How To Build An Online Dating Site, Part 2
This is part 2 in a series about the architecture of Similarity.com. For a general overview, see How To Build An Online Dating Site, Part 1.
Like a lot of people building websites today, I emerged from the 2000s with a lot of experience building applications using the "traditional web stack": Some sort of web server that accepts HTTP requests, issues SQL queries to an RDBMS, and returns the results as formatted HTML. Starting in university and proceeding throughout my career, I learned the "correct" way to model data structures and query them with relational algebra.
Ten years ago, if you asked me to model an online dating site with people, answers to questions, freeform essays, etc, I would have built an attractive, normalized structure like this:
CREATE TABLE person (
id INT PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255),
first_login TIMESTAMP,
last_login TIMESTAMP,
birth DATE,
sex CHAR(1),
orientation CHAR(1));CREATE TABLE like (
id INT PRIMARY KEY,
person_id INT,
like_id INT,
value INT);CREATE TABLE essay_question (
id INT PRIMARY KEY,
question VARCHAR(255));CREATE TABLE essay_answer (
id INT PRIMARY KEY,
person_id INT,
question_id INT,
answer VARCHAR(4096));In fact, back in 2001 I built and launched an early version of Similarity that had a structure almost exactly like this. It worked just fine... for all 75 people that ever logged into the site.
In retrospect, if I ever had real traffic, this schema would not have performed. It requires 3-4 queries just to fetch a single profile. Rendering 50 match results might have required hundreds of queries. Enough caching, database replication, and clever query optimization might have made this work at scale... but I'd rather spend my time implementing new features.
This is, I think, what is driving the development of NoSQL databases. The load requirements of a modern mass-consumer web application are so severe that traditional database modeling falls apart; there's so much denormalization and hackery required that your system stops looking like an RDBMS. In fact, if you examine how Facebook has evolved their MySQL system, you will notice they've abandoned the relational pretense entirely:
- The database is a key-value store federated across thousands of instances.
- Values are schemaless serialized blobs.
- There are no joins, no transactions across entities.
Lo and behold, this is almost exactly what NoSQL databases like MongoDB and the Google App Engine datastore are like. The terrific flexibility of having a schemaless, blob-like data structure means you can elegantly denormalize your data into chunks that are optimal for your queries.
For example, when Similarity renders a set of 50 match results, it needs almost all the stored information for 51 users (the matches + you). The optimum chunk size for this query is "all the data for a single user".
The sequence diagram for every match request looks like this:
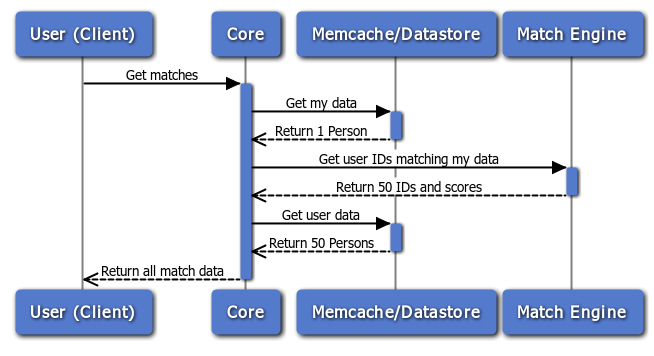
Since the match engine simply returns IDs, the Core must fetch Person objects for each of the 50 match results from the datastore. This is fast because the data is often retrieved from memcache and cache misses are parallelized in the datastore.
Thus we arrive of what the Similarity schema for a user actually looks like. Here is an excerpt of the Person class. This Java code completely defines the datastore "schema" - there is no DDL. The annotations are from Objectify but a nearly identical set of annotations would be appropriate for MongoDB/Morphia[1].
@Unindexed
@Cached
public class Person {
@Id
long id;
String firstName;
String name;
String email;
Date firstLogin;
Date lastLogin;
java.sql.Date birth;
Sex sex;
Orientation orientation;
/** The things the user has liked and how much they liked it. */
@Serialized
@NotSaved(IfEmpty.class)
Map<long likevalue> likes = new LinkedHashMap<long likevalue>();
/** Map of question text to answer text */
@Serialized
@NotSaved(IfEmpty.class)
LinkedHashMap<string string> freeForms = new LinkedHashMap<string string>();
/** Ordinal index of the last change that affects the match engine. */
@Indexed
@NotSaved(IfNull.class)
Long change;
}This heavily-denormalized approach also has performance benefits when populating the match engine. Remember from Part 1 that match instances are "slaved" to the master datastore, polling periodically for changed user records. A single query can efficiently obtain all the information necessary:
Query<person> people = ofy.query(Person.class)
.filter("change >=", startingAtChange)
.order("change")
.limit(maxCount);Even in the event of catastrophic simultaneous failure of all match nodes, a fresh node can repopulate itself from the master source at many thousands of user records per second.
On the Objectify mailing list, people often ask questions like "I have students and professors and exams, how should I model them?" In a relational world, this would be a meaningful question, but it doesn't make sense in the world of NoSQL. There is no canonical schema anymore. Instead you should ask: What high-volume queries will I need to serve with my data? Then work backwards from there.
[1] - Scott Hernandez, who maintains the Morphia driver for MongoDB, was an early collaborator on Objectify. We have tried to maintain a consistent set of annotations where appropriate.
