{kind=link}
{kind=link}
{kind=link}
For this final project, we wanted to train a model that could successfully classify songs into different genres. To do this, we tried six different convolutional neural network architectures, including ResNet18, AlexNet, VGG-11-BN, SqueezeNet, DenseNet, and Inception v3. We trained on the GTZAN dataset, which contains 1000 songs classified into 10 different genres, as well as the small version of the FMA dataset, which contains 8000 songs classified into 8 different genres. We evaluated our performance by splitting the datasets into training and validation sets for GTZAN, and into training, validation, and test sets for FMA. Our models achieved a 66.5% validation accuracy on music genre classification using the GTZAN dataset and a 53.4% test accuracy on music genre classification using the small version of the FMA dataset.
The advent of online music streaming has caused an increased interest in the classification of songs into their respective musical genres. Music genre classification is something that usually must be done manually, which can be very time consuming for large music streaming brands such as Spotify, which in 2022 hosts over 80 million tracks and has over 400 million users. By creating a model that can accurately classify music into genres, users will be able to find music more readily in genres that they love, as well as to receive better recommendations for music in genres that they might not have explored yet.
A 2011 survey paper from Fu et al. on audio-based music classification and annotation found that most existing methods of music classification at the time used a pipeline consisting of feature extraction and classifier learning. These methods relied on manual feature engineering to represent certain characteristics of the audio, and did not have the ability to learn complex patterns in the data.
In recent years, there has been a growing interest in using deep learning methods for this task, with convolutional neural networks (CNNs) being the most widely used approach. CNNs have the ability to learn hierarchical representations of the data, allowing them to capture complex patterns and achieve better performance than traditional machine learning methods for music genre classification. A typical approach is to convert the audio data to a spectrogram, which is a visual representation of signal frequencies over time, then feed the spectrograms into the convolutional neural network.
The GTZAN dataset is one of the most commonly used datasets for training and evaluating musical genre classification models. It was created in 2001, and consists of 1,000 audio tracks from 10 different musical genres: blues, classical, country, disco, hip hop, jazz, metal, pop, reggae, and rock. Each genre has 100 audio tracks that are each 30 seconds long.
The FMA dataset is a more recent dataset created in 2017 that is used for training and evaluating musical genre classification models. It is much larger, containing 106,574 tracks from 16,341 different artists, classified into 161 genres. The full dataset can be prohibitively large for some purposes, so it is provisioned into four different sizes that can be downloaded. The small version has 8,000 tracks classified into 8 genres.
To tackle the problem of music genre classification, we first trained a CNN on the GTZAN dataset. The input to the model was a spectrogram representation of the audio data, which encodes the frequency and time information in the audio. We tried several common CNN architectures, including ResNet18, AlexNet, VGG-11-BN, SqueezeNet, DenseNet, and Inception v3. The best CNN architecture trained on GTZAN was DenseNet, which achieved a validation accuracy of approximately 72%.
Because GTZAN is relatively small at 1000 songs, we wanted to try training on a larger, more robust dataset. The next dataset we used was the small version of FMA, which contains 8000 songs, and is more recent. Because of the formatting of the FMA dataset, we had to do a lot of data preprocessing. The FMA dataset states that the small version has eight genres, but the genre names are not given, so we had to perform some data analysis on the full dataset’s metadata using pandas to find the names of the genres. We also needed the mp3 files to be organized into a training, validation, and test set, and organized into each of the eight genres within each of those folders, so we wrote scripts to organize the mp3 files into the right folders.
To evaluate the performance of our model, we first trained it on the training set and then tested it on the test set. Because the GTZAN dataset does not contain a test set, we used a training/validation split of the GTZAN dataset with 80% of the data used for training and 20% used for validation. For the FMA dataset, we used a train/validation/test split with 80% of the data used for training, 10% used for validation, and 10% used for testing.
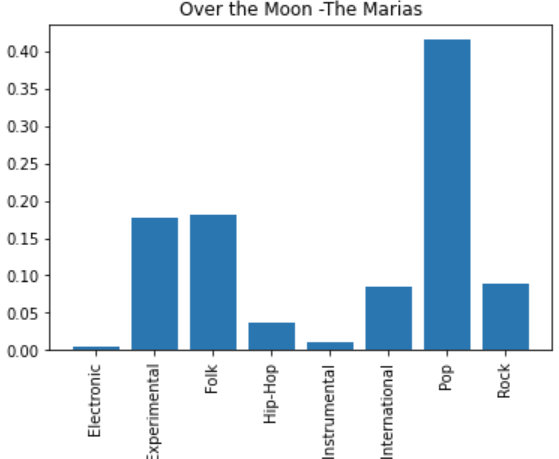
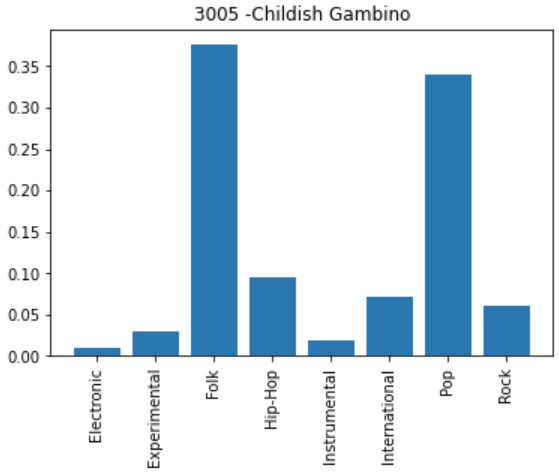
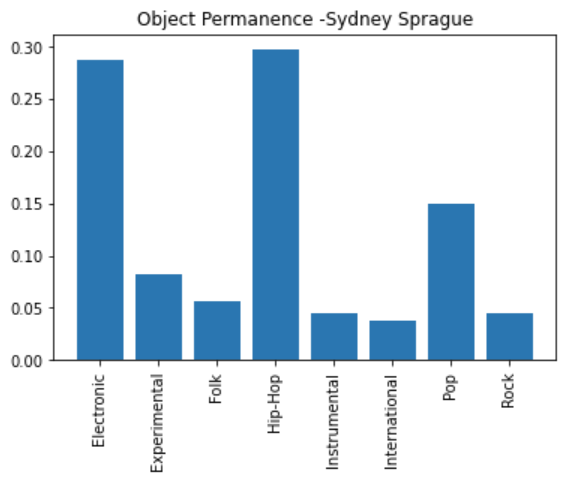
We also tested our final model on our group’s personal music listening data. We compiled a 20-song dataset consisting of the top 5 songs that each of us listened to in 2022 on Spotify. We then trimmed each song down to the first 30 seconds, converted each trimmed mp3 into a spectrogram image, then classified each song’s genre using our model.
GTZAN — Final Validation Accuracy: 66.5%

FMA — Final Test Accuracy: 53.4%
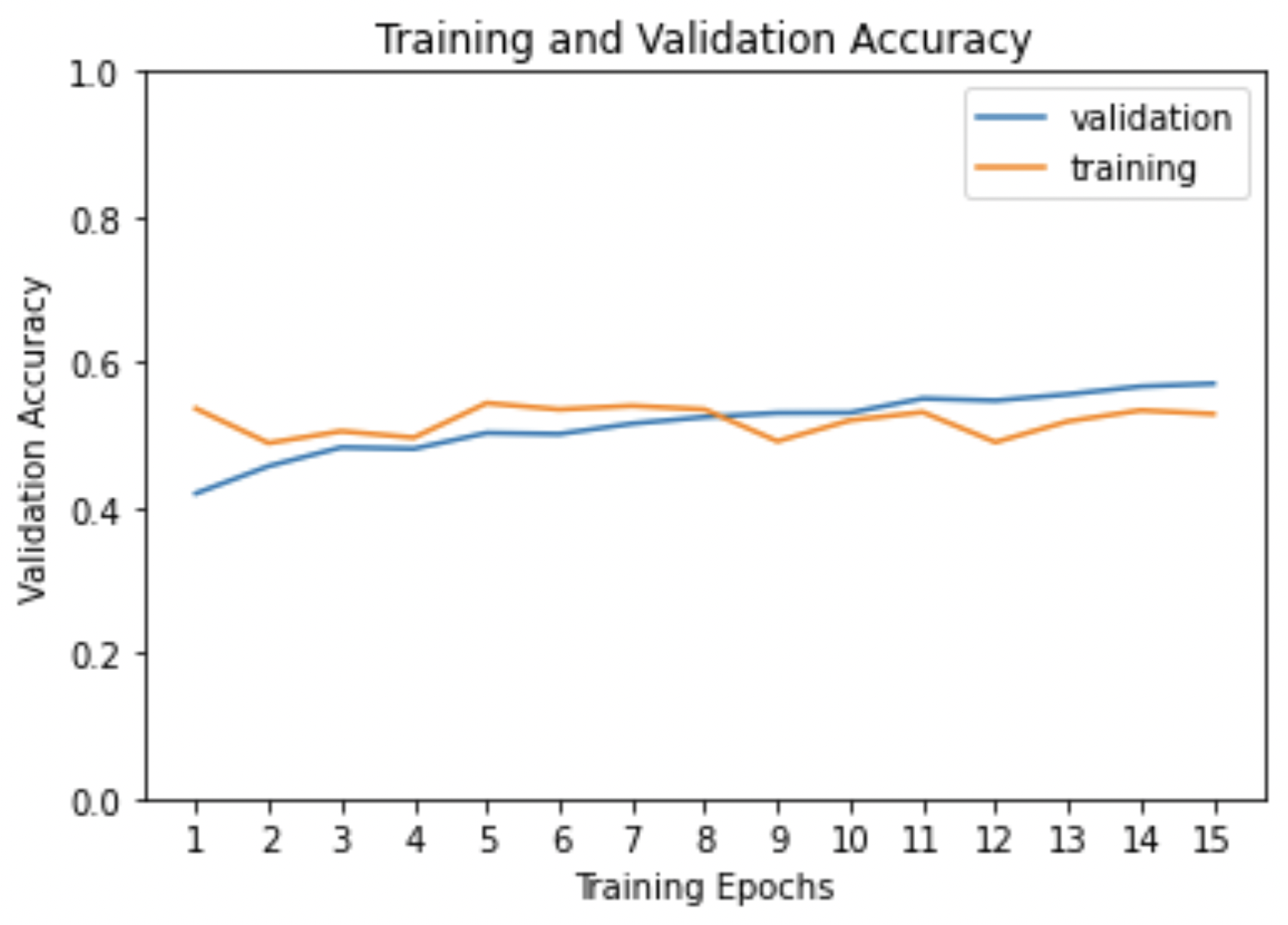
FMA Confusion Matrix