How To Build An Online Dating Site, Part 1
I can't tell you exactly how you should build your online dating site, but I can tell you how I built mine. This is the first in a series of articles describing the innermost workings of Similarity.
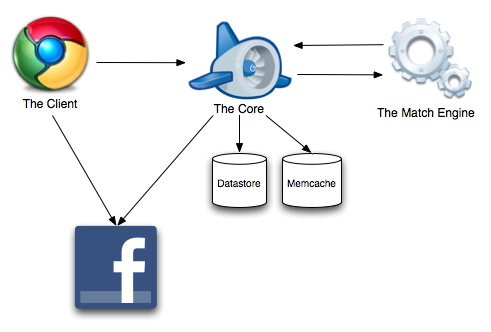
Similarity has three major components:
This is the part that users interact with. It is a single-page web application built using Google Web Toolkit. About 20,000 lines of Java code get compiled into a 500k chunk of optimized Javascript that is downloaded to your browser the first time you visit www.similarity.com. Unlike traditional web applications which generate HTML pages, the Similarity client is constructed like a traditional rich client application - widgets, panels, layouts, events, etc. When you interact with the client, it communicates with the Similarity backend servers using GWT-RPC.
Aside from GWT, the client relies on:
- Google Gin, a dependency injection framework for GWT.
- Google Chart Tools to draw various pie and bar charts.
- Sass, "syntactically awesome stylesheets". This is a dramatic improvement over plain old CSS.
The client also makes calls directly to Facebook using Facebook's Javascript SDK. For example, to perform authentication and to offload some processing that would otherwise need to happen at the backend.
I chose to build a single-page javascript-only frontend rather than a traditional page-centric HTML app because I wanted the kind of interactivity that desktop applications provide. The countless knobs, levers, and states are easily maintained by a GWT client, whereas the principal advantage of an HTML application, crawlability, is irrelevant to a dating site. Users don't want their profiles in search engines.
About 70% of the effort of building Similarity went into this component. User interfaces are hard.
This is the bulk of server-side logic, serving up the client app to web browsers and answering RPC requests from the client. The Core is ~10,000 lines of Java code running on Google App Engine, which automatically spins up as many appserver instances as necessary to meet load. All data is stored in a NoSQL store based on Google's BigTable, in a structure that looks alien to developers familiar with traditional RDBMS development (more on this the next post).
The Core uses several pieces of opensource technology:
- Objectify-Appengine, an alternative programming interface to the App Engine datastore. It allows developers to work with Java classes (similar to JPA or JDO) but provides much lower-level access to the performance-enhancing features of the datastore.[1]
- BatchFB, a Java interface to Facebook's API. It automatically batches multiple requests together into a minimum number of requests and runs them concurrently to radically reduce the length of time a user has to wait for a response.[1]
- Google Guice, a dependency injection framework.
The Similarity core is relatively simple because all access is through a well-defined RPC interface. It knows how to synchronize your profile with Facebook. It knows how to update data you change in the client. It knows how to compare specific users and provide a match score. It knows how to query the match engine and translate the response into a set of results to the client. It provides a layer of security and user access control. Most importantly, it knows how to do all this efficiently (in terms of wall-clock time and $$) by making use of App Engine's memcache service and asynchronous task queue.
This is a specialized in-memory index that can answer arbitrary matching queries. It is used only for fetching a list of match results. It maintains a nearly complete copy of the parts of the user database that are relevant to matching - age, sex, location, orientation, likes/dislikes, etc.
The match engine is a simple Java WAR application (~1,000 lines of code) that is replicated across multiple VPS servers "elsewhere in the cloud". It has no persistence; each instance stores the entire active dataset in RAM. It is CPU intensive, but the number of match engines can be scaled up to meet load requirements.
The core and the match engine communicate using Hessian, an RPC protocol that works reasonably well with App Engine. The communication is bidirectional:
- Every few minutes, the match engine calls to the core to get changed data.
- When executing a search, the core calls to a match engine instance.
Conceptually, you can imagine a match engine instance "slaved" to the core dataset much as a MySQL instance is slaved to another server. When a user changes their matchable data (say, by liking something) a monotonically increasing change# is updated in the user record. Match engine instances simply fetch data more recent than the last change# they have seen.
The difficulty of this system manifests when it becomes necessary to reboot or upgrade the match engine software; simply bouncing an instance might require many minutes to transfer gigabytes of match data from GAE. To address this issue, match engine instances are broken into two clusters, a "red group" and a "blue group". At boot, a red instance "side-loads" itself from the blue group before feeding from the Core; a blue instance first goes to the red group. This transfer is memory-network-memory and extremely fast. As long as both clusters are not bounced at the same time, match engine availability will not degrade.
This architecture makes it possible to scale Similarity to tens of millions of users almost entirely unattended. Google App Engine will scale the Core to as many appserver instances as necessary to service load; the GAE datastore provides constant performance for effectively unlimited data; the match engine will replicate itself to as many instances as necessary to maintain performance.
The total cost to operate this system today, in "bootstrap mode" (still a small dataset): $43.50/month.
- $32.50/month for UserVoice Full Service (on the 1/2 price startup plan)
- $11/month for a single 256MB Rackspace Cloud VPS running one instance of the match engine.[2]
- Existing traffic fits within Google App Engine's generous free quota.
In the next post, I will describe the key elements of Similarity's data model and how the unique properties of a NoSQL datastore make searches work efficiently. Code samples will be included!
[1] - I wrote and published these projects - Objectify in the course of developing Mobcast and BatchFB in the course of developing Similarity. Enjoy!
[2] - Autoscaling of the match engine requires AWS Elastic Beanstalk (or an equivalent loadbalanced system), but the minimum monthly fee is $37 and I'm cheap. For now, Rackspace Cloud is fine - and it's possible to run the red/blue clusters at entirely different hosts.
