of what's going on under the hood), I preferred to keep them separated.
The aim of this assignment was not to develop a complex application, but rather to enforce consistency, availability and fault-tolerance amongst all the applications of a cluster. For this purpose, Zookeper came in hand providing a mean for these operations. Znodes and watches, in fact, enabled to achieve the above-mentioned goals in a straightforward way, simply by waiting for changes in the Zookeeper Ensemble Znodes structure.